Invented by Jian Wu, Samsung SDS America Inc
Large-scale machine learning models refer to complex algorithms that can process and analyze massive amounts of data to make accurate predictions and generate valuable insights. These models are typically trained on vast datasets and require substantial computational resources to train and deploy. They are used in a wide range of applications, including natural language processing, image recognition, fraud detection, recommendation systems, and autonomous vehicles, among others.
One of the key drivers behind the increasing demand for large-scale ML models is the exponential growth of data. With the proliferation of digital technologies and the internet, organizations are collecting and generating enormous volumes of data every second. To extract meaningful information from this data and gain a competitive edge, businesses need advanced ML models that can handle the scale and complexity of their data.
Moreover, the continuous evolution of ML algorithms and techniques has fueled the need for continuously providing large-scale ML models. As researchers and data scientists develop new and improved algorithms, organizations strive to integrate these advancements into their existing ML models. This requires a continuous process of retraining and updating models to ensure they stay up-to-date and deliver accurate results.
The market for continuously providing large-scale ML models is not limited to tech giants or large enterprises. Startups and smaller companies are also recognizing the potential of ML models and are increasingly adopting them to enhance their operations. Cloud service providers have played a crucial role in democratizing access to ML models by offering scalable and cost-effective solutions. This has made it easier for organizations of all sizes to leverage large-scale ML models without significant upfront investments in infrastructure and expertise.
The market for continuously providing large-scale ML models is highly competitive, with numerous players offering a wide range of solutions. Some companies specialize in developing and training ML models for specific industries or use cases, while others focus on providing platforms and tools for organizations to build and deploy their models. Additionally, there are companies that offer pre-trained models that can be easily integrated into existing systems, reducing the time and effort required for development.
As the market continues to evolve, there are several challenges that need to be addressed. One of the key challenges is the ethical use of ML models, particularly in sensitive domains such as healthcare and finance. Ensuring fairness, transparency, and accountability in ML models is crucial to avoid biases and unintended consequences.
Another challenge is the need for robust infrastructure and computational resources to support large-scale ML models. Training and deploying these models require significant computing power and storage capabilities. Cloud providers and edge computing solutions are continuously innovating to address these challenges and provide scalable and efficient solutions.
In conclusion, the market for continuously providing large-scale machine learning models is witnessing significant growth as organizations recognize the value of AI and ML in driving innovation and improving business outcomes. The exponential growth of data, continuous advancements in ML algorithms, and the democratization of ML technologies have fueled this demand. As the market evolves, addressing ethical considerations and ensuring robust infrastructure will be crucial to sustain this growth and unlock the full potential of large-scale ML models.
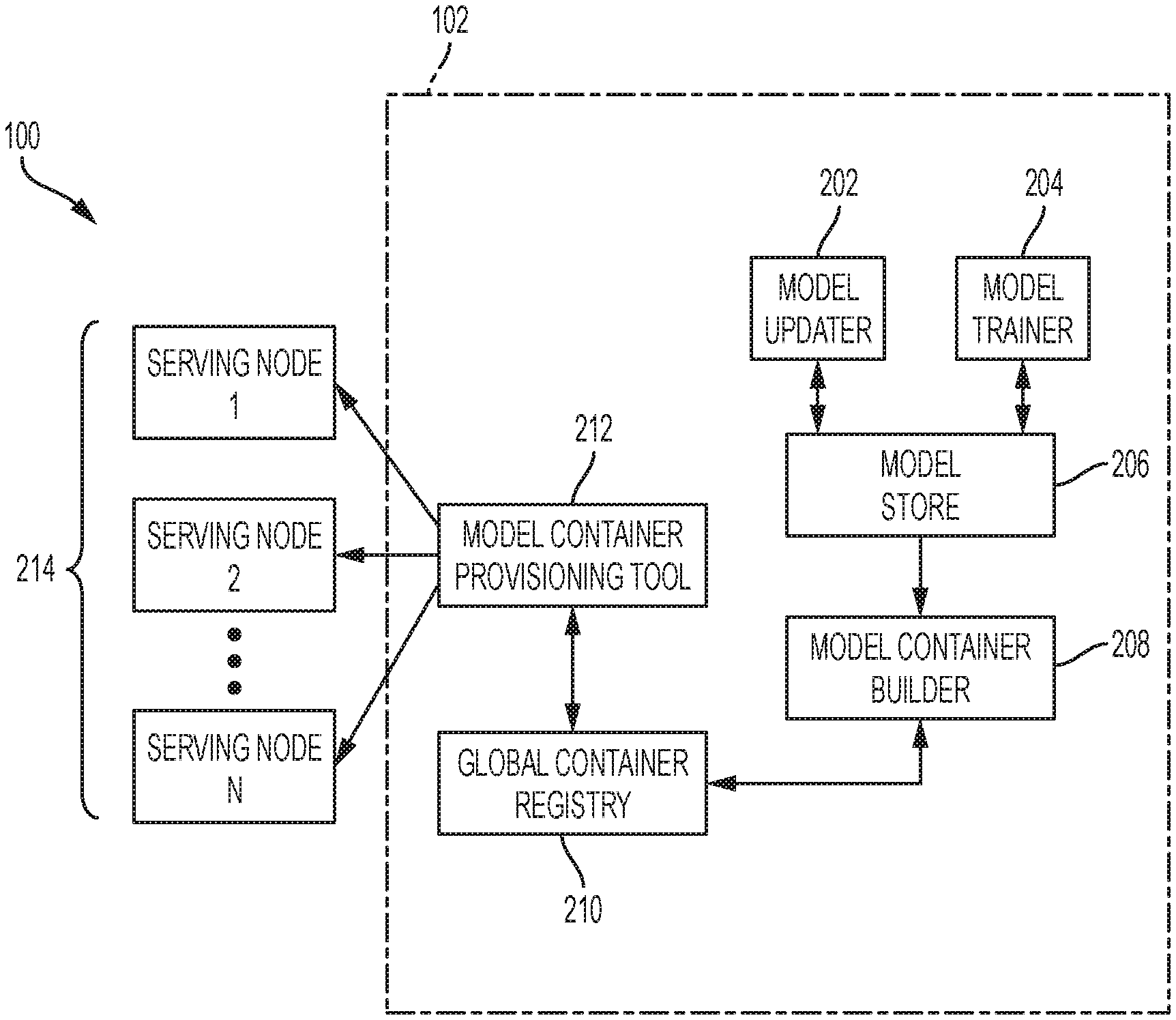
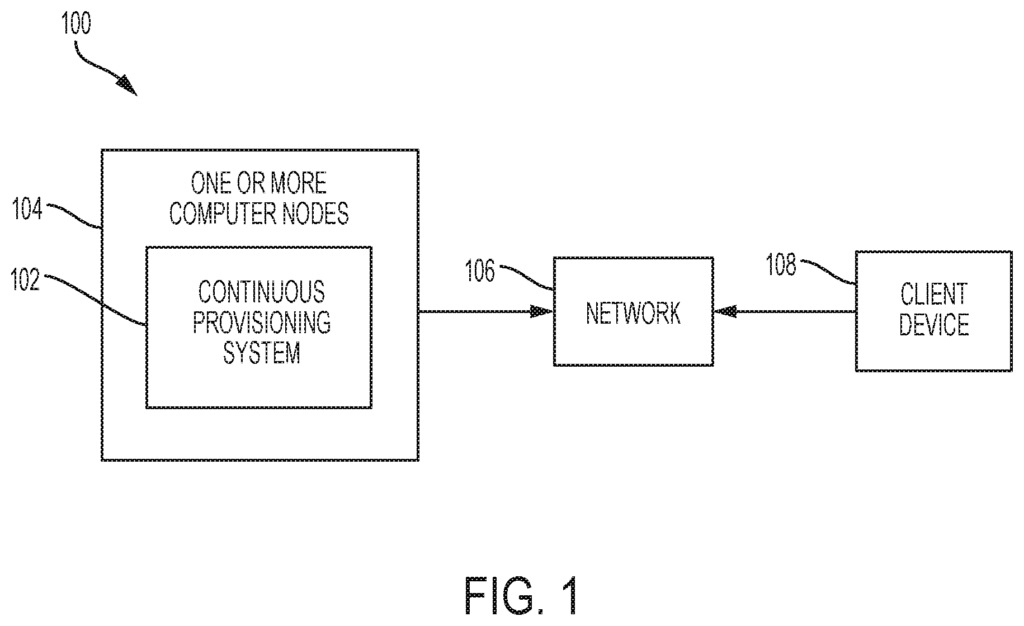
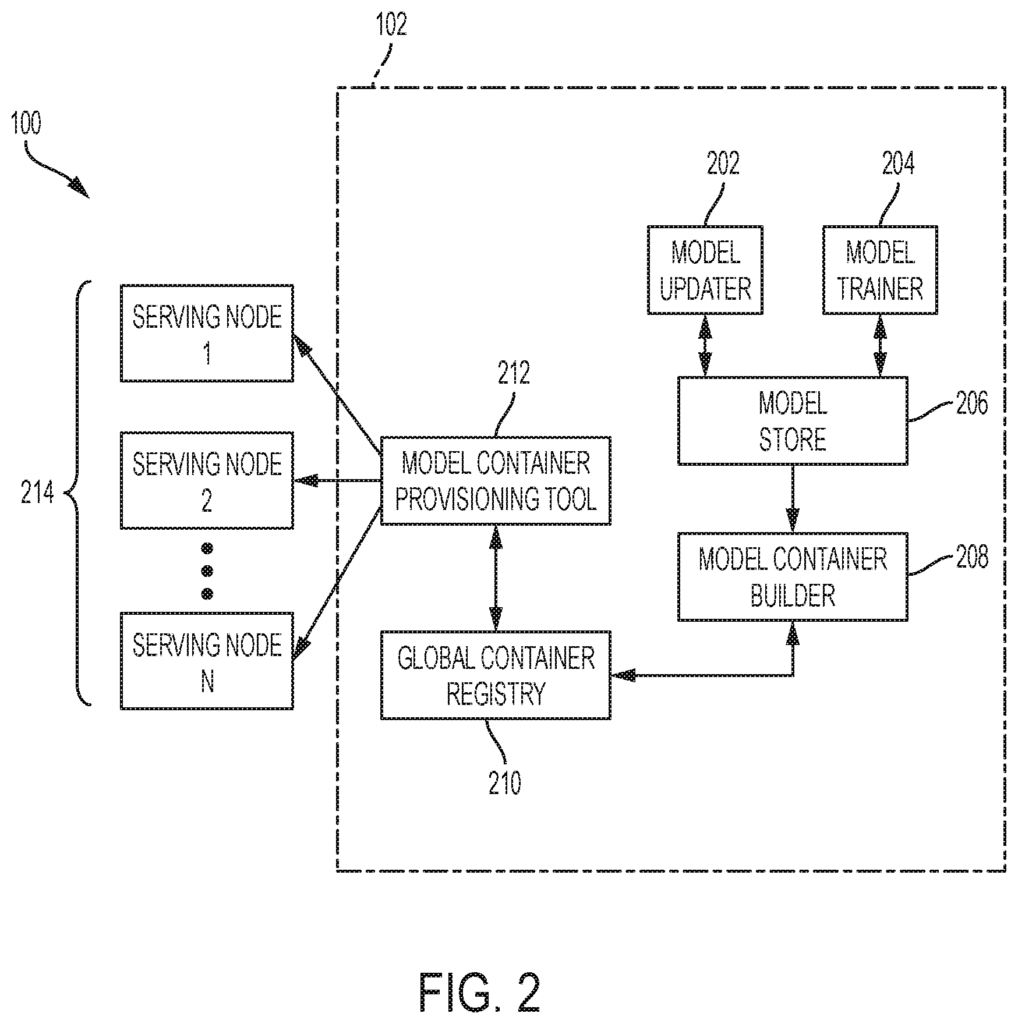
The Samsung SDS America Inc invention works as follows
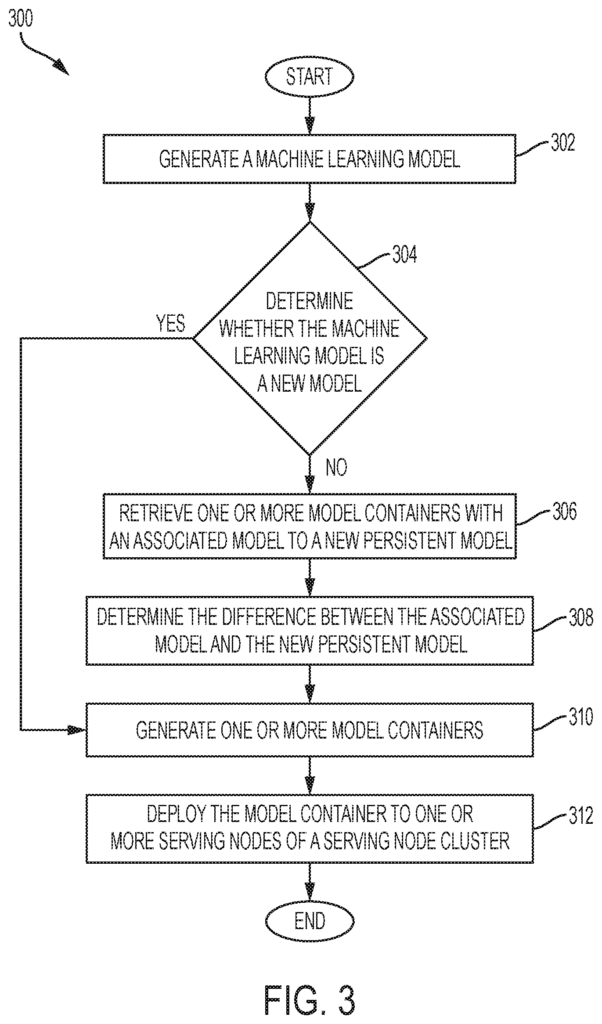
The invention is an “approach for continuously provisioning machines learning models by one or multiple computer nodes in order to respond to a client request with a prediction of the future.” The one or more computers nodes generate a machine-learning model. The approach determines by one or more computers nodes whether the machine-learning model is a brand new model. When the approach determines that the machine-learning model is not a new model, it retrieves one or multiple model containers associated with a new persistent modeling. The approach, using one or more computers, determines the difference between the associated and new persistent models. In addition, in response, to the determination that the machine-learning model is the new one, the approach generates one or more container models by the one computer node.
Background for Continuously providing large-scale machine learning models
This disclosure is a general description of machine learning applications and, more specifically, the provisioning of large-scale machine models continuously through model containers.
Complex machine learning applications are being used more often to deal with the explosion of data streams and internet usage. These machine-learning applications can be used for ad targetting, content recommendation and fraud detection.
Lambda architecture is used to build large, real-time analytics and machine-learning applications. Lambda Architecture balances the needs of low latency, fast throughput and fault tolerance by combining batch and stream processing. A lambda-architecture system includes three main data processing layers. “A batch layer, speed layer and serving layer
In a typical Lambda Architecture deployment a batch-layer, which includes a model trainer contains large data sets for training grouped into various batches. The data is then used to build one or more large machine learning models. The model updater in a speed layer updates or revises machine learning models based on data points from a data stream. These machine learning models, both trained and revised, are stored on a persistent system such as a “model store”. A machine learning model is typically stored and served as a hierarchical formatted structure with meta-data. Machine learning models can either be stored in serialized binary format, or in standard portable structured formats. “A serving layer, consisting of a cluster serving nodes, is able to serve real-time prediction requests using the latest machine learning models.
One or more nodes in the cluster of serving nodes can load the machine learning models to serve on-demand predictions from one or multiple client devices. The serving nodes are able to reload machine learning models after the model updater has updated the machine-learning model using the latest training data.
Container as a Service has been used to manage software lifecycles in the cloud as business enterprises have moved their IT infrastructures and services into the cloud. This lifecycle includes resource management, provisioning and scheduling, orchestration and scaling. Micro-services and machine-learning applications can be developed and deployed on the cloud.
To improve accuracy and quality, an increasing amount of data are collected for training. This, in turn, causes an increase in size and complexity in machine learning models. Now, it is common to see a Random Forest model with hundreds of trees and a Neural Network Model that has millions of weight parameter values. With this increase in complexity and size, it becomes increasingly difficult to store, deploy, and provision machine learning models.
The continuous provisioning methods include: retrieving by the computer nodes one or multiple model containers that contain an associated model for a persistent new model. If the computer nodes determine the machine-learning model is not a new one, they will retrieve one or several model containers containing the associated model.
In other exemplary embodiments a continuous provisioning device includes a memory and an at least one processor configured for: a model generation configured to generate a Machine Learning Model; and a container builder configured for: determining whether the machine-learning model is a “new model”, and in response to the determination that the machine-learning model is not a “new model”, retrieving one or more containers with a associated model to a persistent new model.
In other exemplary embodiments, an non-transitory recording medium includes a program that executes a continuous provisioning to provide a prediction of the future in response to the request from one client device. The method includes: generating, via one or multiple computer nodes a machine learning models; determining by the computer nodes whether the model is new; in response, retrieving by the computer nodes one or several model containers with a model associated to a persistent new model.
BRIEF DESCRIPTION DES DRAWINGS
FIG. “FIG.
FIG. “FIG.
FIG. “FIG. According to one exemplary embodiment, FIG.
Exemplary implementations of the current disclosure relate to machine learning applications in general, and to continuously provisioning models for large-scale machine. The exemplary embodiments acknowledge that machine learning models are becoming increasingly complex and large, making it more difficult to store, deploy and provision them. Below, with reference to FIGS., exemplary embodiments of continuously provisioning large machine learning models using composed model containers will be described. 1-3.
The implementation of these exemplary embodiments can take many forms. Examples of implementation details will be discussed in the following sections with reference to Figures.
FIG. “FIG. 1 is a block diagram functionally illustrating an environment for data processing 100 according to a exemplary embodiment. FIG. FIG. 1 is merely an illustration and does not imply limitations in terms of a data-processing environment where different exemplary embodiments can be implemented. The data processing environment 100 can be modified by those in the know without departing from scope of invention as stated by the claims. “In some exemplary embodiments the data processing system 100 comprises a network, one or multiple computer nodes, which operate continuous provisioning system, 102 and a client device, 108.
Network 106 connects one or multiple computer nodes 104 with client device 108. Network 106 is a combination of protocols and connections that can support communications between one or multiple computer nodes and client device 108 and one or several computer nodes and continuous provisioning systems 102. Network 106 may include fiber optic cables or wireless communication links. It can also include routers, switches and firewalls. In some embodiments, the network 106 is a message bus. In one exemplary embodiment, the continuous provisioning system implements network using one or more nodes of computer 104.
According to the examples of embodiments in the present disclosure, “the one or more computers nodes 104 host continuous provisioning system 102, according to the exemplary embodiments.” Computer nodes can be any electronic device or computer system that is programmable and capable of receiving data via network 106 and sending it to a computer. They also perform computer-readable instructions. A computer node could be, for example, a desktop or laptop computer or other electronic devices or computing systems, which are known to those of ordinary skill, and capable of communicating through network 106 with other computer cluster nodes. In some embodiments, one or more of the computer nodes can operate as one or multiple clusters within a distributed system to run continuous provisioning system via network 106. In one exemplary embodiment, one or more of the computer nodes 104 can include databases (not illustrated) that provide a predictive service to one, or more, client devices such as client device. In one embodiment, one or multiple computer nodes can be included in a cluster of serving nodes 214. The client device 108 can request a prediction or response. One or more of the computer nodes may be equipped with a provisioning system that is located either locally or remotely to the computer nodes. This provisioning system can pull a machine-learning model to serve a request for a response or prediction.
Data storage repository can be any programmable electronic device or computing system capable of receiving, storing, and sending files and data, as well as performing computer-readable program instructions. This includes, but is not limited to machine learning applications, model data, user data, training data sets, one or several container images, or model containers. The data storage repository is any electronic device that can receive, store, and send files and data. It also performs computer-readable program instructions.
In some exemplary embodiments components of the continuous-provisioning system 102 reside locally on one or more computer cluster nodes 104 in a datacenter or cloud (not illustrated). In one exemplary embodiment, components of the continuous-provisioning system 102 reside, individually or in different combinations, on one or more computer clusters 104, which are then connected by network 106. In an exemplary implementation, the network 106 links the one or multiple computer nodes 104 in the distributed clusters. (Not shown). “In yet another exemplary embodiment, the components of continuous provisioning system 102 reside on a server central (not shown).
Click here to view the patent on Google Patents.
Leave a Reply