Invented by Deepak Kumar Poddar, Mihir Mody, Veeramanikandan Raju, Jason A. T. Jones, Texas Instruments Inc
However, as machine learning models become more sophisticated and powerful, the risk of unauthorized use, theft, or tampering with these models also increases. This is where watermarked weights come into play. Watermarked weights are a technique used to embed a unique identifier or signature within the weights of a machine learning model. This watermark acts as a digital fingerprint, allowing the model’s owner to identify and track any unauthorized use or modifications.
The market for machine learning models with watermarked weights is driven by several factors. Firstly, there is a growing concern among organizations about the security and protection of their machine learning models. With the increasing reliance on these models for critical decision-making processes, organizations cannot afford to have their models compromised or used without their consent.
Secondly, the market is driven by the need for accountability and transparency in the machine learning industry. Watermarked weights provide a way for organizations to prove ownership and demonstrate the integrity of their models. This is particularly important in industries such as finance, healthcare, and defense, where the consequences of using compromised or tampered models can be severe.
Furthermore, the market for machine learning models with watermarked weights is also fueled by regulatory requirements. As governments and regulatory bodies become more aware of the potential risks associated with machine learning models, they are imposing stricter regulations on their use and deployment. Watermarked weights can help organizations comply with these regulations by providing a means to track and verify the usage of their models.
In terms of market dynamics, there are several players involved in the market for machine learning models with watermarked weights. Companies specializing in machine learning model development and training are incorporating watermarking techniques into their offerings to provide enhanced security and protection to their clients. Additionally, there are specialized software tools and platforms available that allow organizations to watermark their existing models or train new models with watermarked weights.
The market for machine learning models with watermarked weights is expected to witness significant growth in the coming years. As the value and importance of machine learning models continue to rise, organizations will increasingly prioritize the security and protection of their models. Watermarked weights offer a practical and effective solution to address these concerns, making them an essential component of the machine learning ecosystem.
In conclusion, the market for machine learning models with watermarked weights is experiencing rapid growth due to the increasing need for security, accountability, and compliance in the machine learning industry. Watermarked weights provide a way for organizations to protect their intellectual property, track unauthorized use, and ensure the integrity of their models. As the demand for machine learning models continues to rise, the market for watermarked weights is expected to expand further, offering new opportunities for companies specializing in this field.
![]()
The Texas Instruments Inc invention works as follows
In some cases, a storage unit stores a machine-learning model. The machine-learning model consists of a plurality layers with multiple weights. The system includes a processing module coupled to the storage, which is able to group weights within each layer into multiple partitions. It can also determine the number of least significant bit to be used to watermark each partition. The system includes an output device that provides the scrambled and watermarked weights to another device.
![]()
Background for Machine Learning Model with Watermarked Weights
Machine learning is an artificial intelligence application that allows systems to learn from their experiences and improve without having been explicitly programmed. Machine learning systems are probabilistic, as opposed to traditional von Neumann computer systems which are deterministic.
In one example, a storage unit stores a machine-learning model. The machine-learning model comprises multiple layers. The system includes a processing module coupled to the storage, which is able to group weights within each layer into multiple partitions. It can also determine the number of least significant bit to be used to watermark each partition. The system includes an output device that provides the scrambled and watermarked weights to another device.
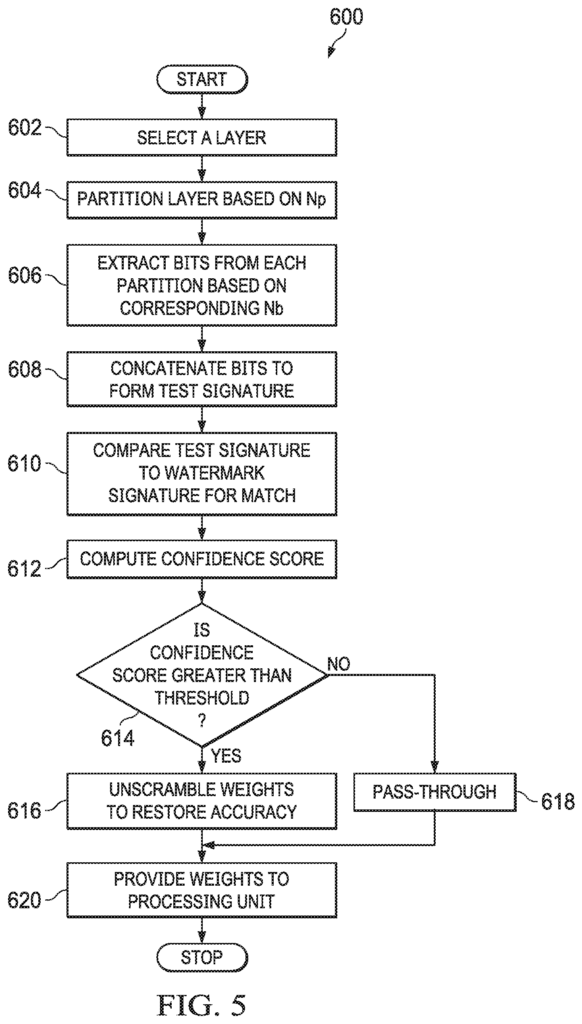
In a second example, the system comprises a storage that can store watermarked weights and scrambled ones of a machine-learning model. The watermarked weights and scrambled ones are arranged in layers. The system includes a processor that is coupled to the storage, and which can be used to retrieve the watermarked weights. It also has a processor that can obtain for each layer a number partitions as well as a number least significant bits for watermarking. Finally, it can obtain a test signature from the watermarked weights using the number partitions. The processor can also receive a test signature, compare it to the watermark signature; compute a score of confidence based on this comparison; compare that score to a threshold to determine if the test and watermark are a match; and then use the unscrambled and watermarked weights.
In a third example, the method involves providing a machine-learning model that consists of a plurality layers. Each of these layers contains weights which are watermarked and scrambled. The method further includes selecting one layer from the plurality. The method also includes grouping weights within each of the layers according to a number partitions, forming a plurality partitions. The method further includes obtaining the watermark bits for each of the plurality partitions using a number of bits that are used to watermark. Concatenating these watermark bits into a test signature is the next step in the method. The method also includes obtaining a signature of the watermark. The next step in the method is to compare the test signature with the watermark signature. On the basis of this comparison, the method computes a confidence level. The method also includes comparing a confidence score to a threshold. In addition, the method includes removing the weights when the confidence score exceeds the threshold. When the confidence score falls below the threshold, the method includes refraining to unscramble the weights. The weights are also provided to another device that is configured to make predictions based on the machine-learning model and the weights.
Deep learning has made improvements in many areas. For example, it is now more effective at speech recognition, pattern recognition and image processing. Deep learning architectures are feed-forward neural networks, recurrent neural networks, convolution neural network (CNN), and long/short term memory cells. Deep learning is a process of?training’. A machine is taught to perform tasks by a large amount of data. CNN-based machine-learning, for example, is a type of deep, forward-feeding artificial neural networks that are inspired by mammalian vision systems and used to recognize patterns, detect objects, and process images.
The development of a machine-learning model involves two phases. First, there is a training phase and then a testing phase. In the training phase, a machine learning model’s weights are determined. Weights are difficult to determine and can be expensive. Weights are expensive because they can be difficult to determine during training. Weights can be stolen and should not be altered or used without authorization.
Accordingly described herein are several examples of systems or methods for protecting machine-learning weights against theft or unauthorized modification. Some examples involve the modification of machine learning weights to prevent theft or alteration. The disclosed techniques include scrambling weight bits in order to render them useless until the watermarks embedded within the weights can be unlocked using a key. At that point, the weight bits can be unscrambled for use in machine learning.
As mentioned above, these techniques include phases of training and testing. Imagine a group of weights which are to be protected. During the learning phase, subsets from these weights will be scrambled in order to reduce the accuracy of the machine-learning model. A watermark, which is a sequence or grouping of bits, is also inserted at specific locations within the weights set. This watermark is a “lock”. The set of weights are protected against unauthorized use in this watermarked, scrambled form. During testing, an individual user or computer might want to use the scrambled, watermarked set of weights within a machine-learning system. This system will need to have access to the watermark signature which is used to unlock the watermark on the weights. The watermark signature, or the key to unlock the weights set, is used as a way to verify the user accessing the weights. If the watermark matches the signature, then the weight bits can be unscrambled and used by an authorized user. The following examples will be described with special reference to the illustrations. “The description below is meant to apply to CNN Weights, but all machine learning weighting systems can be considered.
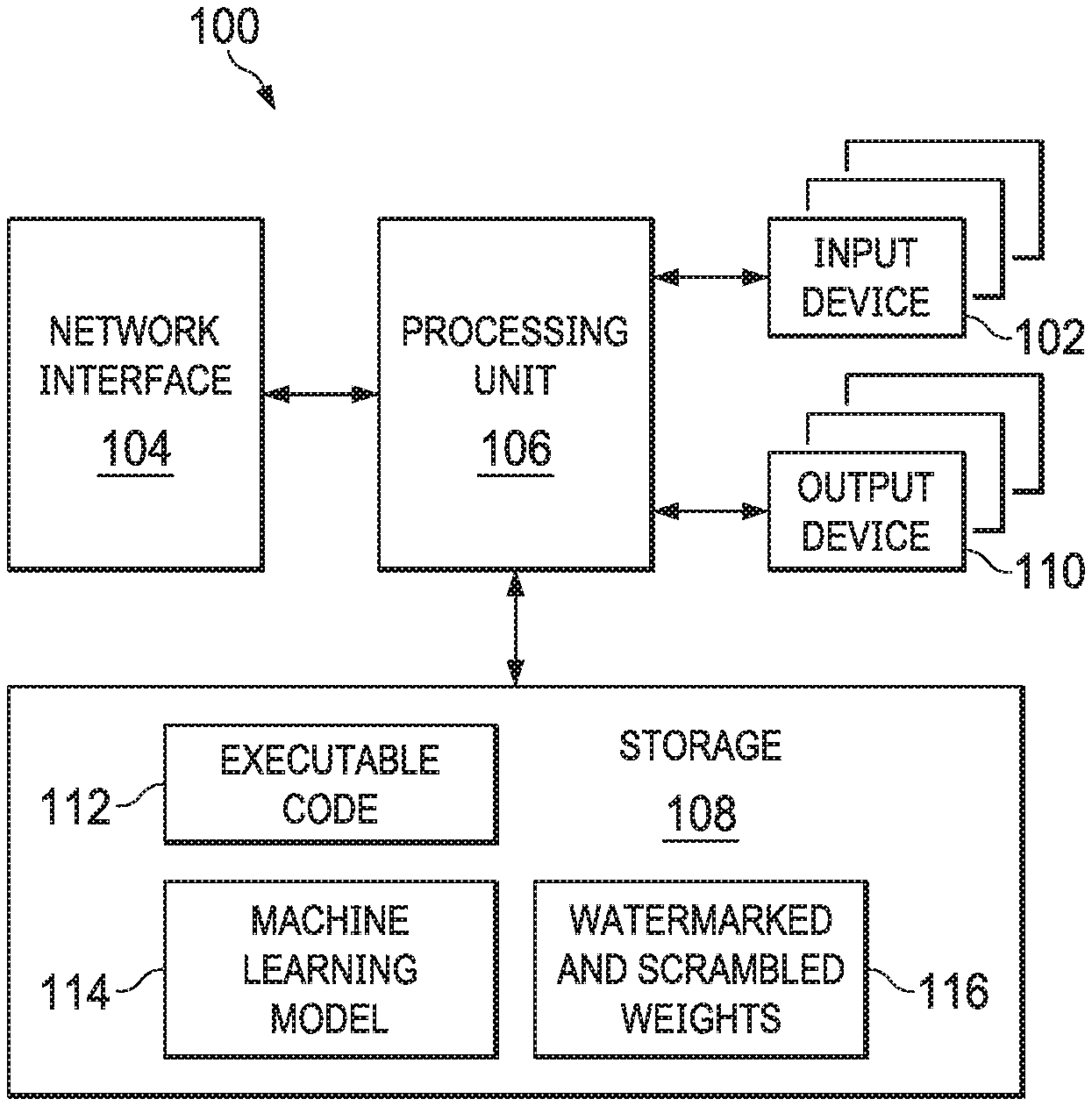
FIG. The block diagram 1 shows an example of a system 100. The system 100 can be a machine-learning system. The system 100 may include, for example, one or multiple input devices 102, such as keyboards, mics, and touchscreens; a network interface (e.g. a transceiver or network card) to communicate with an Internet or local area network; a processor 106; a storage 108, such as random access memory (RAM); and one or several output devices 110, including displays and audio speakers; executable code 112 which, when executed, causes the processor 106 to perform one or more of the actions The FIG. may include other hardware components or software/firmware. 1. The system 100 can carry out the above-mentioned phases of training and testing. Now, the method by which the system 100 performs its training phase will be described in relation to the FIGS. The system 100’s training phase is described in detail with reference to FIGS. “Figures 1 and 5.
FIG. The diagram in Figure 2 illustrates a watermarking technique that can be used to scramble and watermark data. This technique is carried out by the system 100 and, in particular, the processing unit 106, upon execution of executable code 112. Referring to FIGS. In FIGS. In some cases, the weights 202 that are unmarked and unscrambled can be stored separately from the model 114. For example, they could be in storage 108, or another storage, not shown in the illustrations.
After obtaining the weights that are not marked and unscrambled, the processing unit analyzes them, as shown by the numeral 204 on FIG. 2. The processing unit 106 analyses the unmarked weights and unscrambled bits 202 in order to determine which weight bits are best suited for watermarking. That is, which weight bits would not have any impact on accuracy when the weights could be used or which weight bits would have a significant impact if they were watermarked. FIG. This process is described in Figure 3. It describes the identification of the weight bits that are most suitable for watermarking.
Machine-learning models are organized in multiple layers. Each layer includes a plurality weights. The weights for each layer are also grouped together into partitions. For example, a machine learning model illustrative may have ten layers with two partitions in each layer, each partition containing multiple weights. Each weight, for instance, includes eight bits. The bits are arranged in order of importance within each partition. In a weight of eight bits, the bit 7 is the least significant, while the bit 0 is the most significant.
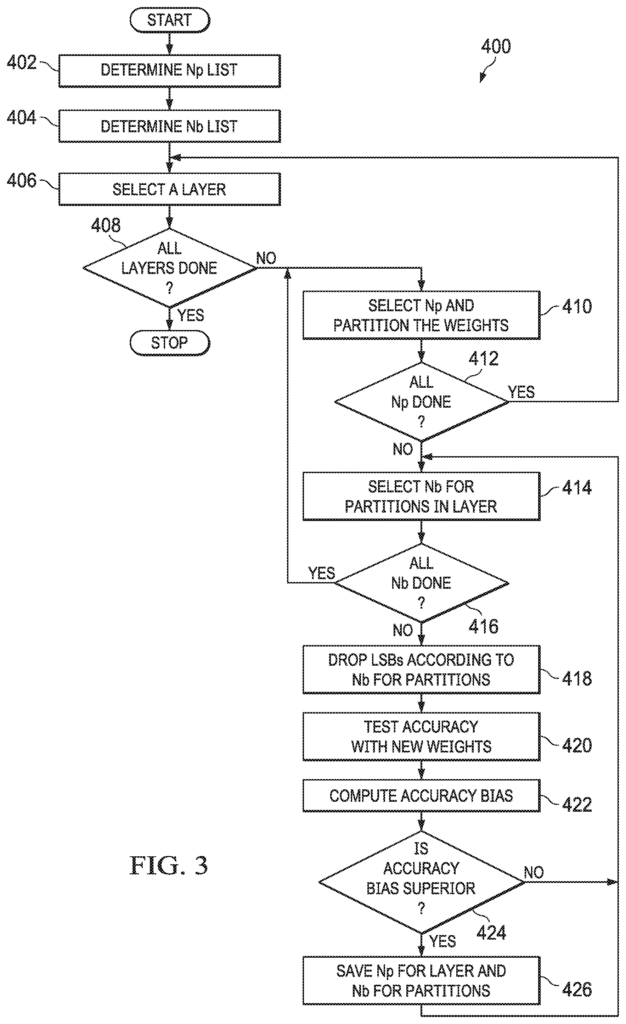
FIG. The flow diagram 3 shows a method for identifying weight bits within a machine-learning model that are best suited for watermarking. This is done by using various examples. The method 400 identifies an overall scheme of watermarking for weights within a machine-learning model. In some cases, the method 400 is performed by the processing unit 106. The step 402 determines how many partitions are needed in each layer for the best watermarking scheme. For example, it is possible that only having two partitions per layer of weights produces a more efficient watermarking scheme, or vice versa. Step 402 involves determining a number list, each of which specifies the number of weight partitions that can be used in each layer. As an example, step 402 could produce the list [1,2,4,8], which means that the effectiveness for watermarking schemes should be determined based on weights that only have one partition per layer. The number of partitions that are used to group the weights of a layer in this description is called?Np.? For the purposes of this document, we will assume that an Np of [1, 2, 4] is used, but any Np can be used.
Step 404 is in some ways similar to step 402. Step 404 is a method for determining the number of bits to use in a partition’s weights. In step 404, the number of watermarking bit per partition can have a different effect on watermarking. This is similar to step 402. For example, using one bit for each weight in a partition to watermark may be less efficient than using two bits. In step 404, processing unit 106 creates a list with numbers that indicate how many bits should be used for watermarking. As an example, a list like [1, 2] may be used. Watermarking should only be done with one bit for each weight of a partition. Two bits per weight should be used to watermark a partition. The number of bits per partition used for watermarking is called?Nb?. For the purposes of this document, an Nb-list of [1,2] will be assumed.
Step 406 starts the analysis of weights to be used for watermarking. Step 406 involves selecting one layer out of the many layers that are to be protected. This step shows that the steps 408 to 426 are carried out separately for each layer. If not all layers were selected at step 406 (step 408), the method 400 consists of selecting a value for Np from a list created in step 402 (step 410) and dividing the weights according to that value. If there are 10 layers, for example, the first one will be chosen in step 406 from the list of Np [1, 2, 4], and the first Np, that is 1, will be selected at step 410. A Np of 1, for example, means that there should only be one partition in the first layer. The weights from the first layer will therefore be grouped together into a single partition. If an Np of two was selected, then the weights for the first layer in step 406 will be divided into two partitions. This description is based on the assumption that Np 8 has been selected.
The method 400 selects an Nb value that will be tested on one or more partitions within the selected layer. (Step 414). If not all Nbs from the list created at step 404 are exhausted (step 416), the method 400 drops the least significant bits (LSBs), based on the value of Nb selected across all partitions of the selected layer. Dropping is what we mean by ‘dropping’. By?dropping,’ Null watermark bit is a set (e.g. 0, 0), which are used to produce an “apples-to apples” comparison in each iteration. Comparison of the effectiveness between different watermarking schemes. “New weights are created by dropping the LSBs and inserting null bits of watermark in the weights.
In step 420 the accuracy of new weights is calculated using the machine-learning model by using conventional techniques. In step 422, it is determined the accuracy bias that was caused by dropping the LSBs in step 418. The accuracy bias can be determined in some cases as follows:
Accuracy\n?\n?\nbias\n=\nTest\n?\n?\naccuracy\n-\nReal_total\n?\n_bits\n*\n(\n0.03\nTotal_bits\n)\n\nwhere Test accuracy is the accuracy computed using the new weights (step 420); Real_total_bits is the total number of weight bits in the layer in question excluding the bits reserved for Nb for each partition in the layer; and Total_bits is the total number of weight bits in the layer in question including the bits reserved for Nb for each of partition in the layer.
The method 400 analyzes iteratively the accuracy bias calculated from each combination of NP and NB in the lists created in Steps 402 and 404 in order to determine which combination Np and NB produces the best accuracy for the layer chosen in Step 406. The processing unit 106 performs iteratively the steps 410-424 and, in some instances, 426 for each combination Np and Nb of the layer selected in Step 406. The processing unit 106 keeps a running record of the combination Np and Nb which produces the best accuracy bias in step 422. (Steps 424 and 426). The combination of the Np with the Nb that produces the best accuracy bias value is stored in the running records. If the combination of the Np with the Nb produced a higher accuracy bias than the combination stored in the record, the combination of the Np with the Nb will overwrite the combination currently stored. After all combinations of Np with Nb for a layer have been tested, the combination Np + Nb stored in the current running record is the combination which produces the highest accuracy bias value. This process is repeated for all remaining layers (steps 406 and 408). The method 400 produces a combination of Np, Nb and each layer of the machine learning model. This combination can be stored as metadata for each layer in the machine learning model.
The method 400 is shown in FIG. The method 400 as shown in FIG. 3 involves evaluating all Np and Nb combination for each partition at the same time, e.g. parallel. The result is a single Nb value that applies to each partition in the layer. In some cases, Np and/or Nb combinations may be evaluated serially for each partition, that is, one by one. In these examples, Np values are selected for a layer from the list created in step 402, Nb values for each Np value are selected from step 404 and an accuracy bias for each Nb value is calculated for each partition. This allows the best combination of Np with Nb to produce the best accuracy bias for each layer’s partition, instead of determining the value for all layers at once. It may be possible to have different values for Nb in each partition of a layer or, alternatively, the same value for each layer. This variation of method 400 results in a combination of Np, Nb and each partition of each layer of the machine-learning model. This combination can be stored as metadata for each layer in the machine learning model.
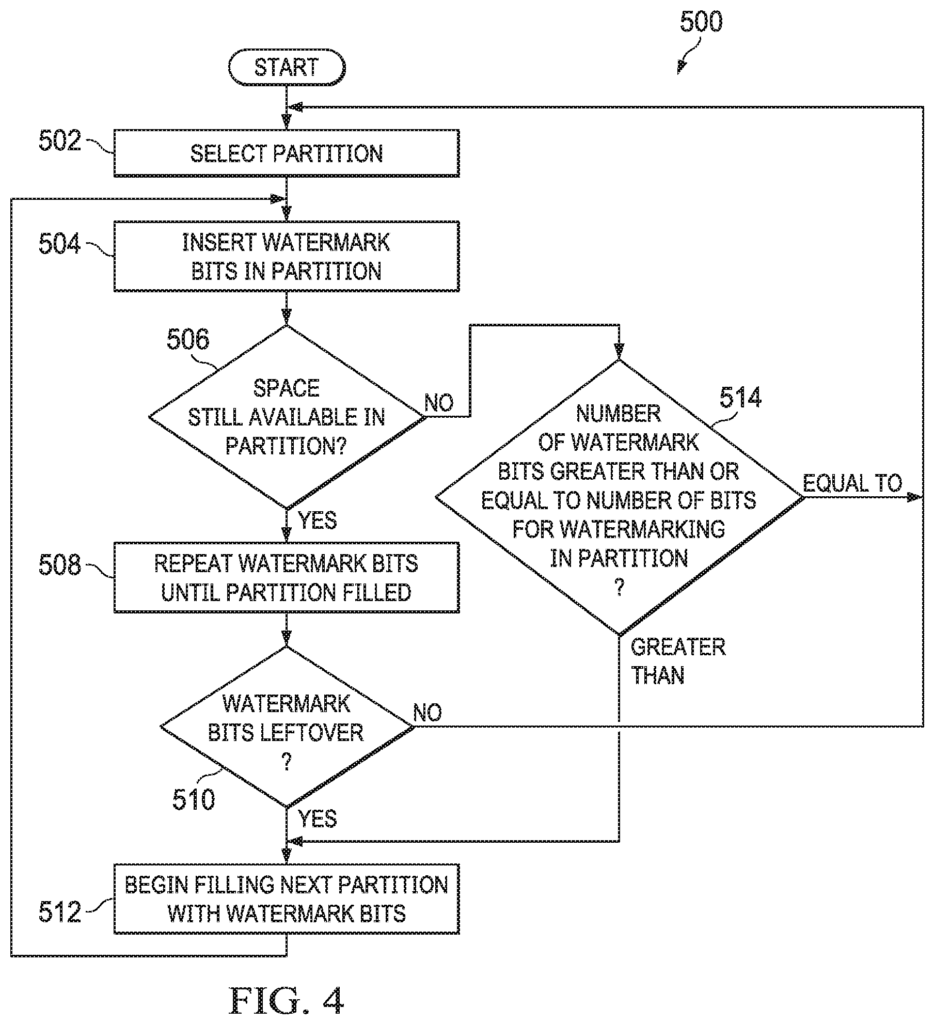
Referring back to FIG. After the analysis 204 has been completed, the watermark 206 will be inserted in the weight bits as shown by the numeral 208. Watermarks, which are a confidential series of bits, can be generated by anyone. For example, the designer or user of system 100. In some cases, the number is equal or less than the total number bits for watermarking determined by the method 400. FIG. “FIG.
Click here to view the patent on Google Patents.
Leave a Reply