Invented by Lalitesh Katragadda, Bret Steven Taylor, Google LLC
One of the key drivers behind the market growth is the time-saving aspect of automatically maintaining an address book. Manually updating contact information can be a tedious and time-consuming task, especially when dealing with a large number of contacts. By using automated tools, individuals can eliminate the need for manual data entry and rely on software to keep their address book updated. This not only saves time but also reduces the chances of errors or missing information.
Another factor contributing to the market growth is the integration of address book management with various communication platforms. Many automated solutions now offer synchronization with email accounts, social media profiles, and other contact sources. This means that whenever a contact updates their information on one platform, it automatically reflects in the user’s address book. This seamless integration ensures that contact information remains accurate and up to date across all platforms, eliminating the need for manual updates.
The market for automatically maintaining an address book is not limited to individual users. Businesses, especially those with large customer databases, can benefit greatly from automated contact management. By integrating their customer relationship management (CRM) systems with address book automation tools, businesses can ensure that their customer data is always accurate and accessible. This can improve customer service, enhance marketing efforts, and streamline communication with clients.
Furthermore, the market for address book automation is also driven by the increasing need for data privacy and security. Many automated solutions prioritize data protection, ensuring that contact information is stored securely and only accessible to authorized individuals. This is particularly important for businesses that handle sensitive customer data and need to comply with data protection regulations.
As the market continues to grow, there are several key players offering address book automation solutions. These range from standalone software applications to cloud-based platforms that offer additional features such as contact deduplication, data enrichment, and contact tagging. The pricing models also vary, with some solutions offering free basic versions and others requiring a subscription fee for advanced features.
In conclusion, the market for automatically maintaining an address book is experiencing significant growth due to the increasing need for efficient contact management. The time-saving aspect, integration with various communication platforms, and data privacy considerations are driving the demand for automated solutions. As technology continues to advance, we can expect further innovations in this market, making contact management even more seamless and hassle-free.
The Google LLC invention works as follows
Techniques for automatically generating personal data are disclosed. These include an address book, financial portfolios, discussion groups, blogs, or any other type of personal data store, all based on structured search data or usage data of a user (e.g. browsing), or from other sources (e.g. emails received by the user). Metadata can be used to generate and/or maintain the personal data. “Autocomplete and dynamic personal data ranking functions can also be used to ease the burden of managing or handling personal data.
Background for Automatically maintain an address book
The person who is responsible for the data will typically perform this process manually. Take, for instance, the address book of a person.
An addressbook is a collection that contains contact information, such as the address (home or office), phone number (home or office), fax number, email address, etc. The contact information is stored in most address book systems alphabetically, according to the last name of each contact. In the past, address books were created on paper. Some address books are loose-leaf bound to make it easier to update the book as contacts change.
Many people keep their address book using electronic organizers, or software-based addresses books. This eliminates many of the issues associated with paper-based books. These address books are used in many e-mail programs. Personal information manager systems (PIMs) are also available, which integrate various common features such as an email address book, a personal calendar, or schedule, or a timeline with action items to be completed.
The electronic address book is very portable because it can be synchronized between devices, e.g. between a desktop computer and a personal digital assistant. Individual entries from an electronic address can also be transferred, such as vCards, to simplify the exchange of contact details.
In any case, an electronic address book contains a collection of dynamic data. This address book requires a lot of maintenance as new contacts are added or existing contacts’ details change. This maintenance is currently done manually, as required, by the owner. This maintenance is time-consuming, tedious, and the process to access a specific address (such as searching for an address in the list of many addresses and clicking) is cumbersome.
Other forms of dynamically-changing personal data are also linked to such problems. Consider a person?s stock portfolio. This portfolio will need to be updated when there are changes, such as when a trade is made (e.g. purchase of additional stock, or new shares, or stock sale), or when certain information becomes available about the target company.
What is required, then, are techniques that automatically generate and maintain address books. There is a general need to automatically generate and maintain personal data and make it useful for the user, with little or no effort from the user.
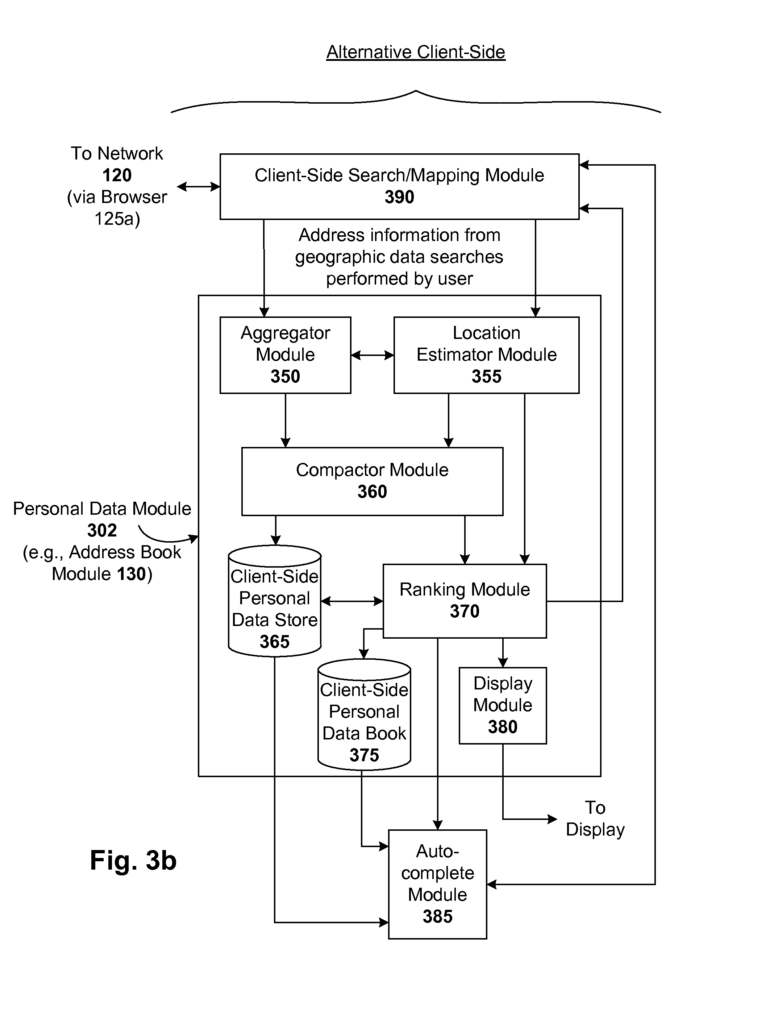
One embodiment is an automated method of generating the address book for a user. The method involves receiving a request from a user for a geographical data search, extracting address information from that request, and updating a user’s addressbook with the address information. The extracted street information can, for example be a complete or partial address, such as 1600 Amphitheatre Parkway Mountain View Calif. Locally, the user can update the address book by adding the street address data (e.g. on the client device that stores the address book). The user can update their address book remotely. The method can also include sending an updated address book to the client device that stores the address book in batches (e.g. multiple entries, or the entire addressbook) or incrementally (e.g. one entry per time, as new entries are made or changes are made). For example, the geographic data search could be for directions between two locations or addresses, a map of a specific zip code or location, or a local search for businesses or events in a given zip code or location. The method can include assigning a street address label, which may include a name or business of the person or business that is associated with the address. The method can also include labeling the street information with a name or names of the locations where the user will likely use it (e.g. “work” or “home? The method may also include assigning one or more labels to the street address information, including a name of a location where the user is likely to use this information (e.g.,?work? Labels) and/or ID. The method can include assigning one ranking signal to the street address data based on metadata related to the search. In such a case, the rank that is subsequently assigned to street address information based on ranking signals (e.g. based upon one or more ranking indicators) can be dynamically adjusted depending on the geographic location of the users, the current time and/or the context. The method can also include assigning ranking signals based on the browsing activity of the user. Estimating the user’s geographical location may be done based on metadata related to the search and/or prior searches conducted by the user. In one case, estimating a user’s geographical location is based upon an IP address that’s associated with a user’s location. In addition, or alternatively, the address information entered into the mapping system interface by the user can also be used to estimate the user’s geographical location. For example, a local search could be conducted for “pizza near the 1213 Edward Street?” or for driving directions or walking directions. The method can include compacting street address data along with at the least one of a name, a label, or a business name, one or more ranking indicators, user location information, and metadata associated with this street address data into a single, associated entry. In such a case, adding the address to an address data store, from which a user’s address list can be updated and/or updating it when future requests are received (e.g. searches and browsing selections that include street address information) may also be included in the method. When future requests are made, the update may include updating metadata statistics related to the address data, ranking signals for the address data, or user localities. In this way, a statistical aggregation is associated with each harvested address over time. The method can include accessing directory listings (e.g. residential or commercial, personal, shared, groups, and/or publicly available listings) and matching the extracted information with one of them to identify, for instance, a corresponding address name and/or missing elements of the address data, if appropriate. The method can include autocompleting the entry of address data from a user’s addressbook into a user-interface (e.g. a mapping system, an interactive voice response interface or IVR, or other data entry or speech based interfaces). In one case, auto-completing address information from the address book of the user includes displaying a list of addresses (allowing the user the option to choose one of these addresses) and then entering the selected address in the user interface. In one such instance, the display of one or more addresses is performed before the user inputs the street address data in the user interface. In other embodiments, autocomplete may be based on keystrokes. The displayed addresses will then be based on the partial address entered by the user. One or more addresses in the user’s contact book can be selected dynamically, based, for instance, on the geographic location, time, and/or context of the user. The user’s browsing activity can also be used to dynamically select one or more of the addresses in the address book. As an example, browsing activity could indicate that the user has entered a social mode, e.g. looking up movie theaters or showtimes, and therefore ranking would favor social contacts/addresses. In another case, browsing activity could indicate that the user was in a professional mode, e.g. looking at articles or services related to trade, and therefore ranking would favor contacts/addresses of professionals. The method can include harvesting street addresses associated with the browsing activity of the user, and updating their address book with this harvested information. If, for example, the user selects, (e.g. using an input device like a mouse), a displayed/relayed street address that appears in search results or advertisements, listings, etc. while browsing, this address can then be added to the address book. This browsing-based harvesting of addresses can be used with geographic data searches or as an alternative.
This embodiment provides a machine-readable media (e.g. one or multiple compact disks or diskettes, servers or memory sticks) that is encoded with instructions. When executed by a processor, the instructions cause the processor to perform a process of automatically generating an address book for the user. This process could be similar or a variant of the method previously described.
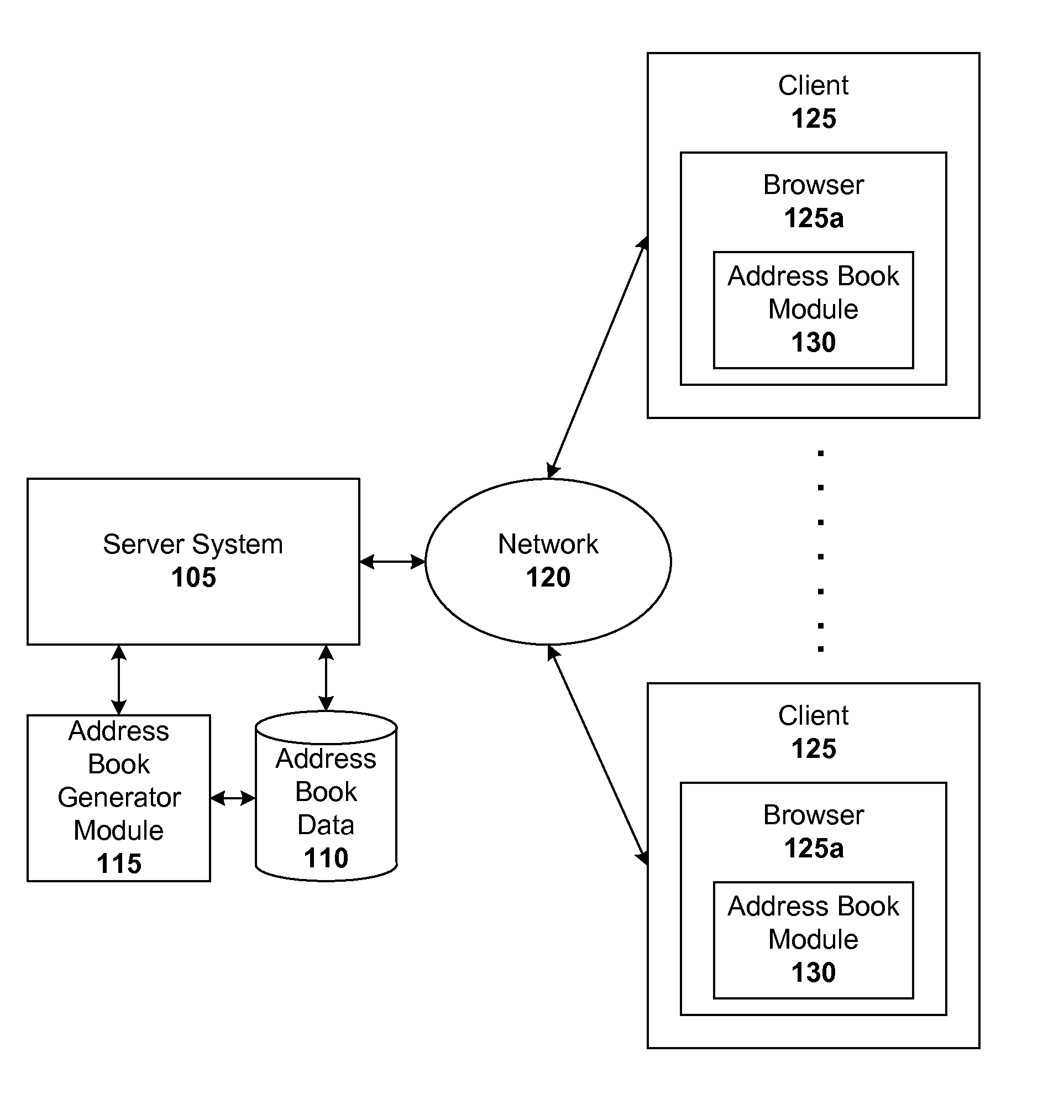
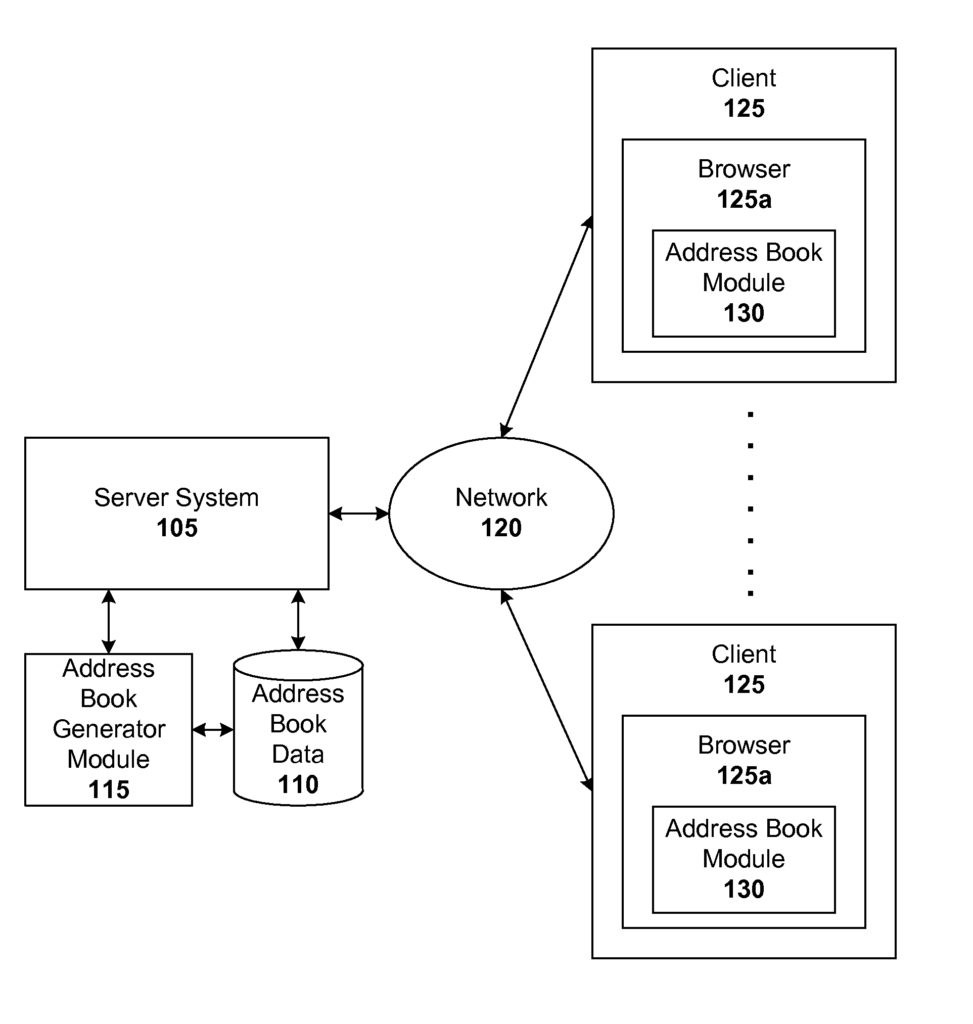
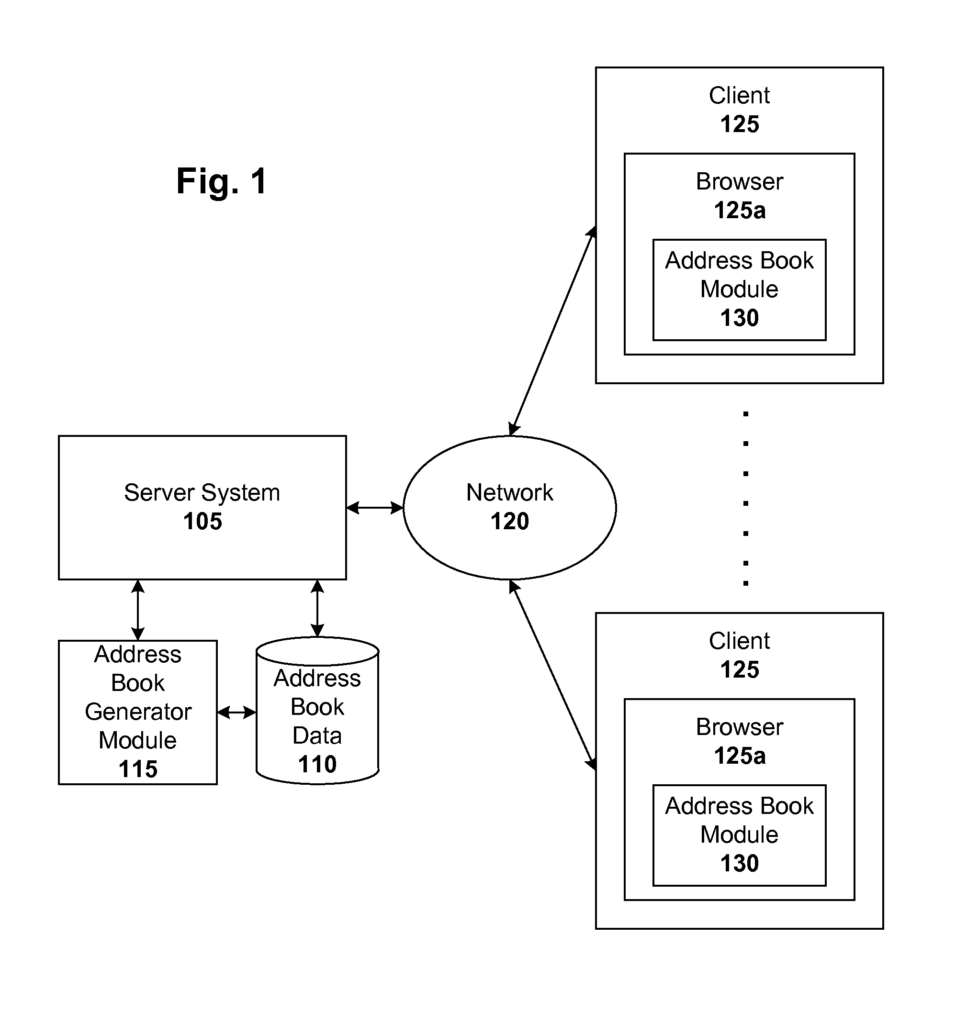
Another embodiment is a system that automatically generates a user’s contact book. The system comprises a server system that receives a request from a user for a geographical data search and a personal information generator module, which is operatively connected to the server system. This module extracts street address data from the request and updates the user’s contact book with this information. In a particular configuration, there is a server side and a client side, with the server system and personal data generator module located on the client side. The server system and personal data generator modules can also be placed on the server side. In one configuration, the server side is configured to send the updated address book from the client-side either incrementally or in batches. This disclosure will reveal a number of other configurations, such as serverless systems or systems in which some functionality is performed on the client side and other functionality on the server side.
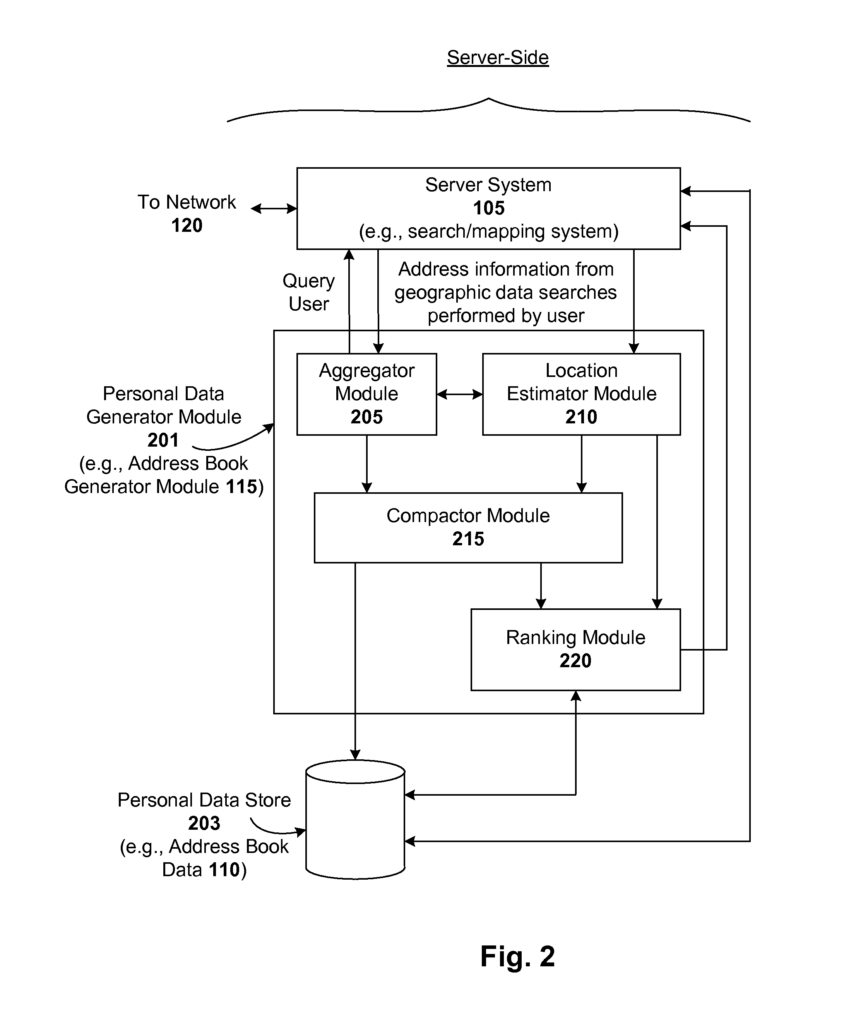
The system can include a module that assigns a rank to street address information based on a number of ranking signals (e.g. derived from metadata related to the search or browsing activity by the user). In such a system, the module adjusts the rank dynamically based on the geographic location, time and/or context of the user. This dynamic ranking adjustment is especially powerful for user requests that involve street address information from the user’s addressbook, where the best-ranked entries can then be presented to them. The system can include a module that estimates the user’s geographical location using metadata associated with the query and/or searches previously performed by the individual. In one system, the location module estimates the geographic location of the user based on the IP address that is associated with their geographic location and/or the address entered by the users into the mapping system interface.
The system functionality may be implemented in hardware (e.g. gate level logic, or one or multiple ASICs), software (e.g. one or several microcontrollers having I/O capabilities and embedded routines to carry out the functionality described), or a combination of these. This disclosure will reveal many suitable ways to implement embodiments of the invention.
The figures and descriptions will reveal many more features and benefits. It should also be noted that language in the specification was chosen primarily for its readability and educational purposes and not as a way to limit the inventive subject matter.
Techniques for automatically generating personal data are disclosed, including an address book, financial portfolio, discussion groups, blogs, or other personal data stores. These techniques are based on structured search data or usage data of a user, or any other structured data that is provided to or by the user. The context and/or related metadata can be used to generate and/or maintain the personal data.
Structured Data” is any data that has been extracted in a semi-structured form or a completely structured format. When conducting a search, for example (e.g. an Internet search, or database query), a user can provide structured data either directly or inadvertently. In order to request driving directions, for example, the user must provide structured data, such as a start and destination address, when he or she uses an online map service. The start address is inferred from the user’s current location or home/work address using the techniques described in this document. The destination address can then be inferred as an address that the user finds interesting (e.g. a friend or business contact). By conducting searches like?grocery store near Palo Alto?, the user can provide address information indirectly. The user’s current location or home address can be deduced to be Palo Alto. In the same way, when a user requests stock information from a service provider, they directly provide structured data, such as a stock or company name. Indirectly, the user can provide structured data as financial information by, for instance, conducting searches like “chip makers”. The user’s stock interest can be deduced to be linked to companies such as Intel and AMD. In these cases, structured data can be associated or entered into a user’s personal data book (e.g. an address book or financial portfolio or discussion groups and blogs book). It is important to note that users can also submit unstructured information that is then converted into structured data by the processing system. This is also meant to be considered “structured data”. for purposes herein. Data that is structured can also be harvested from emails that the user receives, for example, information (e.g. addresses, stock symbols) that appears frequently in the email. This information can be deemed particularly valuable if a user replies to the email (or acknowledges the receipt of the information in an appropriate way, like saving it to a folder).
Usage Data” is any information that an Internet user enters while surfing the web. A user might access an online directory listing local restaurants and select a “driving directions” link. In order to avoid using a map search, a user may choose a link that provides?driving directions? in the listing of a restaurant. It can be deduced that the user is planning to visit the restaurant address that’s associated with the link, which makes that address more significant to the users (e.g. the address can be automatically harvested and saved to their address book). A user can also collect usage data by clicking on categories, and then clicking other data which is indicative of the user’s interest within the category. This categorized data can be used to infer user preferences and other information about the user. These preferences and information can then be used to automatically rate or otherwise evaluate data for the user.
Metadata includes data such as the time the user conducted the search and/or accessed the system (e.g., during the daytime, or evening, when they were at home), the IP address from which the query was transmitted (e.g., to indicate a geo code or lat/lon associated with that IP address), the context of the search (e.g., directions, stock information, etc), and how important the search was to the user. Example metadata includes what time the user conducted the search and/or otherwise accessed the system (e.g., in the daytime during work hours, or in the evening during home-time), from what IP address the search query was transmitted (e.g., to indicate a geo code or lat/lon associated with that IP address), within what context was the search conducted (e.g., was the search for directions, stock information, etc), how important was the search to the user (e.g., did the user save the resulting directions to email or SMS message), what topics/services the user indicated in the search, and/or what searches/browsing the user carried out before and/or after the search/usage/selection.
The privacy of the user’s data is protected, and the user is relieved from the burden of updating and maintaining this data. Users can control the way their personal data is collected, stored and/or utilized.
General Overview
One embodiment of the invention is a client/server system that generates and maintains personal data based upon a person?s Internet search and/or browsing activities. The system generates and stores personal data for that user based on aggregated information (e.g. incrementally) derived from the data searches or browsing done by the person. Data searches are performed in many contexts. Each context provides useful information that can be collected, statistically analyzed, aggregated and used to provide useful personal data. Personal data can be directly related to the context in which the structured data was searched (e.g. stock portfolio data generated from financial searches on the Internet) or indirectly (e.g. address book data generated from map searches on the Internet). The browsing performed by a user can also reveal personal data. This is when data related to mouse clicks, or other selections made by the user are collected. “The generating and maintaining personal data can either be done on the client side, server-side or a combination of both.
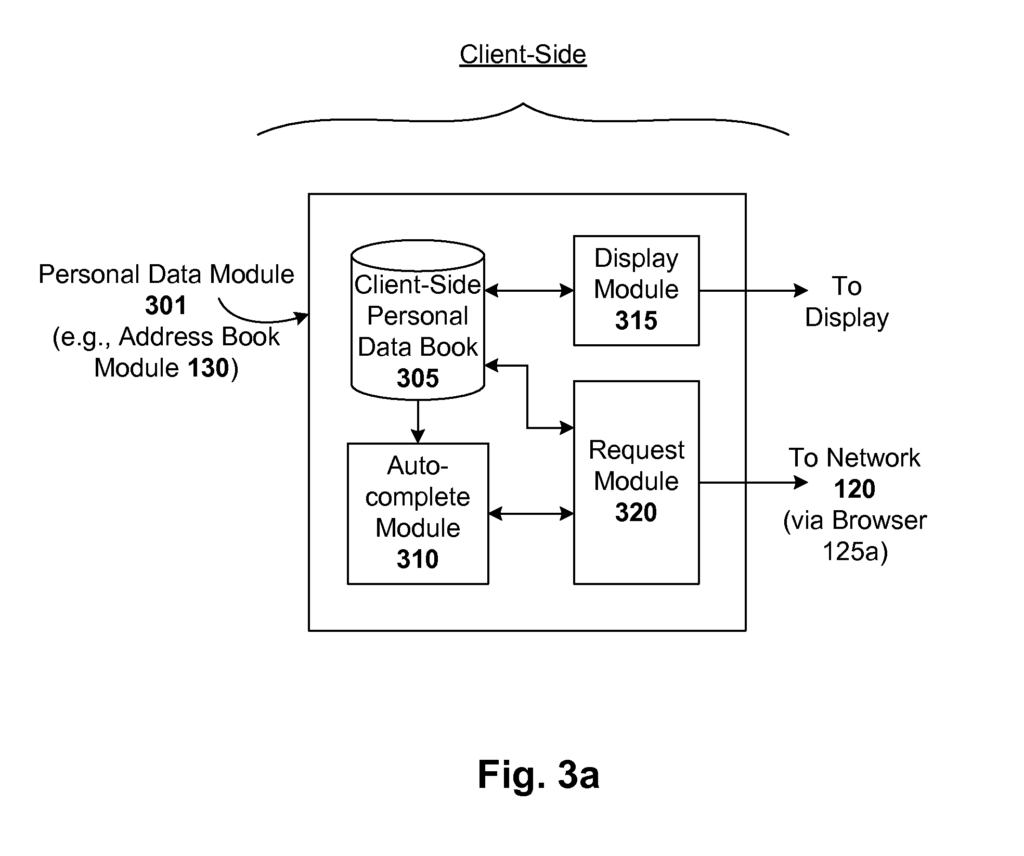
One such embodiment is a system that generates an address book. The system automatically generates and maintains an address book for a user based on the information gathered (e.g. incrementally) by geographic data searches conducted by the user. Information is collected, for example, each time a user performs a geographical data search. This could be a search to find a landmark or driving/walking instructions using an online map (e.g. Google Maps or MapQuest) or a local business or event using a local search engine (e.g. Google Local or Yahoo! Local). The names of people and/or businesses can be associated with the addresses that are entered in such search services, for example using directory listings databases (e.g. white or yellow pages databases). Address/name pairs are then added to the address book of the user. Metadata (e.g. time/day and IP address of the user) associated with every search can be analyzed in order to deduce various aspects of an address (such as its importance to the user).
Click here to view the patent on Google Patents.
Leave a Reply