Invented by Dima Kislovskiy, David McAllister Bradley, Uber Technologies Inc
Individualized risk routing refers to the ability to provide real-time, personalized routing recommendations to drivers based on their specific risk factors. These risk factors can include weather conditions, traffic congestion, road construction, and even personal driving habits. By taking these factors into account, drivers can be directed to the safest and most efficient routes, minimizing the risk of accidents and improving overall road safety.
One of the key drivers behind the growing market for individualized risk routing is the increasing availability of data. With the proliferation of smartphones and connected vehicles, there is a wealth of information that can be collected and analyzed to provide personalized routing recommendations. This data can include real-time traffic updates, weather conditions, and even driver behavior patterns.
Companies specializing in individualized risk routing are leveraging this data to develop sophisticated algorithms and predictive models. These models can analyze various risk factors and provide drivers with real-time recommendations on the safest and most efficient routes. For example, if there is heavy rain and a high probability of hydroplaning, the system can reroute drivers to avoid areas prone to flooding or slippery road conditions.
The market for individualized risk routing is not limited to personal vehicles. Commercial fleets, such as delivery trucks and rideshare services, can also benefit from these technologies. By optimizing routes based on risk factors, companies can reduce fuel consumption, improve delivery times, and enhance driver safety.
Furthermore, insurance companies are also showing interest in individualized risk routing. By encouraging their policyholders to use these technologies, insurance companies can gain valuable insights into driver behavior and risk profiles. This data can then be used to offer personalized insurance plans and pricing, rewarding safe drivers and incentivizing others to improve their driving habits.
However, there are challenges that need to be addressed for the market to reach its full potential. Privacy concerns surrounding the collection and use of personal data need to be addressed to ensure that individuals feel comfortable sharing their information. Additionally, the accuracy and reliability of the algorithms and predictive models need to be continuously improved to provide accurate routing recommendations.
In conclusion, the market for individualized risk routing for human drivers is a promising and rapidly growing sector. With advancements in technology and the increasing availability of data, personalized routing recommendations based on individual risk factors can significantly improve road safety and efficiency. As the transportation landscape continues to evolve, individualized risk routing will play a crucial role in ensuring the safety and well-being of human drivers.
The Uber Technologies Inc invention works as follows
A transportation system can maintain driver logs of drivers who operate in a certain region. Each driver log will indicate the driving characteristics of that driver. The system can identify a driver’s destination and a set routes from the initial location to their destination. The system can, based at least partly on the driving habits of the driver, determine an individual risk value. It then selects the optimal route for that driver from the set.
Background for Individualized Risk Routing for Human Drivers
The path to autonomous vehicles (AVs) being ubiquitous on public highways and roads has been highly experimented across many entity types. These include educational institutions, automobile companies, and high-tech business entities. The AV testing currently focuses on the hardware, such as sensors and computational resources required for safe AV operation on public roads, as well as software developments in perception, object classification, path prediction and control input responses, (e.g. steering, braking and acceleration inputs). The monetization has been limited by a gradual progression in autonomy features offered by certain automakers. From active cruise control to lane-keeping and following features, as well as automated parking and brake features developed by certain manufacturers.
In 2016, the number of deaths in motor vehicles was 40,000, mainly because of speeding, drunk driving and distracted driving. In the automotive and science communities, it is widely acknowledged that driver-assistance technologies and autonomous driving can reduce vehicle-related deaths and accidents. The wasted time and productivity costs associated with long commutes could also be reduced or eliminated when self-driving vehicles become ubiquitous in urban sprawls. But widespread acceptance can only come from real-world, proven results, such as logged mileage, and a convincing and indisputable safety record.
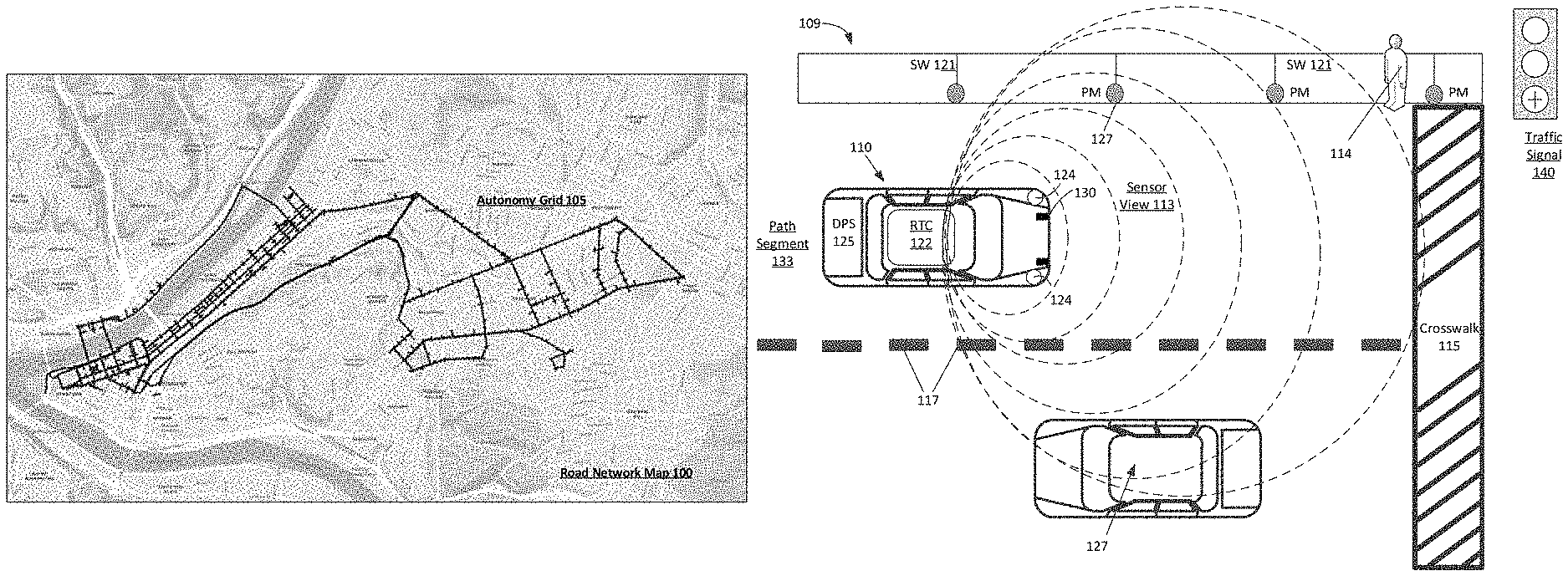
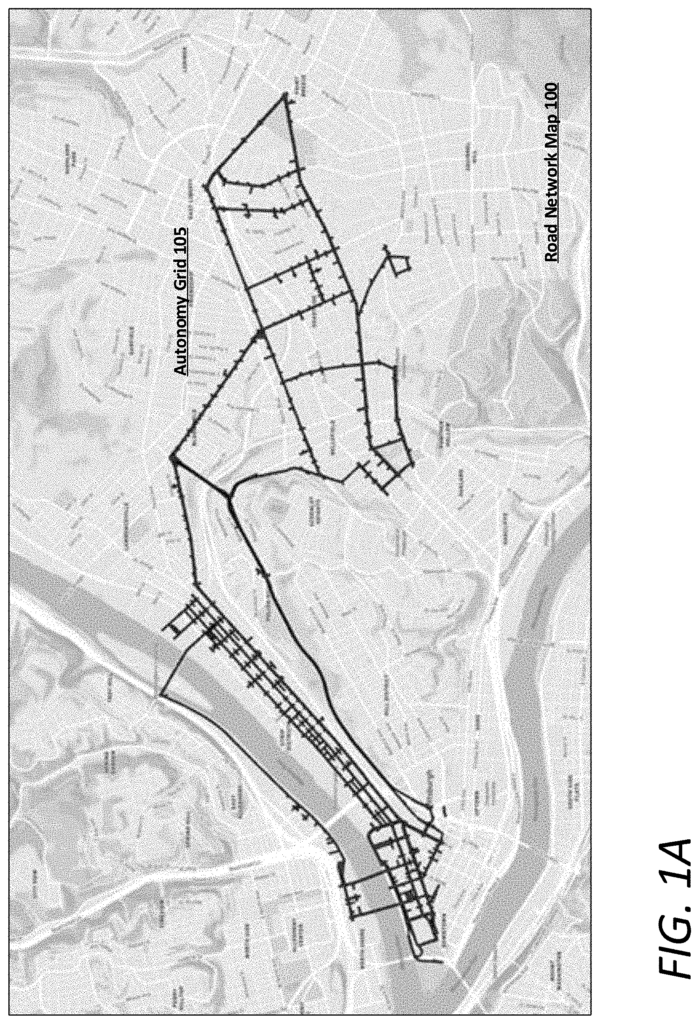
A travel-path system for a region (e.g. a road network in a metropolitan area such as greater Pittsburgh, Pa.) can be analysed on a high level and mapped based on ground truth data recorded by vehicles with sensor systems (e.g. LIDAR and stereo cameras). The network of travel paths can be divided into lanes and pathways that are capable in the area for AV operation. The capability-in scope path segments can then be determined at a high-level based on factors such as lane geometry and intersection complexity. The capability-in scope path segments may also be conditionally and temporally sensitive. For instance, certain segments of a path can only be used for AV operations at certain times, such as during the day, night, or weather conditions. The capability-in scope paths can first be determined by humans and then refined or expanded computationally using risk regression methods and trip classification methods.
Alternatively or additionally, the capability in scope lanes and path can be determined by ground truth mapping and labels, and heuristically, through lower-level computational analysis of AV data from AVs travelling throughout the region. For example, logs from AVs may be processed by a risk regressor trained to calculate a fractional quantity of risk for an AV on any given segment. Higher risk segments can then be set aside or eliminated for future software development. The resultant lanes and path can be a grid of highly labeled and mapped paths (e.g. recorded localization maps for each lane) that provides low predicted risk for the AV operation.
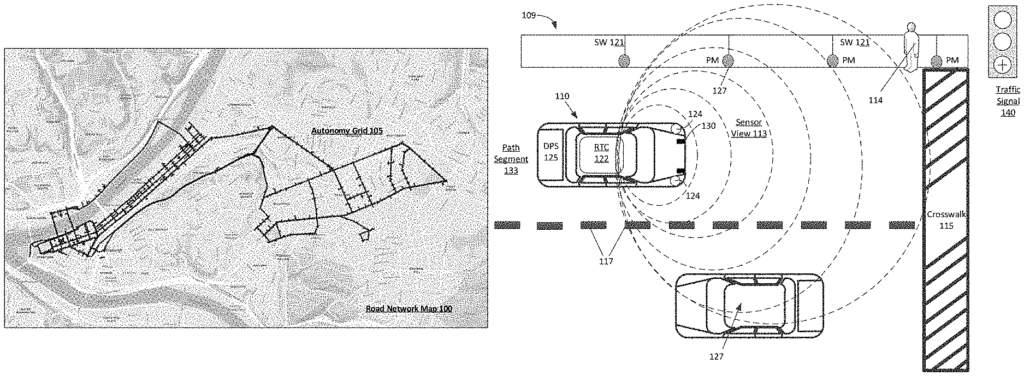
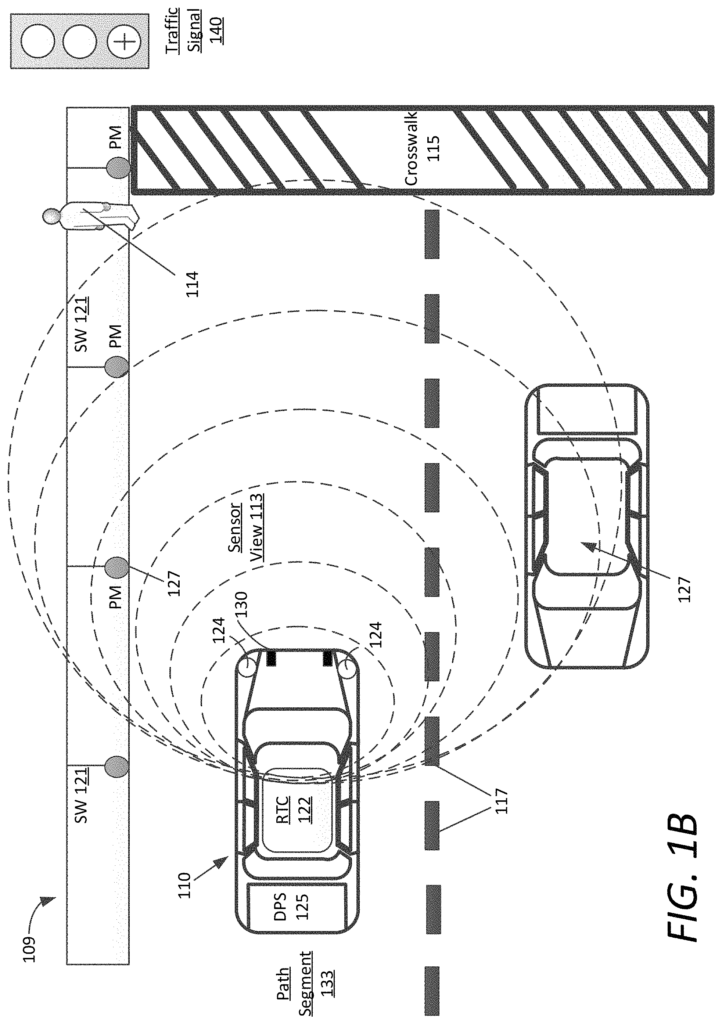
As provided in this document, a “path segment” is a vehicle-accessible segment of paved or unpaved road. A paved road, an unpaved road, or a segment off-road that can be used by vehicles can all comprise a “path segment”. This can also include paths predetermined over land, on water, under the sea, and in the air. A ‘path’ is a series of connected path segments that can be traversed by a vehicle. A ‘path’ can be any connected sequence of path segments that can be traversed by a vehicle. It can also include any combination of land and aerial path segments. A ‘driver’ is a person who operates a vehicle. A ‘driver’ can be anyone who operates a vehicle. This could include an aerial vehicle or vehicle that is typically used on the road or off-road, or even a marine vessel. Furthermore, a ?lane segment? A typical paved road within a network of roads can have a predetermined distance (e.g. two hundred meters) or can be derived from a segment between intersections. A ?road segment? A?road segment? can consist of multiple individual lane sections (e.g. a left lane and a right one) with a common direction. A total path of an AV can consist of a set of sequential capability-in scope lane segments, from the start point to the end point, with each segment having a fractional risk quantity calculated using a risk regression based on static conditions and dynamic conditions.
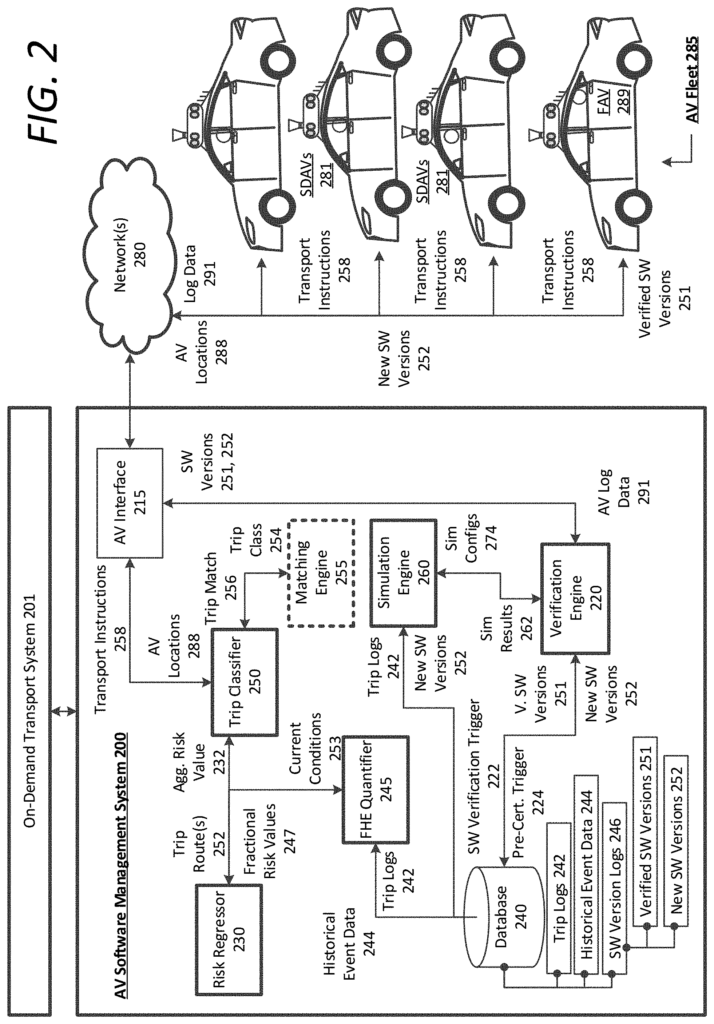
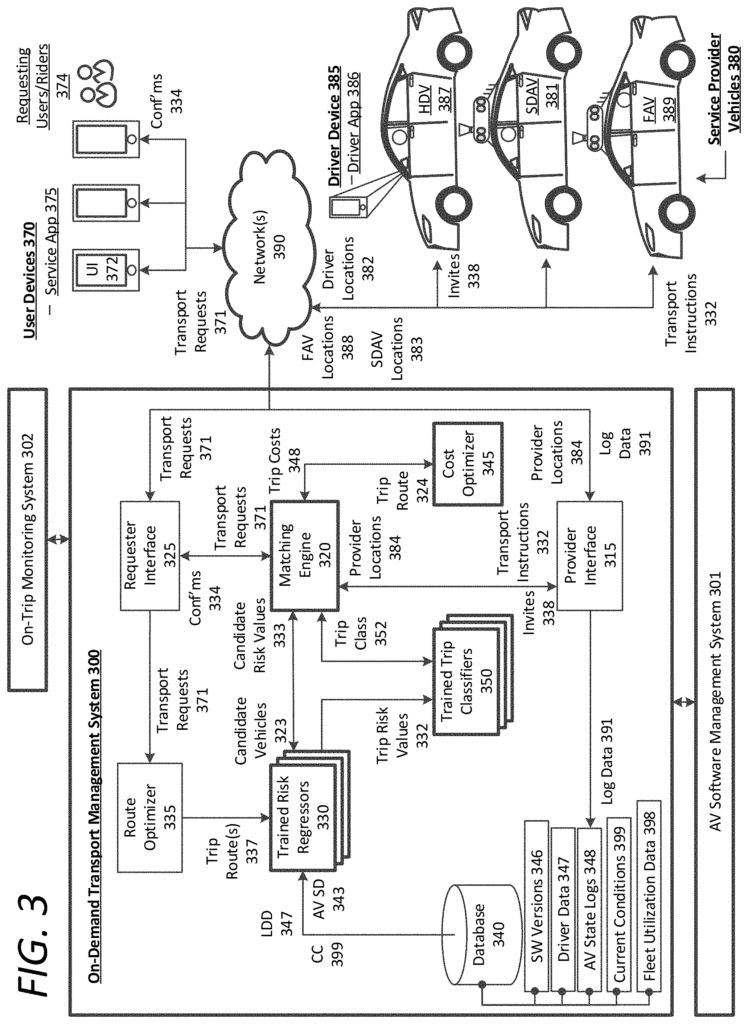
The present disclosure describes techniques for calculating risk and classifying trips between human-only-driven vehicles (HDVs), autonomous vehicles having safety drivers (SDAVs), or fully autonomous autonomous vehicles without safety drivers (FAVs). The present disclosure also describes an on-demand management system for managing on-demand services that link available drivers of human-only driven vehicles (HDVs), autonomous vehicles with trained safety drivers (SDAVs), or fully autonomous self-driving cars without a safety driver (FAVs).
The on-demand transportation management system (or “transport system”) can receive requests for transport from requesting users via a designated rider application that executes on the users’ computing devices. The designated rider application on the computing device of the user can receive transportation requests from users. The transport management system may receive a request for transportation and determine a number of nearby vehicles that are available to the user. The transport system can then select a HDV, SDAV or FAV that is available to service the request, based on various criteria, such as risk, estimated arrival time (ETA) at the pickup location, expected earnings per candidate vehicle and so forth. The transport request may include an on-demand ride-share, high-capacity vehicles, luxury vehicles, professional drivers, requests for AV transportation or item deliveries (e.g. food or packages). Transport requests can also be any request for general transportation, which does not specify the category or type of transportation.
According to the examples presented here, a transport system can match vehicles based on a transport request received from a user. The matching operation may include identifying a list of candidate vehicles using techniques such as risk regression, trip classification, business optimization, and other parameters described in this document, before selecting the optimal vehicle for the transport request. The transport system will then select from HDVs or SDAVs and/or FAVs in order to transport the user to the destination specified in the transport request. The examples described herein can leverage SDAVs for testing and verifying software releases for eventual post-verification on FAVs in order to progress towards FAV ubiquity.
As described in this article, a “risk regressor” is a tool that can be used to predict risk. or ?risk regression engine? Machine learning techniques and/or algorithmic methods to compute fractional risks quantities for any path segment in a region can be described interchangeably. (e.g. a certain probability of an event occurring for any traversal of the specified lane on a road segment, between intersections.) A risk regressor can also factor in the current environment (e.g. rain, snow or clouds), as well as static risk factors based on traffic conditions and lane geometry. These fractional risk quantities may be generalized to human driving or they can be specific to AVs and/or software versions.
Accordingly an example risk regression may compute an individual fractional risk quantity per path segment based on the attributes of a vehicle or driver, such as hardware and software on board, an AV’s state determined by vehicle telemetry data or diagnostics, or driving characteristics, safety history and current state. As described in this document, some examples of a risk regressor are specific to software releases executable by AVs. A routing engine can also determine routes for a transport request made by a user. The risk regressor will then determine the aggregate risk quantity of each route based on the current or anticipated conditions (e.g. conditions when the vehicle crosses a certain path segment) and can provide the lowest risk route, or another optimal route. As output, the trip classifier or vehicle matching engine can pair the requesting user to an available vehicle.
As described herein, the ‘trip classifier’ is a? or ?trip classification engine? The terms “machine learning” and “algorithms” are interchangeable throughout the disclosure. They describe algorithms and machine-learning techniques that classify any overall route or path between an initial location to a destination based on an estimated aggregate risk quantity or calculated in another way by a risk regression. As an example, the trip classifier may receive as input one or more routes, and aggregate risk quantities (determined by a risk regression) for each route. In some variations, the trip classifier can receive additional inputs, such as the expected earnings or profitability of a specific vehicle class servicing the trip under current conditions. The trip classifier may include a variety of elements in its classification, including the software version authorized for the entire route of a journey (e.g. verified software releases, or new, untested software releases on board AVs), as well as the types of vehicles that are authorized to service the itinerary (e.g. SDAV, HDV, FAV), among others. The trip classifier, using the total risk of the route or path, can determine the threshold requirements for vehicles to fulfill a specific transport request. This allows the trip classifier to identify a list of candidates that can meet the transport request. Then, a matching engine for vehicles can choose the most optimal vehicle that will service the request.
As provided in this document, a “software release” is a: “As provided herein, a?software release? Any software update that can be executed by an AV, for any reason. Examples of reasons to release new software include: hardware updates for AVs; altering perception, vehicle control, or prediction behavior by the AVS; expanding the autonomy grid operations, providing updated or new localization maps to AVs and more. Each software release can be paired up with a specific trip classifier in various examples (e.g. a software release and trip classifier pair that cannot be used by other software releases or trip classifiers). When a new software release is created, it can be pre-certified using a series of simulations. These include full log set simulations based on previously verified software and log data of actual AV trips. Other simulations may include edge case Monte Carlo, plan-based analysis, and simulation analyses capable of adjusting the simulation parameters (e.g. simulating failure conditions and faults) and including additional actors (e.g. other vehicles or pedestrians). Simulations can verify a new release of software for FAV use in some cases (e.g. a minor change to the AV’s behavior at a specific location, like a blind turn). Pre-certification by simulation analysis allows software training systems to be described to distribute precertified software releases to SDAVs to log mileage and eventually verify. In addition, the examples described can use recorded log data of AVs running software through a series of scenarios or tests in a controlled environment.
Verification is equivalent to authorizing a software release on FAVs, without the requirement of a safety driver. As described in this document, FAVs will only be able to operate with verified software versions. However, there are some limited exceptions. Verification of a software release occurs when a confidence level is reached (e.g. 95% confidence in the software release’s safety compared to an average driver on a collection of road kilometers under nominally equivalent driving circumstances). As described in this document, verification thresholds can also be adjusted or determined based on the simulation results of pre-certification testing and/or real world testing. As an example, a software release can be AV-tested under a range of driving conditions or a set of defined conditions (e.g. on test tracks).
Examples presented herein can refer to software training techniques that are based on machine learning, neural network, artificial intelligence and similar technologies. Some examples described herein involve training a new trip classifier or risk regressor. This training can be supervised or non-supervised machine learning methods that accurately quantify the fractional risk of traversing a given path segment using historical data on harmful events and/or data from other sensor systems, such as driver computing devices and AV logs. This training can also correspond to unsupervised or supervised machine learning methods that accurately classify a route based on a risk aggregate quantity.
Among other advantages, the examples described in this document achieve a technical result of safely expanding autonomous vehicles operations through dynamic risks analysis, trip classification, and robust software validation. In various examples, the on demand transportation management system may be used in conjunction with a AV training system and an on-trip monitoring to provide on-demand services to users who request them with a goal to evaluate AV software with high standards of verification for execution by FAVs. “The multi-pronged approach described in the present disclosure provides beneficial linkages between a current on-demand transport service platform that involves HDVs and SDAVs. The SDAVs can be used for AV testing and verification and deployed as a fleet of verified FAVs.
As used herein, “a computing device” refers to devices such as desktop computers, mobile devices (such as smartphones), laptop computers, tablets, virtual reality devices (VR), augmented reality devices (AR), wearable computing devices (such as televisions (IP Television), and so on, which can provide network connectivity, and processing resources, for communicating with the network. A computing device may also be custom hardware, on-board computers or in-vehicle units. The computing device may also run a specific application that is configured to communicate with a network service.
One or more of the examples described herein provides that methods, technologies, and actions performed on a computing device can be performed programmatically or by computer-implemented methods. As used in this document, programming means using code or computer executable instructions. These instructions may be stored on one or more memory resources within the computing device. “A programmatically performed action may or may be automatic.
One or more of the examples described in this document can be implemented by using programmatic engines, modules, or components. A programmatic engine, component, or module can be a part of a larger program, a section of a bigger program, software, hardware, or even a subroutine. A module or component may exist independently on a component of hardware. A module or component may also be an element or process that is shared by other modules, machines, or programs.
Some examples described in this document can require computing devices to be used, including memory and processing resources. One or more of the examples described in this document may be implemented in part or whole on computing devices, such as desktop computers, servers, smartphones, PDAs, laptop computers, virtual or augmented reality computers (AR), network equipment, routers, and tablet devices. Memory, processing and network resources can all be used to establish, use or perform any example described in this document (including the performance of a method or the implementation of a system).
Furthermore one or several examples described herein can be implemented by using instructions that can be executed by one or multiple processors. These instructions can be stored on a nontransitory computer readable medium. The machines shown in the figures and descriptions below are examples of computer-readable media and processing resources on which instructions to implement examples disclosed herein may be stored and/or carried. The numerous machines that are shown in the examples of the invention have processors, and different forms of memory to store data and instructions. Permanent memory storage devices such as hard disks on servers or personal computers are examples of non-transitory, computer-readable media. Computer storage mediums can also include magnetic memory, CD/DVD units, and portable storage devices such as smartphones, tablets, or multifunctional devices. Computers, terminals and network-enabled devices (e.g. mobile devices such as cell phone) are examples of devices and machines that use processors, memory and instructions stored on computer readable mediums. Examples can also be implemented as computer-programs or computer-usable carrier media capable of carrying a such program.
As provided in this document, the term “autonomous vehicle” is used. (AV) is a term used to describe any vehicle that operates in an autonomous state with regard to acceleration, steering and braking as well as auxiliary controls such as lights and direction signaling. There are different levels of autonomy for AVs. Some vehicles, for example, may be able to control themselves in certain scenarios, like on highways. Advanced AVs such as the ones described here can operate in different traffic environments without human assistance. An ‘AV control system’ is therefore required. The AV control system can use sensor data to modulate the acceleration, steering and braking inputs.
Click here to view the patent on Google Patents.
Leave a Reply