Invented by Ryan S. Keisler, Rick S. Chartrand, Xander H. Rudelis, Descartes Labs Inc
Iterative relabeling using spectral neighborhoods is a technique that leverages spectral clustering algorithms to improve the accuracy and efficiency of data labeling. Spectral clustering is a powerful tool for grouping data points based on their spectral properties, which can reveal underlying patterns and structures in the data. By applying this technique iteratively, the relabeling process becomes more refined and precise over time.
One of the key advantages of iterative relabeling using spectral neighborhoods is its ability to handle complex and high-dimensional datasets. Traditional labeling methods may struggle to accurately classify data points in such scenarios, leading to suboptimal results. However, by incorporating spectral clustering, this approach can effectively capture the intricate relationships between data points and assign them to appropriate labels.
The healthcare industry has been quick to adopt iterative relabeling using spectral neighborhoods. Medical data, such as patient records and diagnostic images, are often vast and complex. Accurate labeling of this data is crucial for tasks like disease diagnosis, treatment planning, and drug discovery. By utilizing spectral clustering algorithms, healthcare professionals can improve the accuracy of their diagnoses and make more informed decisions.
In the finance sector, iterative relabeling using spectral neighborhoods has found applications in fraud detection, risk assessment, and algorithmic trading. Financial data is characterized by its high volume and volatility, making it challenging to label accurately. However, by leveraging spectral clustering, financial institutions can identify patterns and anomalies in the data, leading to more effective fraud prevention and risk management strategies.
The technology industry has also recognized the potential of iterative relabeling using spectral neighborhoods. Companies working on machine learning, natural language processing, and computer vision tasks can benefit greatly from this approach. By iteratively refining the labeling process, these companies can improve the performance of their models, leading to more accurate predictions and better user experiences.
The market for iterative relabeling using spectral neighborhoods is expected to continue growing in the coming years. As more industries realize the value of accurate data labeling, the demand for innovative techniques like this will increase. Additionally, advancements in machine learning algorithms and computing power will further enhance the capabilities of iterative relabeling using spectral neighborhoods.
However, challenges remain in terms of scalability and interpretability. While spectral clustering algorithms offer powerful insights into the underlying structure of data, they can be computationally expensive and difficult to interpret. Researchers and developers are actively working on addressing these challenges to make iterative relabeling using spectral neighborhoods more accessible and user-friendly.
In conclusion, the market for iterative relabeling using spectral neighborhoods is expanding rapidly, driven by the need for accurate and efficient data labeling in various industries. This approach offers significant advantages over traditional labeling methods, particularly for complex and high-dimensional datasets. As technology continues to advance, iterative relabeling using spectral neighborhoods will play a crucial role in unlocking the full potential of data-driven decision-making.
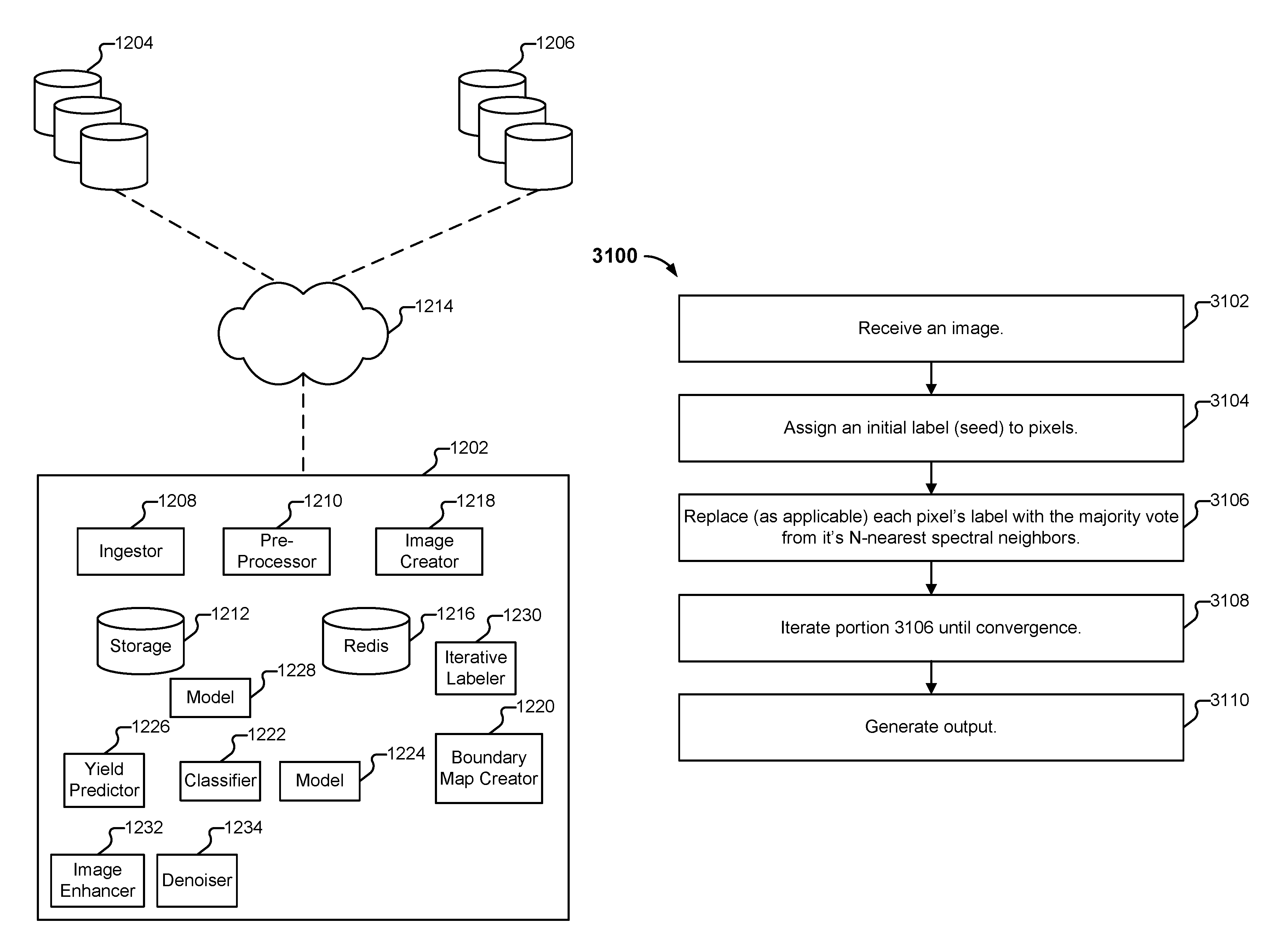
The Descartes Labs Inc invention works as follows
A first picture is received.” At least some pixels of the first image are assigned an initial label, for example by assigning a label to the first pixel. The first pixel label is replaced by a new label. The label of the first pixel is changed to reflect the new label.
Background for Iterative relabeling using spectral neighborhoods
A pixel represents the smallest resolvable area by an imaging sensor. In some cases, it’s desirable to have the smallest possible area. Some applications, like land-use classifications, work on a much larger scale. For example, the agricultural land usage will be uniform across a farmer’s entire property. This will occupy many pixels on a satellite picture. In such large-scale applications, it is often both/or (1) computationally expensive and (2) inaccurate to operate at the pixel level. The sheer size of the observational datasets can make processing challenges even more difficult. There is a constant need for systems and technologies that can process imagery data efficiently and accurately.
The invention may be implemented in many ways. It can be used as an apparatus, a process, a system, a composition, a product of computer programming, and/or a CPU, such as one that executes instructions stored on or provided by a memory connected to the processor. These implementations and any other form of the invention can be called techniques in this specification. The invention allows for the possibility of altering the order of steps in disclosed processes. A component, such as a processor and a memory, described as being capable of performing a task can be implemented either as a general component that is temporarily set up to perform the task at a particular time or as a specific component that was manufactured to do the task. The term “processor” is used herein. The term “processor” refers to any one or more devices, circuits and/or processing cores that are designed to process data such as computer program instruction.
Below is a detailed description of some embodiments of the invention, along with accompanying figures that illustrate its principles. Although the invention is described with these embodiments in mind, it is not limited to them. The claims limit the scope of the invention, and the invention includes many alternatives, modifications, and equivalents. The following description provides a detailed understanding of the invention. These details are given for example purposes only. The invention can be used according to the claims without any or all of these details. To be clear, the technical material related to the invention that is well-known has not been described in detail. This is done in order not to obscure the invention.
I. Overview
A. Overview Example Data Sources
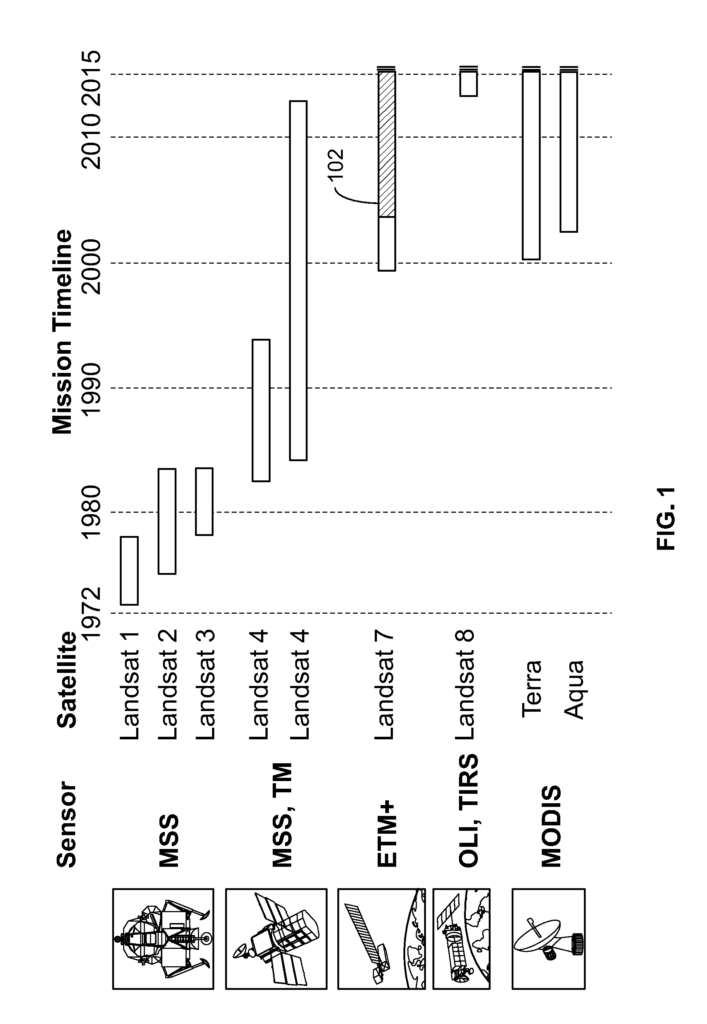
The NASA/USGS Landsat program has routinely collected approximately monthly snapshots of the world’s land surface since 1972. The Landsat program has evolved over its lifetime, with the eight Landsat satellites hosting a series of moderate-resolution multispectral imaging systems, from the Multispectral Scanner (MSS), to the Thematic Mapper (TM) and Enhanced Thematic Mapper (ETM+), and most recently the Operational Land Imager (OLI) and Thermal Infrared Sensor (TIRS). FIG. 1 shows NASA/USGS Landsat and MODIS satellites and sensors providing data that can be processed using embodiments of techniques described herein. Landsat 6 failed on launch, and a failure in the Landsat 7 scanline corrector (SLC) is indicated in region 102. Complementing the Landsat program is a range of lower-spatial resolution systems optimized for daily global imaging, of which the most widely used is the Moderate Resolution Imaging Spectroradiometer (MODIS) instrument on the NASA satellites EOS Terra (launched 1999) and Aqua (launched 2002). Landsat and MODIS are two examples of sources of observational data. Other sources can also be processed/analyzed in addition to/instead of Landsat/MODIS data in accordance with various embodiments. For example, observational data collected from other constellations (e.g., PlanetScope, RapidEye, Dove, Sentinel-1, and Sentinel-2), as well as higher-resolution imagery (e.g., collected via airplane/drones) can also be used in accordance with embodiments of techniques described herein.
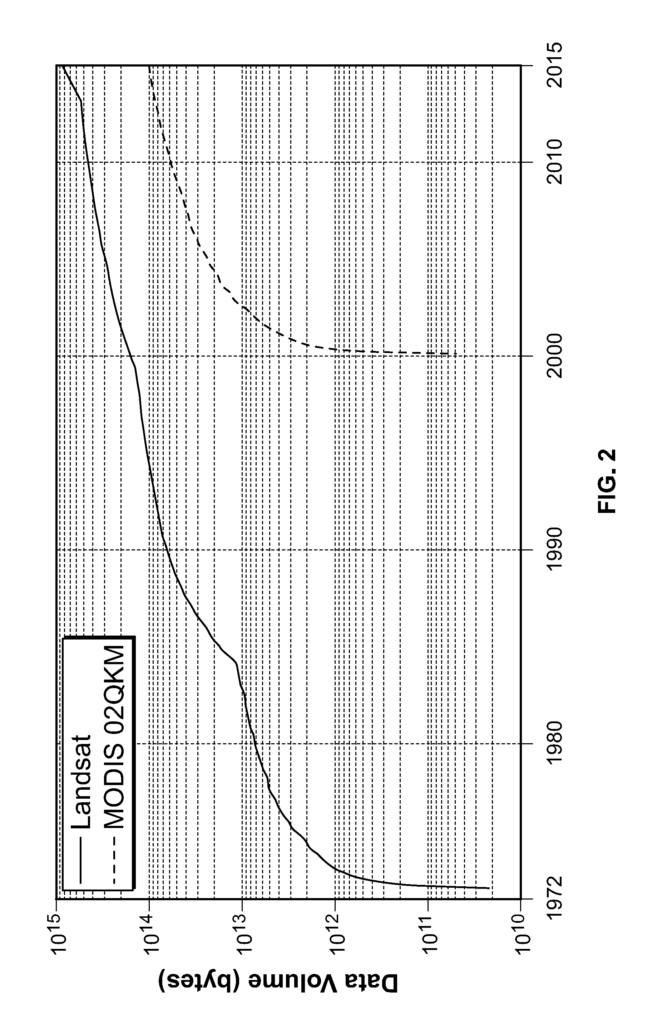
Google Earth Engine and Amazon-NASA Earth Exchange have stored historical Landsat data and MODIS data in cloud storage that is freely accessible. They continue to do so. This data is usually provided in a format that requires more processing and storage resources than necessary. It can also prevent certain forms of analysis. As an example, bzip-compressed tar files are often used to store this type of imagery and prevent random access to their data. If answering a particular question requires the access to all the data in a small area (e.g. tens or hundreds of kilometers), then more than 1,000 large image files covering 185 km will need to be decompressed and then spatially divided to fit in the memory of the processing node. If, however, as described below, the data are provided in a tiled multi-resolution format, then only the data that is of interest must be accessed. This reduces the cost and complexity.
B. Overview Infrastructure
1. Hardware
A number of infrastructure approaches can be used to handle data on a petabyte-scale. Installing and maintaining a computing center is one option. This approach has the disadvantage that resources are wasted when the workload is small and the peak demand is high. This approach also requires a thorough understanding of how to build and configure the hardware and software environments, before determining the exact resources needed to solve the problem. This solution could also require a long-term commitment because there isn’t much of a market available for supercomputers that are slightly used.
A second option would be to use supercomputing resources shared by other people (e.g. provided by a company, university or national supercomputing center). Supercomputing systems with more than 10,000 processor cores are available in hundreds of installations. Unfortunately, storage and networking resources aren’t readily available. The difficulty in transferring data from a supercomputer to a parallel system to be processed is limiting the ability to process very large datasets. “At the typical transfer rate of supercomputing centers, retrieving one petabyte over the Internet from an archived storage location could take up to a month.
Another question is how to store data as it is collected.” The parallel file systems, Lustre and Panasas (commonly attached to supercomputers), are designed for high performance and their cost limits their usefulness for long-term storage. Typically, they are reserved for temporary scratch storage. Magnetic tapes, which are cheaper archival storage options, are available but not designed for the use case where a petabyte of data is being staged onto a parallel store. Another issue is how to continue analysis or distribute results once a large processing run is complete. “Supercomputing centres do not typically provide an environment that is conducive to interactive data analysis or visualization. Additionally, additional infrastructure for web-enabled access to large quantities of processed data could run afoul with traditional security models.
Instead of buying dedicated hardware or performing calculations at a supercomputing facility, a different approach is to use public cloud computing resources. Cloud computing is a step further in the commoditization and commodification of computational resources. It offers benefits such as agility, elasticity, reliability, and scalability. Cloud computing’s pay-as you-go model encourages transparency in resource costs and allows for free-market economic feedback cycles that are suppressed by the traditional supercomputing environments. Google Compute Engine is the Infrastructure as a Service component of Google Cloud Platform. The techniques can be adapted to other platforms, including those provided by companies outside of Google.
Google Compute Engine was made generally available in December 2013 and provides virtual machines that use KVM as hypervisor. In FIGS, benchmarks comparing its node performance with a previous Beowulf Architecture and a more recent HPC Architecture are shown. FIGS. 3A and 3. FIG. 3A displays bandwidth and latency data for a Google Compute Engine. The latency of small messages is 85 microseconds while the bandwidth for large messages reaches 7 Gigabits/second. FIG. 3B compares a Beowulf cluster from 2003 that was a finalist for the Gordon Bell prize based on price and performance to a Cray XE6 Node in 2015, as well as the Cloud’s performance. The first set of results are memory bandwidth, measured by the STREAM Benchmark in Mbytes/s. The middle line is Class C NAS parallel benchmarks in Mop/s. And the last row is Linpack Gflop/s. Beowulf is per CPU for a 2.53GHz Intel Pentium 4 processor. Cloud results are per core HW on a 16-core Haswell node at 2.3 GHz. Cray results per Bulldozer computing unit on a dual socket XE6 with two AMD Interlagos model 6275 2.3 GHz processors (16 cores in total). The data shows that the performance per core for un-tuned apps has not changed much in the last 12 years (between factors of one and eight, with most of these benchmarks being around a factor three).
In FIG. 3C, a brief summary of computing costs examples is presented. 3C. These values were derived from Google Cloud Platform published pricing and performance examples taken in April 2015. These numbers are rough estimates. Discounts can be obtained on certain workloads. To make it easier to estimate total costs, commodity bandwidths and capacity have been converted into a cost-per-second per giga unit. Cloud Storage, for example, costs $315,000 to store one petabyte (1,000,000 gigabytes) over a year (31.5 millions seconds). “One dollar can buy a minute’s worth of programming work, 8 Gigabytes on the Internet, a gigabyte stored in DRAM for a week or 1015 floating-point operations.
Many lessons learned from supercomputing in the past remain relevant for cloud computing, with a translation of architectural components. (For example, memory can be transformed into a key-value storage, and the CPU is the entire compute node). The efficiency of a “Big Iron” is based on the CPU. Cloud computing is limited by the network connections between processing nodes and storage. Techniques for “cache-friendly” systems. Cloud architectures can benefit from techniques developed for?cache-friendly? In FIG., we see an illustration of the comparison between supercomputers (supercomputers) and cloud computing. 4.
For the remainder of the Specification, reference will generally be made to various techniques being deployed using cloud computing resources. However, traditional standalone hardware can also be used, and the techniques described herein adapted as applicable. FIG. 12 (described in more detail below) depicts an example environment for processing and analyzing data in accordance with techniques described herein. As explained throughout the Specification, platform 1202 (and/or various elements thereof) can be implemented using traditional server hardware, and can also be implemented using cloud computing resources. Various elements of the environment shown in FIG. 12 are depicted as individual units (e.g., ingestor 1208 and pre-processor 1210). It is to be understood that such elements need not be implemented on a single node, but can also be implemented across multiple nodes configured to cooperate to perform tasks (e.g., leveraging various industry standard cloud computing techniques, as well as various approaches described herein). Further, whenever platform 1202 is described as performing a task, a single component, a subset of components, or all components of platform 1202 may cooperate to perform the task. Similarly, whenever a component of platform 1202 is described as performing a task, a subcomponent may perform the task and/or the component may perform the task in conjunction with other components. Various logical components and/or features of platform 1202 may be omitted and the techniques described herein adapted accordingly. Similarly, additional logical components/features can be added to embodiments of platform 1202 as applicable.
2. Software
The availability and quality of interoperable, useful software packages is constantly increasing (e.g. as the knowledge and efforts of many software developers are integrated over time into a codebase that counts in the hundreds of millions). The collaborative software development ecosystem is an excellent example of how a solution can be scaled up across many people. “A corollary of the observation that open-source software is now available in greater quantities than it was previously is that the complexity of managing the software has shifted from writing your own code to integrating with other software.
Click here to view the patent on Google Patents.
Leave a Reply