Invented by Lalitesh Katragadda, Google LLC
Automatically completing data input refers to the use of advanced technologies, such as artificial intelligence (AI) and machine learning, to automate the process of entering data into various systems. This technology has gained significant traction in recent years, as businesses strive to streamline their operations and improve overall efficiency.
One of the key benefits of automatically completing data input is the significant reduction in time and effort required. With manual data input, employees spend countless hours typing, copying, and pasting information. This not only leads to a slower workflow but also increases the chances of errors. By automating this process, businesses can save valuable time and resources, allowing employees to focus on more important tasks.
Moreover, automatically completing data input can greatly enhance accuracy. Human errors are inevitable, especially when dealing with large amounts of data. Mistakes in data input can lead to costly consequences, such as incorrect customer information, faulty financial records, or inaccurate inventory management. By leveraging AI and machine learning algorithms, businesses can ensure that data is entered accurately and consistently, minimizing the risk of errors.
Another advantage of automatically completing data input is the ability to handle complex data formats. In many industries, data comes in various formats, such as spreadsheets, PDFs, or handwritten forms. Manually inputting data from these formats can be time-consuming and error-prone. However, with advanced technologies, data can be extracted and entered automatically, regardless of the format. This not only saves time but also ensures that data is captured accurately, regardless of its source.
Furthermore, automatically completing data input can lead to improved data quality and integrity. AI algorithms can detect and correct inconsistencies, duplicates, or missing information, ensuring that the data entered is reliable and up-to-date. This is particularly important for businesses that rely on accurate data for decision-making, such as financial institutions, healthcare providers, or marketing agencies.
The market for automatically completing data input is rapidly growing, driven by the increasing demand for efficiency and accuracy in data-driven industries. Many software providers and technology companies are developing innovative solutions to automate data input processes. These solutions often integrate with existing systems, making it seamless for businesses to adopt and implement.
However, it is important to note that while automatically completing data input offers numerous benefits, it is not a one-size-fits-all solution. Different industries and businesses have unique data input requirements, and it is crucial to choose a solution that aligns with specific needs. Additionally, businesses must ensure that data privacy and security measures are in place to protect sensitive information.
In conclusion, the market for automatically completing data input is revolutionizing the way businesses handle and process data. By leveraging advanced technologies, businesses can save time, improve accuracy, and enhance overall efficiency. As the demand for data-driven insights continues to grow, the importance of automating data input processes will only increase.
The Google LLC invention works as follows
Techniques for automatically generating personal data are disclosed. These include an address book, financial portfolios, discussion groups, blogs, or any other type of personal data store, all based on structured search data or usage data of a user (e.g. browsing), or from other sources (e.g. emails received by the user). Metadata can be used to generate and/or maintain the personal data. “Autocomplete and dynamic personal data ranking functions can also be used to ease the burden of managing or handling personal data.
Background for Automatically completing a data input
The person who is responsible for the data will typically perform this process manually. Take, for instance, the address book of a person.
An addressbook is a collection that contains contact information, such as the address (home or office), phone number (home or office), fax number, email address, etc. The contact information is stored in most address book systems alphabetically, according to the last name of each contact. In the past, address books were created on paper. Some address books are loose-leaf bound to make it easier to update the book as contacts change.
Many people keep their address book using electronic organizers, or software-based addresses books. This eliminates many of the issues associated with paper-based books. These address books are used in many e-mail programs. Personal information manager systems (PIMs) are also available, which integrate various common features such as an email address book, a personal calendar, or schedule, or a timeline with action items to be completed.
The electronic address book is very portable because it can be synchronized between devices, e.g. between a desktop computer and a personal digital assistant. Individual entries from an electronic address can also be transferred, such as vCards, to simplify the exchange of contact details.
In any case, an electronic address book contains a collection of dynamic data. This address book requires a lot of maintenance as new contacts are added or existing contacts’ details change. This maintenance is currently done manually, as required, by the owner. This maintenance is time-consuming, tedious, and the process to access a specific address (such as searching for an address in the list of many addresses and clicking) is cumbersome.
Other forms of dynamically-changing personal data are also linked to such problems. Consider a person?s stock portfolio. This portfolio will need to be updated when there are changes, such as when a trade is made (e.g. purchase of additional stock, or new shares, or stock sale), or when certain information becomes available about the target company.
What is required, then, are techniques that automatically generate and maintain address books. There is a general need to automatically generate and maintain personal data and make it useful for the user, with little or no effort from the user.
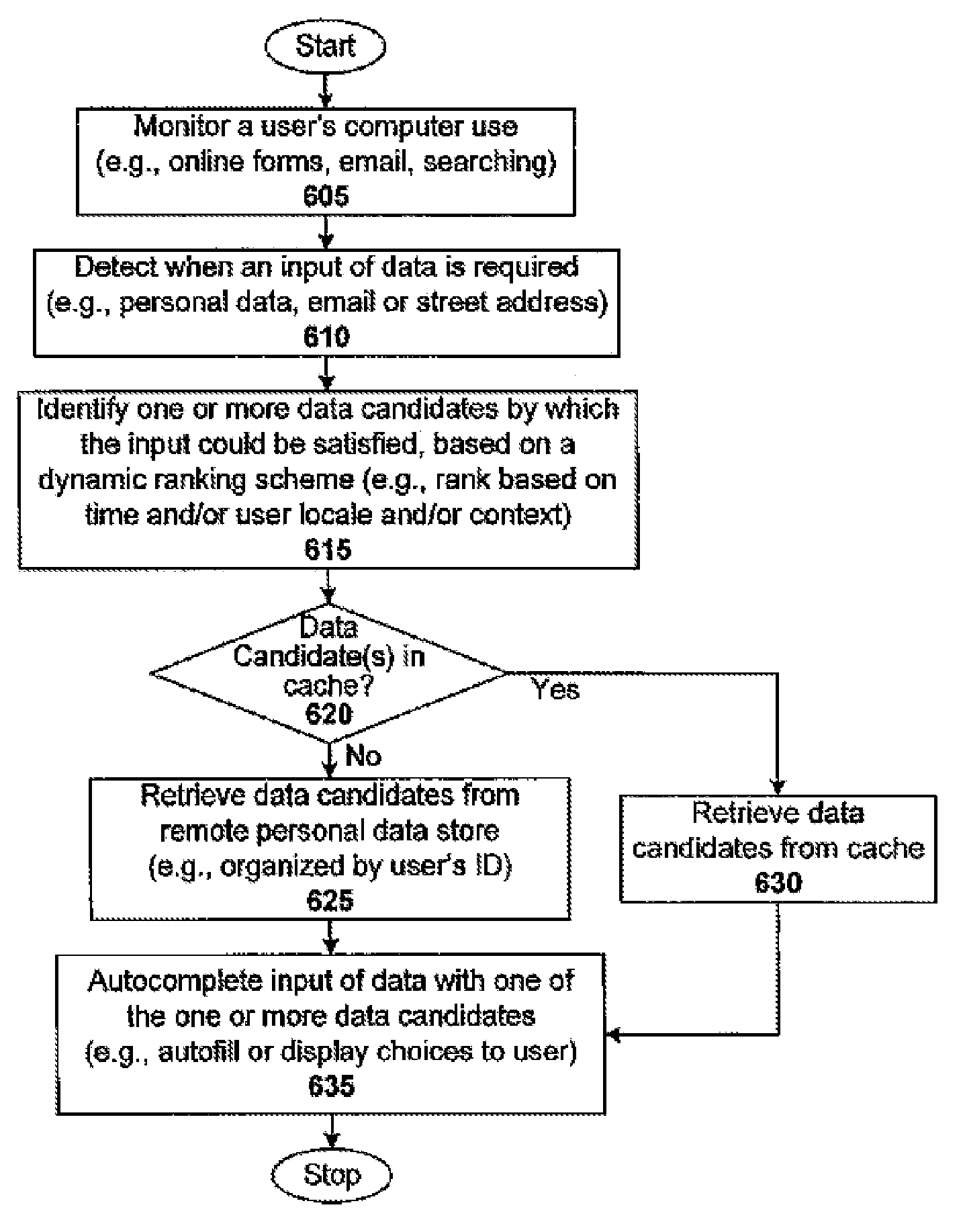
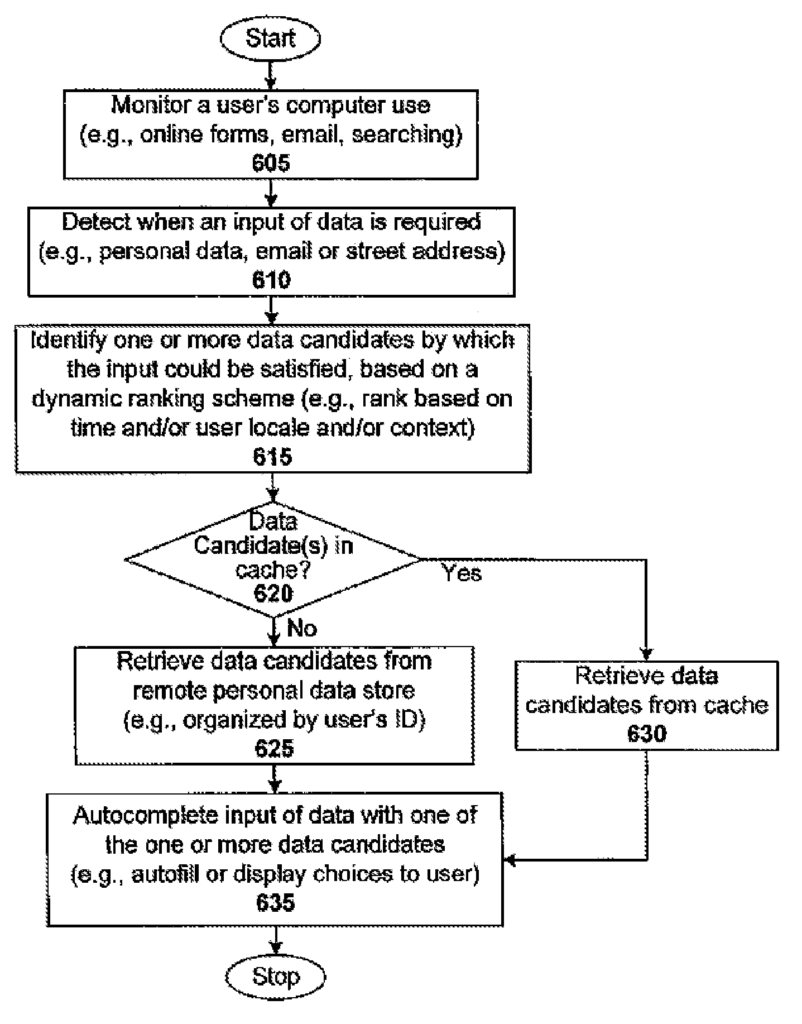
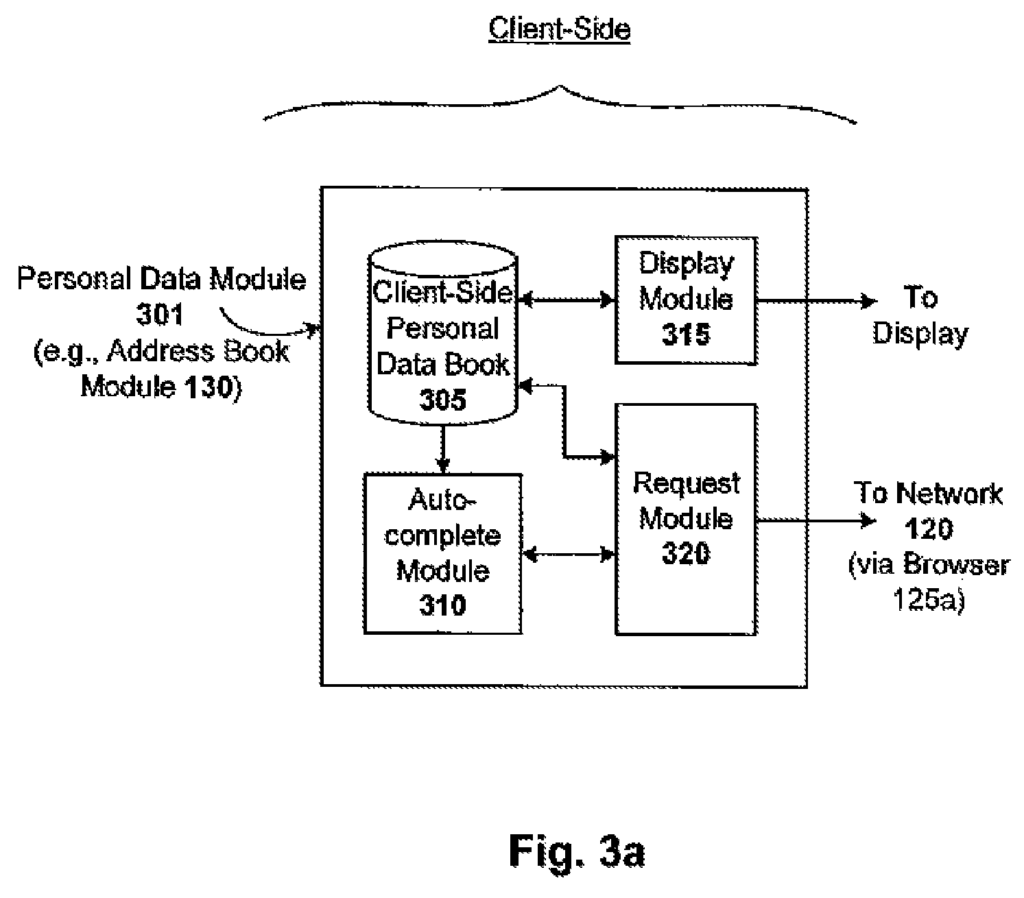
One embodiment is a computer implemented method for dynamically auto-completing a data input for a user. The method includes detecting a data input requirement by a computer application and identifying data candidates that could satisfy the input, based upon a dynamic ranking system associated with the user. The method then autocompletes the data input with the selected data candidate. The method can include a preliminary step for monitoring the computer usage of the user. In one case, autocompleting data input with one or several data candidates involves displaying one or multiple data candidates to the users, allowing them to choose one, and then autofilling that selected data candidate in a user interface of the computer-based software application. In one case, the display of one or more data candidate is done in response to the partial data that the user manually enters into the user interface. In another case, the display of one or more data candidate is performed before the user enters any data manually into the user interface. The dynamic ranking scheme may assign a rank to each one or more of the data candidates based on, for instance, the geographic location of the users, the time of usage, the browsing activity of the users, or the context of their use. The method can include retrieving one or more data candidate from a user-associated personal data storage. In such a case, retrieving one or multiple data candidates from an associated personal data storage includes determining whether the data candidate is available locally. If the data candidates are locally available, then the method can continue to access those data candidates. If the data candidates are not available locally, the method can continue to access the data candidates via a communication network. Estimating the user’s geographical location may be part of the method based on metadata related to at least one computer-based application and searches conducted by the user in the past. The user’s location can be estimated based on an IP address that is associated with a computer-based app, or address information entered into a mapping interface by the user. In one case, the application is a mail application. The data input is an email. In a different case, a computer-based application that is coupled with a search engine is used. The input data in this instance is a set of search terms. This disclosure will reveal other applications. “The method can include determining whether a data candidate’s correct and discarding any incorrect data candidates to prevent them from being displayed to the user.
This invention also provides a machine readable medium (e.g. one or multiple compact disks or diskettes, servers or memory sticks) that is encoded with instructions. When executed by one processor, the processor will carry out the process of dynamically autocompleting data entry. This process could be similar or a variant of the method previously described.
Another embodiment is a system that dynamically completes a data entry by a user. The functionality of the system can be implemented in a variety of ways, including software (e.g. executable instructions encoded onto one or multiple computer-readable media), hardware (e.g. gate level logic, or one or several ASICs), firmware, or a combination thereof. This disclosure will reveal many suitable ways to implement embodiments of the invention.
The figures and descriptions will reveal many more features and benefits. It should also be noted that language in the specification was chosen primarily for its readability and educational purposes and not as a way to limit the inventive subject matter.
Techniques for automatically generating personal data are disclosed, including an address book, financial portfolio, discussion groups, blogs, or other personal data stores. These techniques are based on structured search data or usage data of a user, or any other structured data that is provided to or by the user. The context and/or related metadata can be used to generate and/or maintain the personal data.
Structured Data” is any data that has been extracted in a semi-structured form or a completely structured format. When conducting a search, for example (e.g. an Internet search, or database query), a user can provide structured data either directly or inadvertently. In order to request driving directions, for example, the user must provide structured data, such as a start and destination address, when he or she uses an online map service. The start address is inferred from the user’s current location or home/work address using the techniques described in this document. The destination address can then be inferred as an address that the user finds interesting (e.g. a friend or business contact). By conducting searches like?grocery store near Palo Alto?, the user can provide address information indirectly. The user’s current location or home address can be deduced to be Palo Alto. In the same way, when a user requests stock information from a service provider, they directly provide structured data, such as a stock or company name. Indirectly, the user can provide structured data as financial information by, for instance, conducting searches like “chip makers”. The user’s stock interest can be deduced to be linked to companies such as Intel and AMD. In these cases, structured data can be associated or entered into a user’s personal data book (e.g. an address book or financial portfolio or discussion groups and blogs book). It is important to note that users can also submit unstructured information that is then converted into structured data by the processing system. This is also meant to be considered “structured data”. for purposes herein. Data that is structured can also be harvested from emails that the user receives, for example, information (e.g. addresses, stock symbols) that appears frequently in the email. This information can be deemed particularly valuable if a user replies to the email (or acknowledges the receipt of the information in an appropriate way, like saving it to a folder).
Usage Data” is any information that an Internet user enters while surfing the web. A user might access an online directory listing local restaurants and select a “driving directions” link. In order to avoid using a map search, a user may choose a link that provides?driving directions? in the listing of a restaurant. It can be deduced that the user is planning to visit the restaurant address that’s associated with the link, which makes that address more significant to the users (e.g. the address can be automatically harvested and saved to their address book). A user can also collect usage data by clicking on categories, and then clicking other data which is indicative of the user’s interest within the category. This categorized data can be used to infer user preferences and other information about the user. These preferences and information can then be used to automatically rate or otherwise evaluate data for the user.
Metadata includes data such as the time the user conducted the search and/or accessed the system (e.g., during the daytime, or evening, when they were at home), the IP address from which the query was transmitted (e.g., to indicate a geo code or lat/lon associated with that IP address), the context of the search (e.g., directions, stock information, etc), and how important the search was to the user. Example metadata includes what time the user conducted the search and/or otherwise accessed the system (e.g., in the daytime during work hours, or in the evening during home-time), from what IP address the search query was transmitted (e.g., to indicate a geo code or lat/lon associated with that IP address), within what context was the search conducted (e.g., was the search for directions, stock information, etc), how important was the search to the user (e.g., did the user save the resulting directions to email or SMS message), what topics/services the user indicated in the search, and/or what searches/browsing the user carried out before and/or after the search/usage/selection.
The privacy of the user’s data is protected, and the user is relieved from the burden of updating and maintaining this data. Users can control the way their personal data is collected, stored and/or utilized.
General Overview
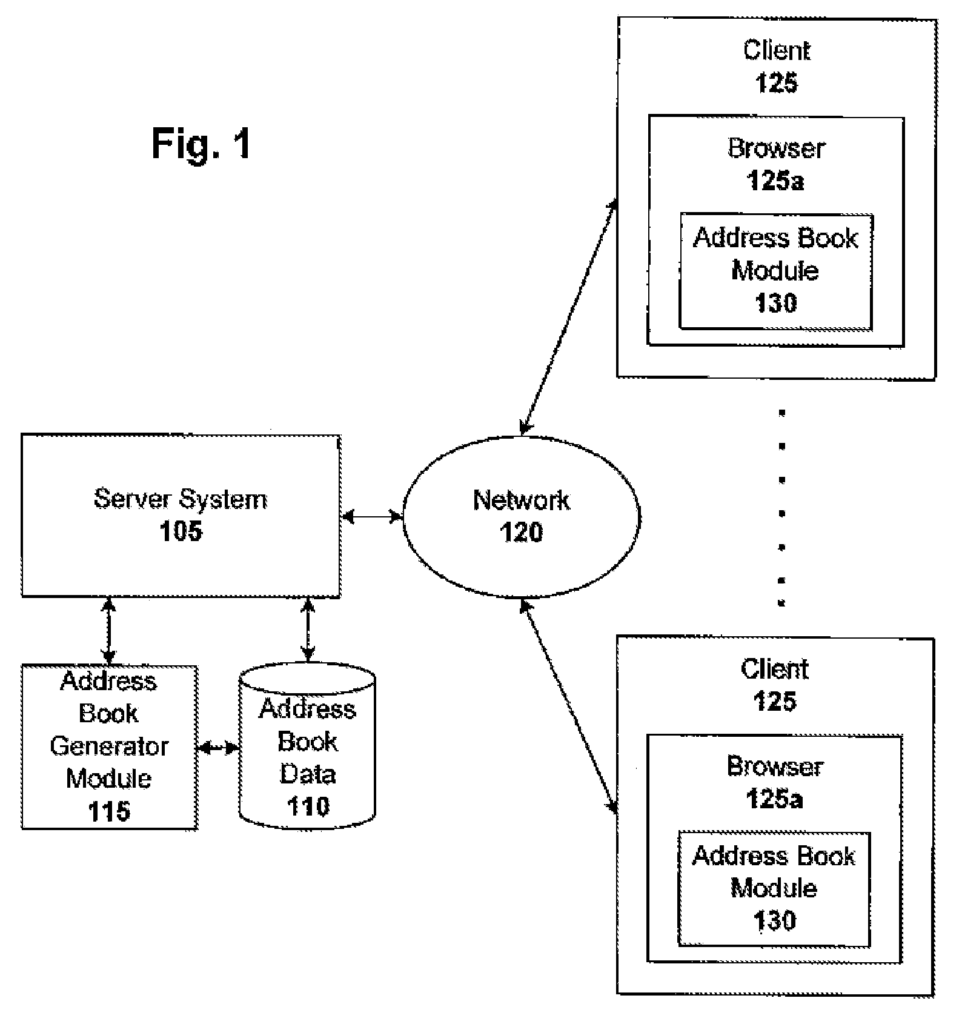
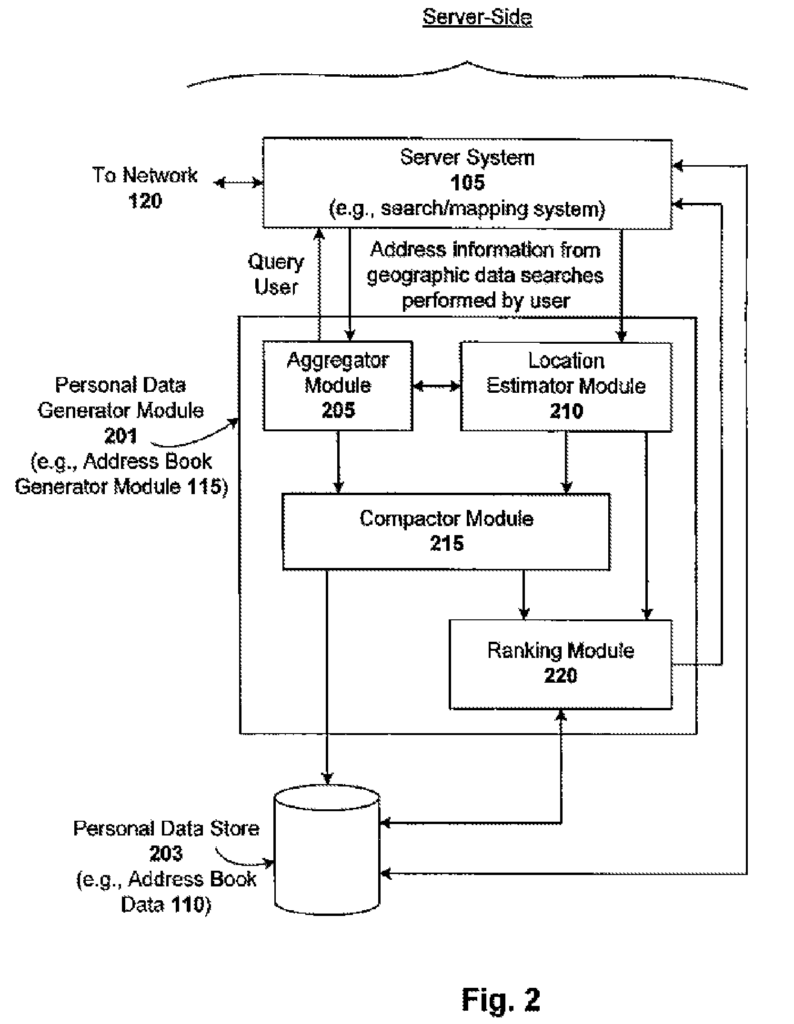
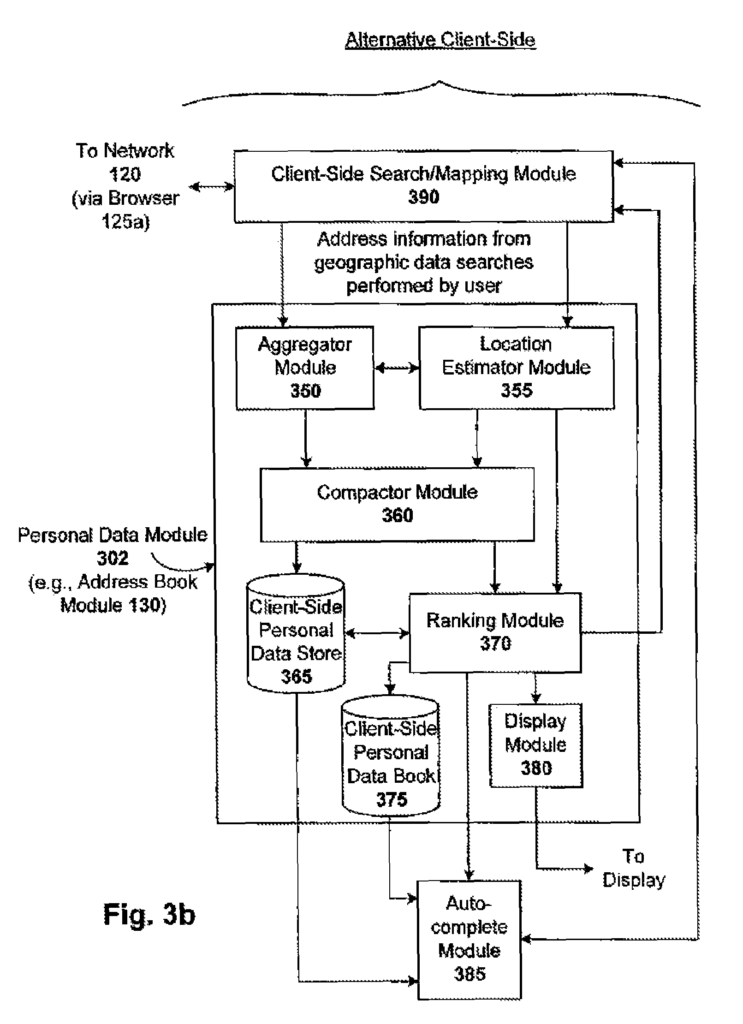
One embodiment of the invention is a client/server system that generates and maintains personal data based upon a person?s Internet search and/or browsing activities. The system generates and stores personal data for that user based on aggregated information (e.g. incrementally) derived from the data searches or browsing done by the person. Data searches are performed in many contexts. Each context provides useful information that can be collected, statistically analyzed, aggregated and used to provide useful personal data. Personal data can be directly related to the context in which the structured data was searched (e.g. stock portfolio data generated from financial searches on the Internet) or indirectly (e.g. address book data generated from map searches on the Internet). The browsing performed by a user can also reveal personal data. This is when data related to mouse clicks, or other selections made by the user are collected. “The generating and maintaining personal data can either be done on the client side, server-side or a combination of both.
One such embodiment is a system that generates an address book. The system automatically generates and maintains an address book for a user based on the information gathered (e.g. incrementally) by geographic data searches conducted by the user. Information is collected, for example, each time a user performs a geographical data search. This could be a search to find a landmark or driving/walking instructions using an online map (e.g. Google Maps or MapQuest) or a local business or event using a local search engine (e.g. Google Local or Yahoo! Local). The names of people and/or businesses can be associated with the addresses that are entered in such search services, for example using directory listings databases (e.g. white or yellow pages databases). Address/name pairs are then added to the address book of the user. Metadata (e.g. time/day and IP address of the user) associated with every search can be analyzed in order to deduce various aspects of an address (such as its importance to the user).
The address book system may be fed by any client-server communication technique. In one embodiment, Asynchronous JavaScript (Ajax), XML and other calls between the client-server are used. Address data can then be stored/retrieved by using custom or conventional database techniques. JavaScript is used to enhance the accessibility of the address book by using autocomplete features (e.g. with Google Gmail). Address entries can also be ranked (e.g. incrementally) based on various ranking signals, such as emotional value, time decay and seasonality. A user’s frequent and current geographic locations can also be determined from data such as search history, search time, and HTTP header+cookie to be used in maps and other localizable service, such email, internet searching, and ads. Locality information is useful for adding dynamic features to autocomplete and ranking functions.
As previously indicated, the principles of the invention can be used to create other products and services such as online financial service, discussion and social group services, bookmarks and blog services, and news search services. The present invention does not intend to be limited to the generation of address books. In the context of financial entities, for example, principles of the invention can be applied to generate a portfolio or book of those finance entities that the user is most interested in, such as exchanges, mutual funds, futures, companies, commodities, contracting parties and amounts, with specified prices and future transaction dates. These information can be gathered from online financial searches performed by the user. They can then be added to a user’s financial portfolio and/or dynamically ordered for portfolio display. In the context of social and discussion groups, blogs and news, the principles of the invention can also be used to create a list of favorites, or a representation thereof, for favorite groups, friends, blogs, news sources and bookmarks. Note that structured data is meant to encompass any structured data extracted using semantic analysis (e.g. clustering, synonyms), or other technologies measuring the connections between words.
Click here to view the patent on Google Patents.
Leave a Reply