Invented by Blair Livingstone Hotchkies, Bradley Scott Bowman, Paul Christopher Cerda, Min Chong, Anthony T. Chor, Leo Parker Dirac, Kevin Andrew Granade, Udip Pant, Sean Michael Scott, Amazon Technologies Inc
Machine learning is a subset of artificial intelligence that enables computers to learn and make decisions without explicit programming. In the context of content delivery, machine learning algorithms analyze vast amounts of data to understand user preferences, behavior, and patterns. This information is then used to personalize and optimize content delivery, resulting in a more engaging and tailored user experience.
One of the key benefits of machine learning-based content delivery is its ability to improve user engagement. By analyzing user data, machine learning algorithms can predict what type of content a user is most likely to engage with. This enables businesses to deliver personalized content recommendations, increasing the chances of user interaction and conversion.
Furthermore, machine learning algorithms can also optimize content delivery by analyzing factors such as time of day, device type, and location. This allows businesses to deliver content at the most opportune moments, maximizing user engagement and conversion rates.
Another advantage of machine learning-based content delivery is its ability to automate and streamline processes. Traditionally, content delivery required manual analysis and decision-making. However, machine learning algorithms can automate these tasks, saving businesses time and resources. This automation also enables businesses to scale their content delivery efforts, reaching a larger audience without compromising on personalization.
The market for machine learning-based content delivery is expected to grow significantly in the coming years. According to a report by MarketsandMarkets, the global machine learning market is projected to reach $30.6 billion by 2024, with a compound annual growth rate of 44.1%. This growth is fueled by the increasing adoption of machine learning in various industries, including e-commerce, media, and entertainment.
In the e-commerce industry, machine learning-based content delivery is particularly valuable. By analyzing user data, machine learning algorithms can recommend products that are most likely to appeal to individual customers. This not only improves the user experience but also increases conversion rates and customer satisfaction.
In the media and entertainment industry, machine learning-based content delivery is revolutionizing the way content is consumed. Streaming platforms such as Netflix and Spotify use machine learning algorithms to recommend movies, TV shows, and music based on user preferences. This personalized approach has significantly contributed to the success of these platforms.
As the market for machine learning-based content delivery continues to grow, there are several challenges that businesses need to address. One of the main challenges is ensuring data privacy and security. Machine learning algorithms rely on vast amounts of user data, and businesses must take appropriate measures to protect this data from unauthorized access.
Additionally, businesses need to invest in the right infrastructure and talent to effectively implement machine learning-based content delivery. This includes acquiring high-performance computing resources and hiring data scientists and machine learning experts.
In conclusion, the market for machine learning-based content delivery is expanding rapidly, driven by the need for personalized and optimized user experiences. Businesses that leverage machine learning algorithms to deliver content are likely to gain a competitive edge in today’s digital landscape. However, it is crucial for businesses to address challenges such as data privacy and infrastructure to fully capitalize on the potential of machine learning-based content delivery.
The Amazon Technologies Inc invention works as follows
Systems and Methods for Managing Content Delivery Functionalities Based on Machine Learning Models are Provided.” Content requests can be routed according to clusters of previous content requests in order to optimize cache performance. A model is trained using historical data to determine content delivery strategies. The model can also be used to determine configurations above the fold for rendering content responses. Some embodiments allow portions of the model to be executed on client devices.
Background for Machine learning based content delivery
Computing devices and communication networks are able to be used for information exchange. In a common scenario, a computer can request content via the communication network from another device. A user of a personal computer can use a browser software application to request an Internet page from a server via the Internet. In such embodiments the user computing devices can be referred as client computing devices and the server device as a content provider.
As an example, the user of a client computer device can search for or navigate towards a desired item of content. A user can use an application to send requests, search queries, and other interactions to a content provider. It may be an application that is specifically designed to interact with and request content or it may be a browser-based application. One or more embedded resource identifications such as uniform resource locators can be used to identify the requested content. Software on client devices processes embedded resource IDs to generate requests. The resource identifiers often refer to a computing system associated with the content providers, so that the client device will transmit the request for a resource to the computing device referenced by the content provider.
Some content providers try to facilitate the delivery requested content by utilizing a content distribution network (?CDN?) Service provider. A CDN service providers typically maintains several computing devices that are referred to in general as “points of existence”. POPs or “Points of Presence” are computing devices that are maintained by a CDN service provider. In a communication network, content can be maintained by different content providers. Content providers can then instruct or suggest that client computing devices request all or part of the content provided by the CDN service provider. In the example above, the content provider could leverage a CDN provider by modifying or substituting resource identifiers that are associated with embedded resources. The resource identifiers may refer to a computing system associated with the CDN provider, so that the client computing devices would send the request for the requested resource to the computing system of the CDN provider. In many cases, computing devices that are associated with CDN service providers or content providers cache content which is frequently requested. Client computing devices can also cache content from content providers or CDN services. “Serving content requested from caches in different locations reduces the latency associated with delivery of content to varying degrees.
From the viewpoint of a computer user using a client device, the user experience can defined as the performance and latency associated with obtaining content from a network over a communications network. This includes obtaining Web pages or other content from the network, processing and rendering the content on the computing client device, etc. Content providers also tend to be motivated to deliver requested content to clients computing devices, often due to the efficiency or cost of transmission. The user experience can vary depending on how the content is delivered and displayed by client computing devices. This variance can be due to a combination or computing, presentation, networking, and other conditions that are associated with the request and delivery of content. Content providers who are part of a business, such as an electronic commerce site, may also take into account factors like customer retention or business generation when they deliver requested content to the users.
In general, the present disclosure is aimed at managing content requests and deliveries based on machine-learning techniques to serve various or combinations of needs of a provider of content, such as an improvement in user experience, a business development, and/or customer loyalty. Computing devices can model content requests, delivery and rendering processes for a large number users using machine learning techniques. These techniques include supervised, unsupervised and reinforcement learning. These models can represent data patterns and relationships, such as algorithms, functions, systems, etc. Models may accept input data and produce outputs that are correlated to the input. In some cases, the model generates a probability or set of probabilities that an input is a part of a certain group or value. A model can be used, for example, to estimate the likelihood of a certain group of users requesting the content in the future. A model can be used, for example, to predict the performance metrics associated with a strategy that is applied to a request.
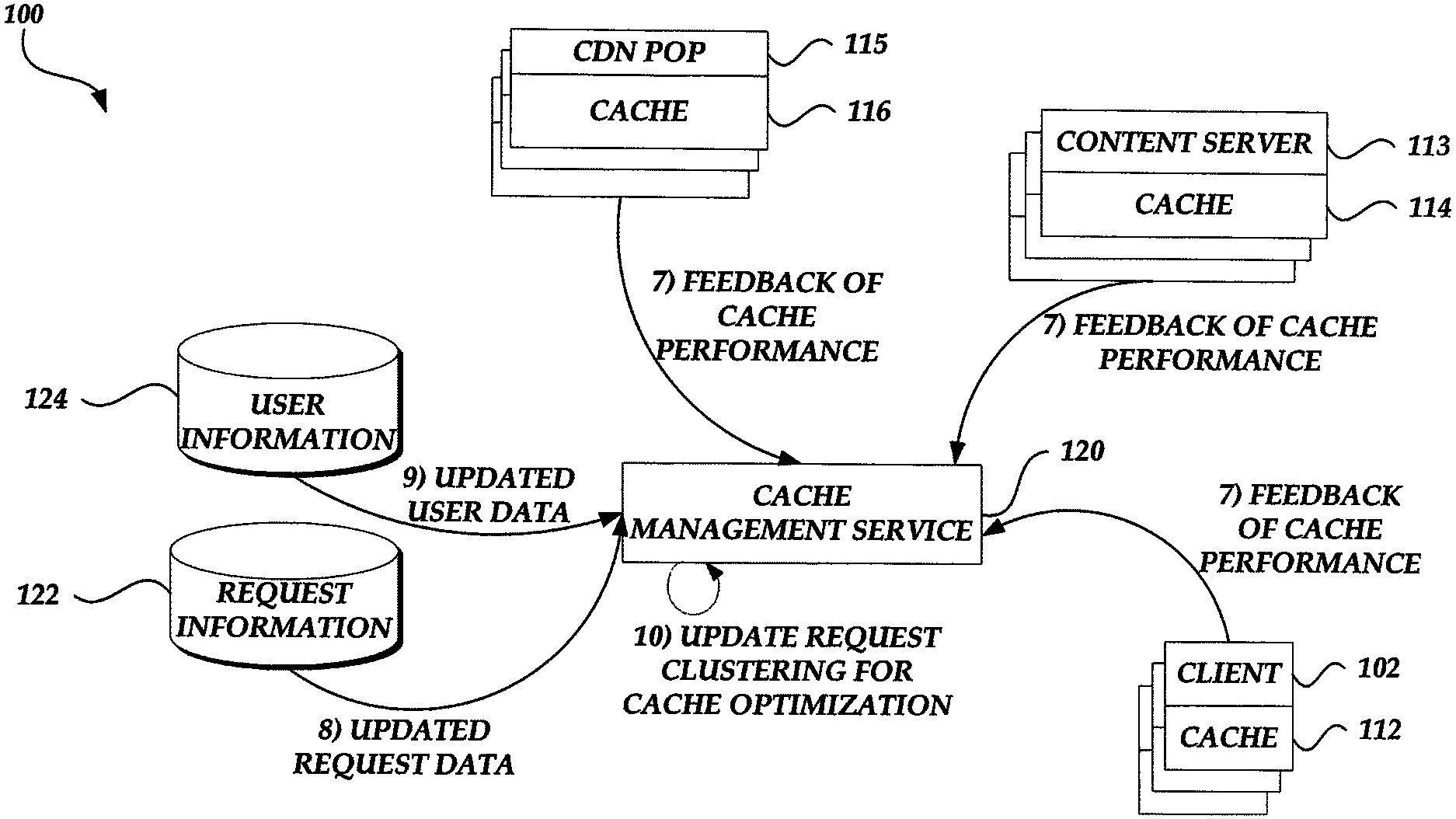
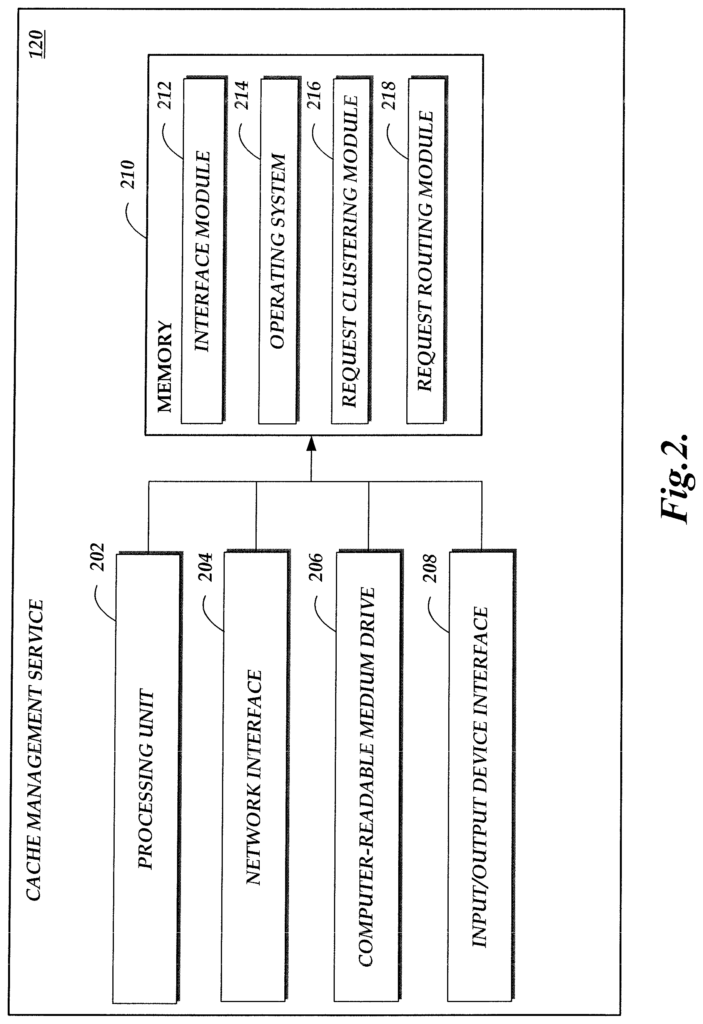
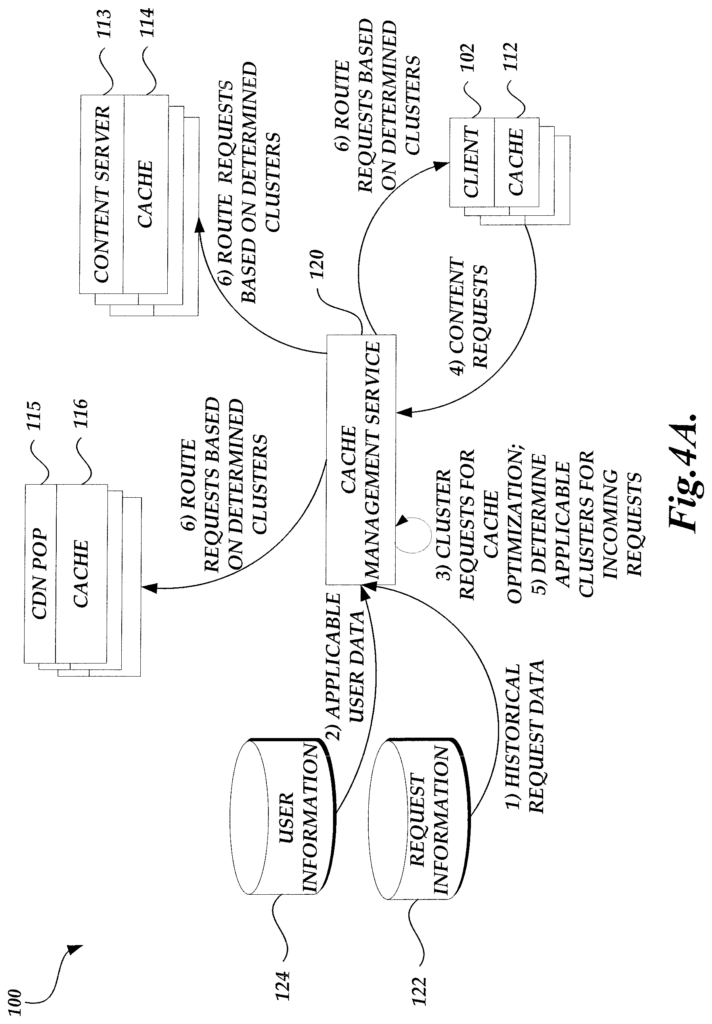
Specifically, certain aspects of the disclosure are described in relation to cache management using request routing and pre-caching content based on machine learning. In one embodiment, the cache management service of a content provider can build a model that routes incoming requests for content to the appropriate content serving computing device (e.g. content servers of the provider, POPs associated with an associated CDN provider, or client computing systems associated with users), which are most likely to cache the requested content. The model can be constructed based on the unsupervised clustering past requests. The cache management service, for example, may analyze the content requests that the content provider has received over a certain period of time. It will then cluster these past requests using a criterion assessing their similarity. The criteria may be a formula that defines a distance between multiple requests. The formula may determine that requests submitted by devices in a particular geographic area during a limited time period on weekends for the same resource have a close distance between them.
Once clusters of previous content requests have been determined, the cache-management service can associate each cluster to a subset of computing devices that are best positioned to cache relevant content in anticipation of future requests for similar content. The cache management service can also instruct the subsets of content-serving devices to precache some of the content requested by the clusters of requests, in anticipation of future requests that are similar. The cache management service can now start routing content requests after establishing the association between clusters, content serving devices and computing devices. The cache management service, as an example, receives a content request from a user and determines the cluster that corresponds with the request. This is done, for instance, by using the same criteria for assessing the commonalities between requests. The cache management service routes the incoming requests to the subset computing devices associated with the determined group, such as by using DNS resolution, URL modifications or other routing techniques that are known in the industry.
The content serving devices and client computing devices can collect cache performance metrics, such as cache hit or missed rate, routing costs, user perceived latencies, combinations of these, etc. The cache management service can use the information about newly received and routed request as well as collected performance information in order to optimize and update the model. The cache management service, for example, may re-generate clusters using newly received requests following the previous round. The cache management service can modify the clustering criteria, for example by changing the weights of parameters in the formula used to determine distance between requests. Modifications may, for example, be made to reduce the likelihood that clusters will form that had poor cache or content delivery performances in the previous round and increase the likelihood that clusters with strong performance may be generated. Updates to the model can occur periodically or in response to conditions such as when performance metrics fall below a threshold.
Other aspects will be discussed with regards to content management using machine learning-based content strategy determination. In one embodiment, the content delivery service of a content provider can build a model that determines appropriate content delivery strategies to respond to incoming requests. The content delivery service may or not use the caching service to route requests. The model could be a supervised-learning model (e.g. a decision tree, or an artificial neural network), trained using historical data relating to the processing and delivery of content requests. The content delivery service, for example, may derive various attributes (e.g. requested resources, timing, network conditions, computing capabilities of the request submitting device etc.). Each content request that the content provider receives over a certain period of time. In some cases, user attributes are applicable (e.g. demographics, purchases, Web browsing history, search term histories and session tracking histories; ownership or rental lists; preferences, settings etc.). The content requests submitted by users can be associated with the user attributes. Content delivery management services can also determine various components of content delivery strategies (e.g. inclusion or exclusion certain features from responses, lazy loading or prefetching resources, inlining or external calls for resources, data formats of low or high quality, dependency graphs associated with responses and above-the fold configurations, routing requests, etc.). Data related to the responses to each content request can be derived. The content delivery service, on the other hand can collect or derive performance metrics for content delivery (e.g. perceived latency rate, error rate, caching efficiency, etc.). According to each request. In some cases the metrics for content delivery may include user-specific values, such as an evaluation of the likelihood that a particular user will make a specific purchase (including timing, amount, frequency etc.). After receiving a response, the user can then evaluate whether or not they are likely to make a related purchase (including its timing, type, amount and frequency). “All of the data regarding content requests in the past, the content delivery strategy, and the corresponding performance can all be used to train the model.
The model can generate performance predictions by combining a candidate content strategy with the attributes of an incoming request for content. The content delivery service can apply the model in conjunction with several candidate strategies to an incoming content request and then select the strategy that best predicts performance. The set of candidate strategies for content delivery may include different components of the strategy that are highly correlated with the content requests from the training data. The content delivery service then executes that strategy. For example, it may identify a pregenerated response to the requested content, generate dynamic HTML documents, cause content serving devices cache certain network resources in advance, route the request to the corresponding content server or combinations thereof.
The content delivery management service can transmit a reply to the client computing device in accordance with a content delivery strategy. The response (such as an HTML file) may contain information that directs the client computing device perform additional steps in accordance to the content delivery strategy. For example, the client computing devices can request embedded resources from CDN providers in accordance with an associated order or prioritization, pre-fetching content in anticipation for future requests, etc.
Still other aspects of the disclosure are described in relation to the implementation on computing devices of a part of the model used for determining the content delivery strategy. In one embodiment, the global model used by the content management service can be divided into separate portions. Some of the separable parts may be executed by individual client computing devices that make content requests. Some upper levels of a tree decision or a portion of the input layer of an artificial neuron network, for example, may be separable since input data to these portions is accessible to individual client computing devices. Client computing devices can then apply the separable portion of a model to newly generated content requests by using a script or separate application running within a content-requesting application. The output from the locally implemented model parts can be included in the content requests sent by client computing devices to content providers and fed into a global model when appropriate (e.g. as input to a lower-level decision tree or intermediate layer of neural networks).
Further the content delivery service can dynamically decide which part of the model is to be implemented on the client computer device. At the start of a browsing session, for example, a simple and generic part can be given to the client device. The content delivery service may be able, as it processes more requests for content from the client device during the browsing session, to determine its computing capabilities or data accessibility. The content delivery service can then provide the client computer with a more complex or specific part of the model.
In some cases, separable parts of the global model may be trained on each client computing device. On client computing devices, for example, a sub-decision tree or a part of the artificial neural network can be updated or trained based on local data to predict user behavior, such as content users are likely to request in a near future. The model can then be used by the client devices to apply directly to newly generated content requests. The model can also be updated by a content delivery service when the global model changes.
Yet other aspects of disclosure will be discussed with regards to the facilitation of rendering responses to content requests using machine learning based on above the fold (ATF?) determination. ATF is a portion or rendered content (such as a Web page, Web application or other rendered content) that can be initially viewed or perceived by a user on a client computing devices without scrolling. In one embodiment, a content delivery service may create a model for determining appropriate ATF configurations to render responses to content requests. The model used to determine ATFs may be the model described above. One of the outputs from the same model could be an indication of ATF configuration. The ATF determination model could also be a standalone model of machine learning.
Similarly, the ATF model can be a model that is trained using historical data relating to content requests, responses, and users. The model may benefit from data on user interactions (e.g. scrolling, dwelling or clicking actions, browsing, searching, purchasing, product reviews, user preferences or settings, and user location) as well as client computing device information (e.g. screen size, resolution, browser window, browser version or device orientation). The data could reveal, for example, that a certain group of users scrolls down directly from the ATF portion in a particular type of content they requested. This could be interpreted as an indication that ATF’s current configuration of the content type is inappropriate for this group. The model can learn from the consistent scrolling (e.g. by the same number of pixels) that the ATF is to display a lower portion of content (or an element or resource therein). The content delivery service can assign priorities to the retrieval and display of resources embedded within a response based on the ATF configuration. This allows the ATF to present the most relevant content first.
After the model is trained to determine ATF, it can take inputs such as attributes of an incoming content request and a possible candidate content delivery strategy, and produce one or more indications about ATF configurations to render the response. The indication could be a prediction that a certain portion or feature of the content response is what the user will view or interact. The content delivery service may select an ATF (e.g. based on confidence level, predicted content delivery performance, etc.). It may then apply the ATF in response to a content request (e.g. by changing the order of embedded resources calls, incorporating script code, and so forth). The model used to determine ATF can also be optimized and updated based on feedback collected from client computing devices, and other relevant sources.
Although the disclosure is described in terms of illustrative embodiments and examples, those skilled in the art can appreciate that these embodiments and examples are not intended to be restrictive. The term “content provider” is one example. The term’service provider’ is not meant to limit the scope of any service provider. One skilled in the relevant arts will understand that a content supplier does not need to provide all or any of the additional functionality or services that may be associated, for example, with a content provider associated with an electronic-commerce website.
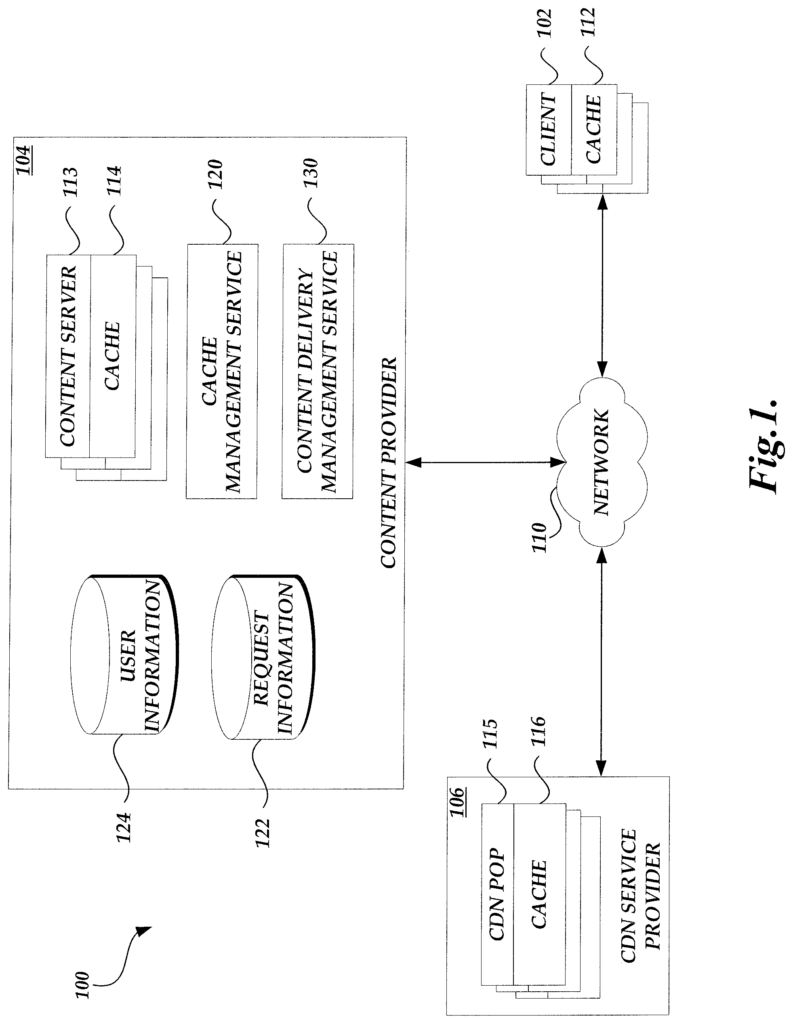
FIG. The block diagram in Figure 1 illustrates a content delivery system 100, which includes a number client computing devices (clients?) A content provider 104, including a caching management service 120, a delivery management service 130 and a CDN provider 106, are shown in a block diagram. In one illustrative embodiment the clients 102 may correspond to various computing devices such as personal computers, laptops, handheld devices, terminal devices, wireless devices, electronic devices and appliances (such as televisions and other appliances), etc. Optionally, the client 102 includes a resource cache component 112. This component stores resources provided by content providers or CDN services. In one illustrative example, the client computing device 102 includes necessary hardware and/or software components to establish communications with other components in the content delivery environment (100) over a network 110, as well as to request, receive and render content. The client computing devices may, for example, be equipped with network equipment and browser applications that facilitate communication via the Network 110. The network 110 could be a public network of linked networks that is operated by different parties. For example, the Internet. In some embodiments, network 110 can include a personal area network (PAN), LAN, WAN, cable network, satellite network, etc. ), LAN, WAN, cable network, satellite network, etc. “Or some combination of them, all with access to or from the Internet.
The content delivery system 100 can include a CDN service provider (106), a content provider (104), and one or more clients (102). This is all done via the communication network. In the example, one or more client 102 can be associated with content provider 104. “For example, the user may have a content provider account, or the client may be configured to share information with certain components within the content provider.
![]()
The content provider 104 shown in FIG. The content provider 104 illustrated in FIG. 1 is a logical association between one or more computing device(s) associated with it for hosting content, and for servicing requests for hosted content via the network 110. The content provider 104 may include one or multiple content servers 113, each of which corresponds to one or several server computing devices, for receiving and processing content requests (such as network resources or content pages) from clients 102, cache management service 120 or content delivery service 130 or other devices or services providers. Optionally, the content server 113 may include a resource cache component (e.g. a number cache server computing devices), which can be used to store resources and send them out to clients 102, without having to generate the content or retrieve it from another source such as a database. Content servers 113 can include software or hardware components to facilitate communication, including but not limited to load-balancing and load-sharing software/hardware components.
Click here to view the patent on Google Patents.
Leave a Reply