Invented by Raj Ashok Sudarsanam, Edward K. Lee, Mark G. Gritter, Pratap V. Singh, Tintri by DDN Inc
Containers provide a lightweight and portable environment for running applications, allowing developers to build, test, and deploy their software quickly and efficiently. However, managing data within containers can be challenging, especially when it comes to synchronizing data across multiple containers or between containers and external storage systems.
Data synchronization is crucial for ensuring data consistency and availability across different containers. It involves keeping data up to date and consistent across multiple instances of an application running in different containers or on different nodes. Effective data synchronization ensures that all containers have access to the most recent and accurate data, enabling seamless collaboration and efficient application performance.
The market for effective data synchronization solutions for storage containers is driven by the need for reliable and scalable data management in containerized environments. As businesses increasingly adopt containerization, they require robust tools and technologies to manage and synchronize data across containers.
One of the key challenges in data synchronization for storage containers is ensuring data consistency in distributed systems. Containers are often deployed across multiple nodes or even different data centers, making it essential to have mechanisms in place to synchronize data across these distributed environments. Solutions that offer distributed data synchronization capabilities, such as distributed databases or distributed file systems, are gaining traction in the market.
Another challenge is the need for real-time data synchronization. In many applications, data needs to be synchronized in near real-time to ensure that all containers have access to the latest updates. This is particularly important in scenarios where multiple containers are processing data simultaneously or when containers need to share data with external systems. Real-time data synchronization solutions, such as event-driven architectures or streaming platforms, are becoming increasingly popular in the market.
Furthermore, data synchronization solutions for storage containers need to be scalable and flexible to accommodate the dynamic nature of containerized environments. Containers can be easily scaled up or down based on workload demands, and data synchronization solutions should be able to handle these changes seamlessly. Scalable data synchronization solutions, such as distributed data grids or data replication technologies, are in high demand.
The market for effective data synchronization for storage containers is also driven by the increasing adoption of hybrid and multi-cloud environments. Many businesses are leveraging multiple cloud providers or a combination of on-premises and cloud infrastructure for their containerized applications. Data synchronization solutions that can seamlessly synchronize data across different cloud platforms or hybrid environments are gaining significant traction.
In conclusion, the market for effective data synchronization for storage containers is experiencing rapid growth as businesses embrace containerization for their application development and deployment needs. The demand for reliable, scalable, and real-time data synchronization solutions is driving innovation in the market, with distributed data synchronization, real-time synchronization, and scalability being key focus areas. As containerization continues to evolve, the need for robust data synchronization solutions will only increase, making it an exciting and promising market for vendors and businesses alike.
The Tintri by DDN Inc invention works as follows
The method of performing data synchronization includes: receiving an instruction to synchronize the container with a snapshot. In this case, the container has first data and identity and the snapshot corresponds to second data.
![]()
Background for Effective data synchronization for Storage Containers
In some cases, an administrator may want to copy a snapshot’s state to a virtual computer. The administrator user might want to copy the snapshot state to use the data that is associated with it or to restore the virtual machine’s current state to the snapshot state. Some conventional systems allow copying of the state of snapshots by creating a copy of data for the virtual machines associated with the snapshot. This can be both time-consuming and inefficient. Copying the snapshot state will also replace the whole state of the virtual computer, including its “identity”. In many cases, this is not desirable.
The invention may be implemented in many ways. It can be used as an apparatus, a process, a system, a composition, a product of computer programming, and/or a CPU, such as one that executes instructions stored on or provided by a memory connected to the processor. These implementations and any other form of the invention can be called techniques in this specification. The invention allows for the possibility of altering the order of steps in disclosed processes. A component, such as a processor and a memory, described as being capable of performing a task can be implemented either as a general component that is temporarily set up to perform the task at a particular time or as a specific component that was manufactured to do the task. The term “processor” is used herein. The term “processor” refers to any one or more devices, circuits and/or processing cores that are designed to process data such as computer program instruction.
Below is a detailed description of some embodiments of the invention, along with accompanying figures that illustrate its principles. Although the invention is described with these embodiments in mind, it is not limited to them. The claims limit the scope of the invention, and the invention includes many alternatives, modifications, and equivalents. The following description provides a detailed understanding of the invention. These details are given for example purposes only. The invention can be used according to the claims without any or all of these details. To be clear, the technical material related to the invention that is well-known has not been described in detail. This is done in order not to obscure the invention.
Embodiments for efficient data synchronization of storage containers described in this document allow an administrator instantaneously to change the state of a container from its current state to any snapshot (e.g. a read-only version) while maintaining the ‘identity’ The container’s?identity? is preserved in various embodiments. In various embodiments, a storage ?container? Any identifiable set of information is referred to as a container. Containers include files, virtual disks (also called vdisks), and data objects. A container can be a file, a virtual disk (also referred to as “vdisk”). In different embodiments, a?identity’ is used. A container’s?identity” refers to the data or metadata that are associated with it. The storage system uses this information to customize and identify the container. The criteria used to determine the identity of a particular container can vary according to the embodiment. The identity of a file can be determined using its inode or file handle. A disk signature can be used to determine the identity of a virtual disk. The identity of a VM can be determined using a UUID and/or SID, stored by the hypervisor and/or the guest OS in the VM configuration and/or member vdisk. Customization can include, for instance, the name of a VM, the IP addresses that the VM uses to provide services or the rights to access various resources which are not directly a component of the VM.
Synchronization allows for a lot of flexibility, as a container can be synchronized with a snapshot from any other container within the system. In some embodiments a container containing a VM can be synchronized with any snapshot of that same type of VM. In some embodiments a container containing a VM can be synchronized with a snapshot of any VM type, where, for example the type or guest operating system that runs in the VM is determined, as well as the number and size vdisks within the VM. In some embodiments a container can be synchronized with a snapshot that is associated with another container. In some embodiments a container can be synchronized with a snapshot that is associated with the container itself, also known as “self-synchronization.
In the six examples below, the data state is synchronized with a snapshot and the identity of a container as perceived by the users of the storage systems is preserved. It appears to the user that only the contents of the container have changed following the synchronization.
Case 1: John accidentally corrupted his VM’s file system. To recover from this corruption, he synchronizes/restores his VM to the snapshot that was created last night for his VM.
Case 2. Sue has installed more than 1000 productivity applications on VM. Paul wants to have the same applications on his VM, but doesn’t want to spend time installing each application. To quickly get these productivity applications he synchronizes the application vdisk of his VM with the most recent snapshot of Sue’s vdisk. Paul’s vdisk now contains the productivity applications but retains its original identity. “, and not Sue’s vdisk.
Case 3. Pat created 500 development virtual machines for the Engineering organization based on the latest snapshot from a Fedora Virtual Machine. A month later, Fedora releases an important security update. Pat doesn’t want to create VMs manually for each engineer, nor does he wish to create new VMs. He applies the patch on the base VM and creates a snapshot. Then he synchronizes each development VM’s OS vdisk to this snapshot.
Case 4. Bill created 30 test and dev VMs before beta testing from a base VM that ran a database application. During beta-testing, the database of the production VM has been significantly updated. Bill wants each test and dev VM to be updated with the most recent version of the database now that the testing is over. To achieve this, Bill first takes a screenshot of the production VM and then synchronizes each test and dev VM’s database vdisk to this snapshot.
Case 5. The system administrator wants to replace a VM which offers a particular service, like a web or build server. With a newer version of the VM, which offers the same service. To accomplish this, he/she takes a screenshot of the new VM and then synchronizes it with the original VM. This replaces all the vdisks that were used by the original VM, but keeps the original VM’s identity.
Case 6. Michael upgrades the VM running an application. The upgrade did not go according to plan, and the VM’s state needs to be rolled-back to a previous state. Michael performs the rollback by synchronizing his application VM with the snapshot created before starting the upgrade.
In different embodiments, a signal is received for synchronizing a container with a first state of data and an identity into a second state of data corresponding to an image. The container is made to have the second state of data corresponding to a snapshot. After the container has been caused to be in the second data-state, the identity of the container will remain unchanged.
In some cases, after the synchronization has been completed, and the identity is still preserved as per the user’s opinion, it can be helpful to modify the identity. In these cases, the container’s identity can be changed to match the identity from the snapshot with which it is synchronized or to a different container that already exists or to a brand new identity.
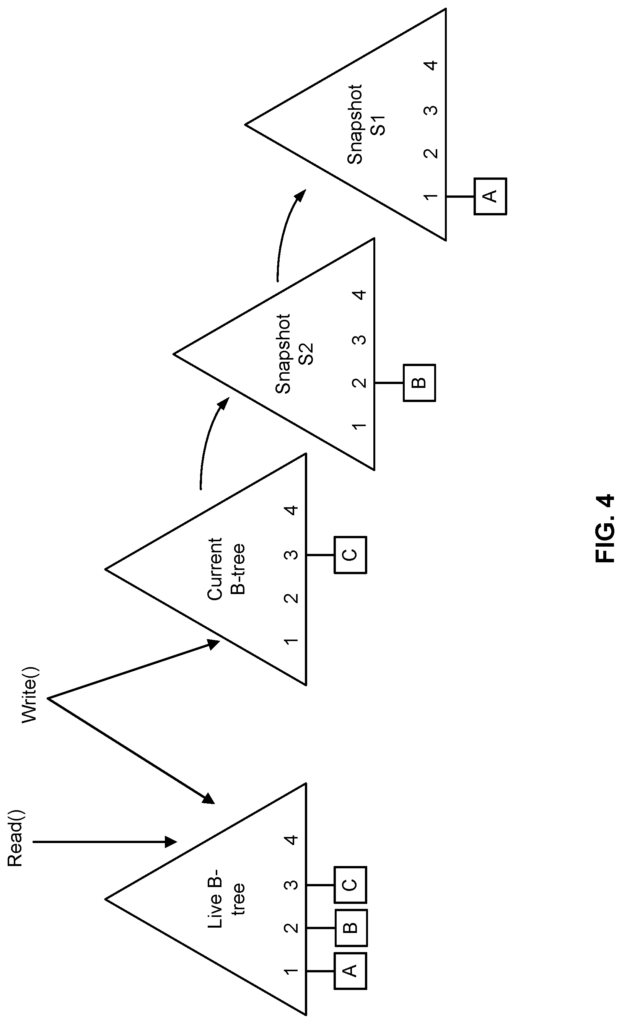
In various embodiments, the synchronization of data is done by a sequence of snapshots. In certain embodiments, the snapshot is a datastructure (e.g. a tree datastructure). A B-tree is an example of a data structure for a snapshot. A B-tree contains logical offsets which are mapped into physical offsets. A ‘user’ can then perform read and write operations using the logical offsets that are mapped to physical offsets in a snapshot. The logical offsets are then mapped into physical offsets to perform read and write operations. Physical offsets are then used to read or write data on the physical storage devices. Write operations update or create new mappings within a current B tree that represents the data state for a container, while read operations use the logical offset to determine the physical offset.
In different embodiments, the synchronization can be implemented by using sequences of B trees corresponding to snapshots. (Read-only copies).” The sequences may terminate with a B tree from another container or snapshot. In some embodiments, a B-tree encodes the data state of a container at a specific point in time efficiently by storing changes made between snapshots. Each snapshot B-tree, as will be explained in more detail below stores mappings only for those writes made to the container after the previous snapshot.
FIG. FIG. 1 shows an embodiment of a system of storage for VMs that uses virtual machine abstractions. In the example, system 100 comprises server 106 and network 104. Storage system 102 is also included. In some embodiments, the network 104 may include high-speed data networks or telecommunications systems. In certain embodiments, network 104 is used to communicate between storage system 102 and server 106. In some embodiments the file system used for storing VMs by using virtual machine abstractions does include network 104 and storage system 102 becomes a part of server 106. In some embodiments the server 106 can communicate with other storage systems than storage system 102.
In various embodiments, server 106 runs several VMs. In the example, VMs 108 and 110 (and other VMs), are running on server 106. A VM is a virtual machine (VM) that emulates a physical computer and executes the same programs as a real machine. A physical machine, such as a computer, can be configured to run multiple VMs. Each VM can run a different OS. As a result, multiple operating systems can run simultaneously and share resources on the same physical device. In some embodiments, a VM can span multiple physical machines and/or be moved from one machine to another (e.g. migrated). In some embodiments, a VM may include one or more virtual drives (vdisks), as well as other data related to that VM (e.g. configuration files, utility files, and files supporting functionality such a snapshots supported by the VM Management Infrastructure). To the guest operating systems running on a VM, a vdisk looks like a physical disk drive. In different embodiments, the contents of vdisks may be stored in one or more files. In some embodiments a VM Management Infrastructure (e.g. a hypervisor), creates files to store the contents of vdisks. The hypervisor, for example, may create a folder containing files that correspond to each VM. The hypervisor can create files that store, for example, the contents of a vdisk, the BIOS state of a VM, metadata and information about snapshots taken by the hypervisor, or configuration information specific to VMs. Data associated with a specific VM can be stored in one or more files on a storage device according to various embodiments. In some embodiments, files can be used as examples of virtual machine abstractions. “In some embodiments the files associated with (at minimum) VMs 108 110 and 112 running in server 106, are stored on storage system 102.
In various embodiments, the storage system 102 stores meta-information identifying what stored data objects (such as files or virtual machine abstractions) are associated with a particular VM or vdisk. Storage system 102, in various embodiments stores data from VMs that run on server 106. It also stores metadata which provides mapping or identification of the data objects associated with specific VMs. In some embodiments, the mapping or identification of a specific VM includes mappings to the files that are associated with the VM. Storage system 102 may also store a portion or all of the files that are associated with specific VMs. Storage system 102 can refer to one or more physical or software systems that are configured to work in conjunction to manage and store data. This includes files and other data objects. “In some embodiments, the hardware component used to implement (at least partially) the storage system can be either disk or Flash, or a mixture of both.
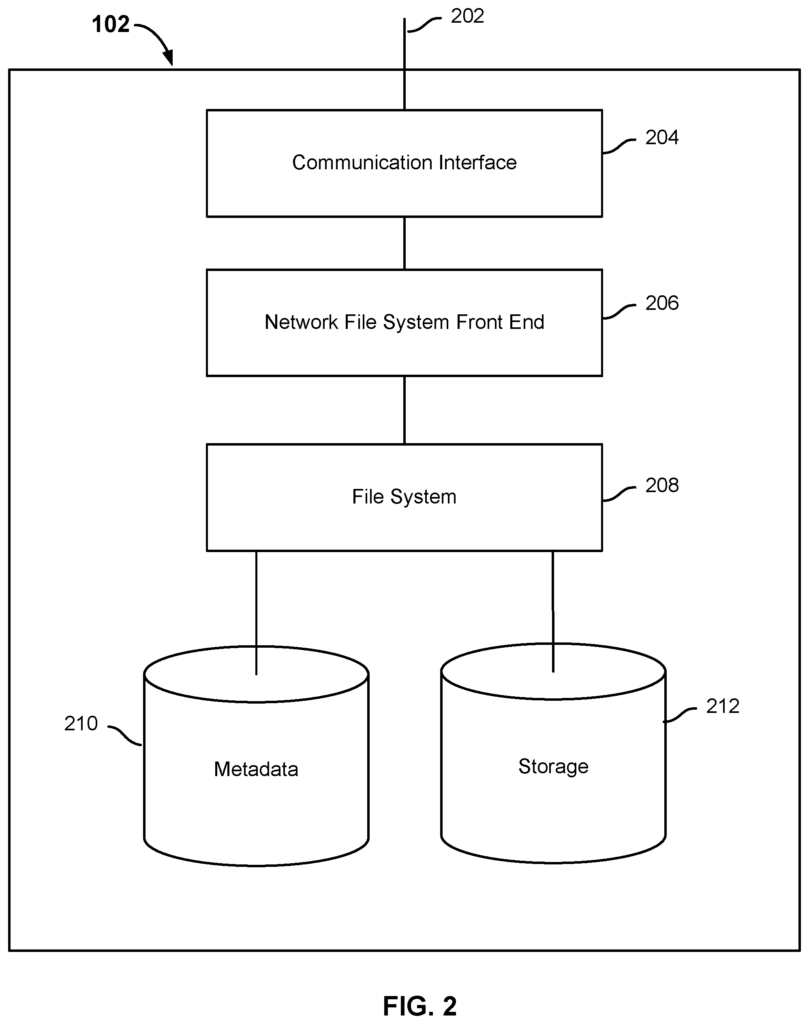
FIG. The block diagram of FIG. 2 shows an embodiment of a data storage system that includes metadata. Storage system 102, in the example, includes a networking connection 202, and a communication Interface 204 (such as a card network interface or another interface), which allow the system to connect to a Network such as the network 104 shown in FIG. 1. The storage system 102 also includes a front end for the network file system 206, which is configured to process NFS requests coming from virtual machines that run on systems like server 106 in FIG. 1. In different embodiments, the Network File System Front End is configured to associate NFS Requests as they are received and processed, with a virtual machine or vdisk that the request is associated with, for example using meta-information on the storage system 102, or elsewhere. Storage system 102 comprises a filesystem 208 that is configured and optimized for storing VM data. Metadata 210 in the example is a database or multiple databases that are configured to store metadata sets associated with different containers. Containers can be a VM or a vdisk. Storage 212 can include at least one tier. Storage 212 can include at least two storage tiers. The first tier may be a solid state drive (SSD), and the second, a hard disk or other disk storage. In some embodiments, metadata 210 may include at least one datastructure (e.g. B-tree), which includes mappings for storage 212 locations at which data from a container associated with metadata 210 is stored. In some embodiments a set metadata stored at metadata includes at least one B-tree which is a snapshot of data in storage 212 that corresponds to a container state at an earlier time. In some embodiments an identity for a container, whose data is stored in the storage 212, comprises metadata stored at metadata and/or storage data.
![]()
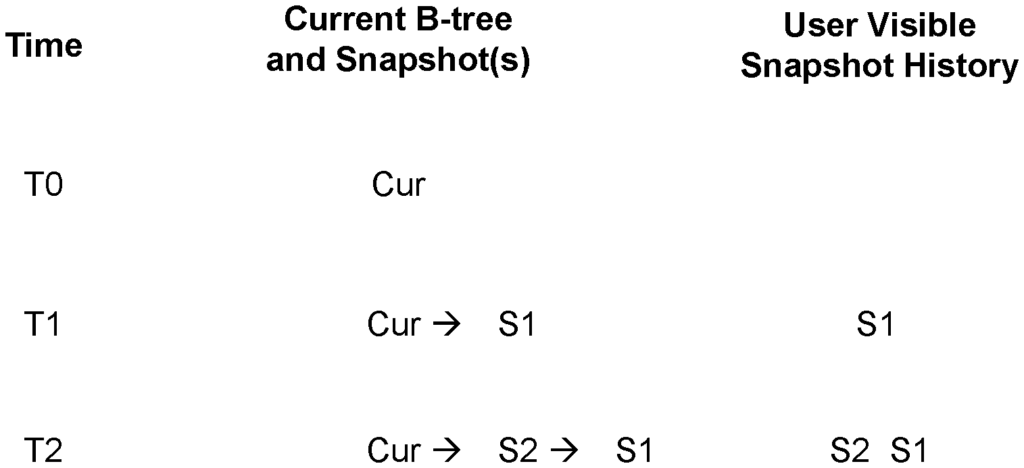
In certain embodiments, metadata stored in metadata 210 include at least one special data structure. (This is also referred to as an ‘user history data structure? The snapshots are associated with the container, whose data are stored in storage 212. The user history data structures stores data that indicates which snapshots are stored with the container. This includes snapshots taken before and/or following one or more synchronizations. The user history data structure of a container may store data that indicates snapshots included in a visible user history. This is displayed to the user via a user interface.
Click here to view the patent on Google Patents.
Leave a Reply