Invented by Gideon W. Glass, Tintri by DDN Inc
One of the key drivers behind the market growth is the increasing demand for data protection and disaster recovery solutions. Organizations are becoming more aware of the potential risks associated with data loss and downtime, and they are actively seeking ways to mitigate these risks. Optimized remote cloning offers a reliable and efficient solution by ensuring that critical data is replicated in real-time or near real-time to a remote location. This enables businesses to quickly recover from any data loss event and minimize downtime, thus ensuring business continuity.
Another factor contributing to the market growth is the rise of cloud computing and the need for seamless data migration between on-premises and cloud environments. As more businesses adopt cloud-based solutions, they require efficient methods to transfer their data to the cloud and keep it synchronized with their on-premises systems. Optimized remote cloning provides a secure and efficient way to replicate data between these environments, ensuring that businesses can seamlessly transition to the cloud without any disruption to their operations.
Furthermore, the increasing complexity of IT infrastructures and the need for efficient data management have also fueled the demand for optimized remote cloning. As organizations accumulate vast amounts of data, they face challenges in managing and protecting this data effectively. Optimized remote cloning solutions offer advanced features such as deduplication, compression, and encryption, which help optimize bandwidth utilization, reduce storage costs, and enhance data security. These features make remote cloning an attractive option for businesses looking to streamline their data management processes and improve overall operational efficiency.
In terms of market players, several technology vendors offer optimized remote cloning solutions, each with its unique set of features and capabilities. These vendors compete in terms of performance, scalability, ease of use, and cost-effectiveness. Some of the key players in the market include Dell EMC, IBM, NetApp, Hewlett Packard Enterprise, and Cisco Systems. These companies invest heavily in research and development to enhance their remote cloning offerings and stay ahead of the competition.
Looking ahead, the market for optimized remote cloning is expected to continue its growth trajectory. The increasing reliance on data and the need for efficient data replication and protection will drive the demand for remote cloning solutions. Additionally, the growing adoption of cloud computing and the need for seamless data migration will further fuel the market growth. As technology continues to evolve, we can expect to see more advanced features and capabilities in remote cloning solutions, making them even more valuable for businesses of all sizes.
![]()
The Tintri by DDN Inc invention works as follows
The disclosure relates to “optimized remote cloning”, which includes: receiving data from an external storage system that is associated with the ongoing replication of a snapshot. And, prior to completing the replication of the snap shot, generating metadata for a clone. At least a portion the data of the image received by the destination storage can be accessed using the clone, while the replication of the picture is still in progress.
Background for Optimized Remote Cloning
When moving data from one system to another, it is common for the data to be copied in full at the destination system before clients can access the data. Also, the data is typically sent in relatively static order from the source system to the target system.
The invention may be implemented in many ways. It can be used as an apparatus, a process, a system, a composition, a product of computer programming, and/or a CPU, such as one that executes instructions stored on or provided by a memory connected to the processor. These implementations and any other form of the invention can be called techniques in this specification. The invention allows for the possibility of altering the order of steps in disclosed processes. A component, such as a processor and a memory, described as being capable of performing a task can be implemented either as a general component that is temporarily set up to perform the task at a particular time or as a specific component that was manufactured to do the task. The term “processor” is used herein. The term “processor” refers to any one or more devices, circuits and/or processing cores that are designed to process data such as computer program instruction.
Below is a detailed description of some embodiments of the invention, along with accompanying figures that illustrate its principles. Although the invention is described with these embodiments in mind, it is not limited to them. The claims limit the scope of the invention, and the invention includes many alternatives, modifications, and equivalents. The following description provides a detailed understanding of the invention. These details are given for example purposes only. The invention can be used according to the claims without any or all of these details. To be clear, the technical material related to the invention that is well-known has not been described in detail. This is done in order not to obscure the invention.
Herein is described the replication of snapshot data. The replication of snapshot data from a storage system source to a storage system destination is started. A snapshot can be a copy made at a specific point in time of a collection of data. The set of data can be, for example, associated with a Virtual Machine (VM) or a component thereof (e.g. a virtual disk or a file). During the replication of the snapshot, data related to the snapshot are transferred from the storage systems at the source to those at the destination. A set of metadata is generated by the destination system prior to the complete transfer of the snapshot. The clone, as will be explained in more detail below allows at least a part of the data from the snapshot that has been replicated at the destination system to be accessed while the replication is still taking place. A first request is also received by the destination system prior to the complete transfer of the snapshot data from the source system to the destination system. The destination storage device determines that the data value for the first request from the source system has not been received by the destination system. A second request is sent to source storage in response to the determination at the destination system that the data associated with the request has not been received from the source system. This request prioritizes the transfer of data to the destination system. “As such, embodiments described herein for replicating snapshot data allow access to snapshot data received at the destination system before the complete replicating of the entire snapshot is completed from the source system to the target storage system.
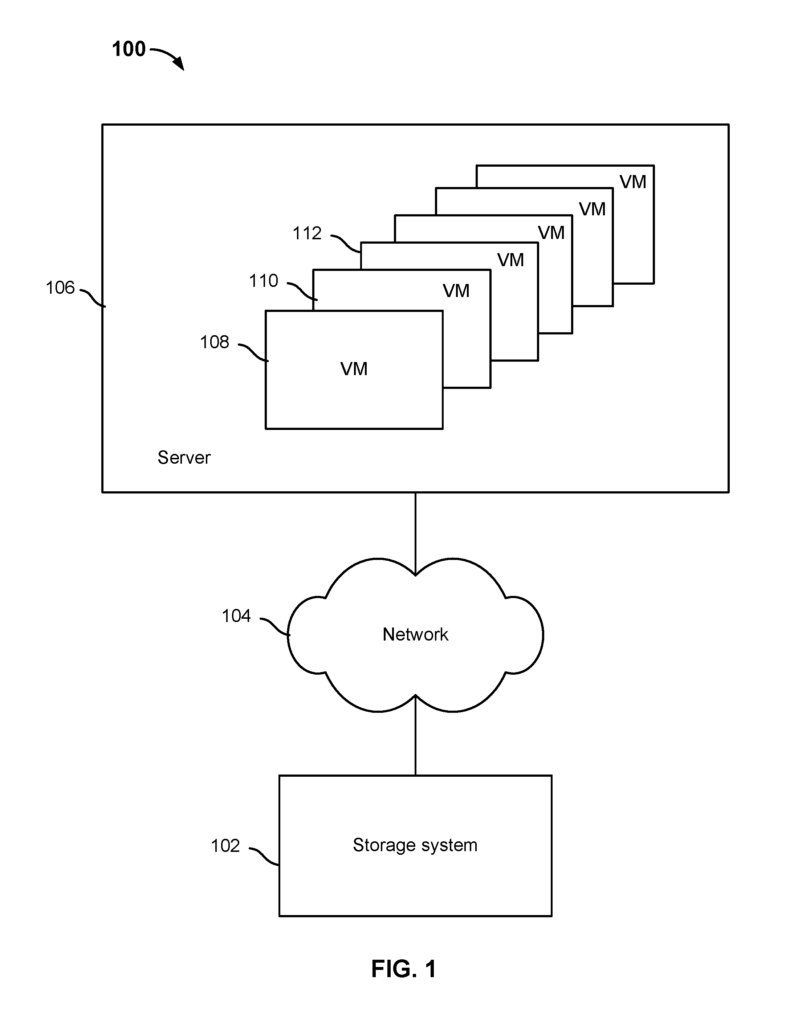
FIG. FIG. 1 shows an embodiment of a system for storing virtual machines using virtual machine abstractions, according to some embodiments. In the example, system 100 comprises server 106 and network 104. Storage system 102 is also included. In some embodiments, the network 104 may include high-speed data networks or telecommunications systems. In certain embodiments, network 104 is used to communicate between storage system 102 and server 106. In some embodiments the file system used for the storage and management of VMs based on virtual machine abstractions does include network 104. Storage system 102, however, is a part of server 106. In some embodiments the server 106 can communicate with other storage systems than storage system 102.
In various embodiments, server 106 runs several VMs. In the example, VMs 108 and 110 (and other VMs), are running on server 106. A VM is a virtual machine (VM) that emulates a physical computer and executes the same programs as a real machine. A physical machine, such as a computer, can be configured to run multiple VMs. Each VM can run a different OS. As a result, multiple operating systems can run simultaneously and share resources on the same physical device. In some embodiments, a VM can span multiple physical machines and/or be moved from one machine to another (e.g. migrated). In some embodiments, a VM may include one or more virtual drives (vdisks), as well as other data related to that VM (e.g. configuration files, utility files, and files supporting functionality such a snapshots supported by the VM Management Infrastructure). To the guest operating systems running on a VM, a vdisk looks like a physical disk drive. In different embodiments, the contents of vdisks may be stored in one or more files. In some embodiments a VM Management Infrastructure (e.g. a hypervisor), creates files to store the contents of vdisks. The hypervisor, for example, may create a folder containing files that correspond to each VM. The hypervisor can create files that store, for example, the contents of a vdisk, the BIOS state of a VM, metadata and information about snapshots taken by the hypervisor, or configuration information specific to VMs. Data associated with a specific VM can be stored in one or more files on a storage device according to various embodiments. In some embodiments, files can be used as examples of virtual machine abstractions. “In some embodiments the files associated with (at minimum) VMs 108 110 and 112 running in server 106, are stored on storage system 102.
In various embodiments, the storage system 102 stores meta-information identifying what stored data objects (such as files or virtual machine abstractions) are associated with a particular VM or vdisk. Storage system 102, in various embodiments stores data from VMs that run on server 106. It also stores metadata which provides mapping or identification of the data objects associated with specific VMs. In some embodiments, the mapping or identification of a specific VM includes mappings to the files that are associated with the VM. Storage system 102 may also store a portion or all of the files that are associated with specific VMs. Storage system 102 can refer to one or more physical or software systems that are configured to work in conjunction to manage and store data. This includes files and other data objects. “In some embodiments, the hardware component used to implement (at least partially) the storage system can be either disk or Flash, or a mixture of both.
FIG. According to some embodiments, FIG. 2 shows a source and destination storage systems before the replication of snapshots. In this example, the source storage system stores snapshot 212 which a user or other entity wishes to replicate on destination storage system. Snapshot 212, for example, was created from a data set in order to replicate the data on the destination storage system. In another case, snapshot 212 existed prior to initiating the replication process. Snapshot 212 can be a snapshot, a vdisk or a file from a VM. In some embodiments each of the source storage system 202, and destination storage systems 204 store VM data. In some embodiments, a data link 206 between source storage systems 202 and 204 and a control link 208 are established via a network. Data link 206 and the control link 208 can be established using a variety of network technologies. Examples of network technologies which can be used to create data link 206 or control link 208 are various forms Ethernet and FibreChannel. In some embodiments traffic between data link 206, control link 208 and a single network connection may be multiplexed. Data link 206 and the control link 208 can be implemented with one or more network connections on a transport level. For example, TCP/IP is used. In some embodiments each of the source storage system and destination storage systems 202 can be implemented as a system of storage, such as FIG. 1.
In various embodiments, the request to replicate snapshots 212 from destination storage systems 204 and 202 may be received by either destination storage systems 204 or source storage systems 202. In some embodiments snapshot 212 may be identified by a global unique identity, which is maintained by storage systems that maintain copies of the snapshot.
After receiving a request to replicate snapshots 212, the source storage system is configured to send metadata associated with each snapshot to destination system 204. The metadata for snapshot 212 may include a count of how many files are in the snapshot, information about the file names and sizes, and data about which blocks in each snapshot actually contain data. Source storage system sends metadata for snapshot 212 via data link 206 to destination system 204. This continues until the entire snapshot 212 is received by destination system 204. In certain embodiments, blocks of data are included in portions of snapshot. The blocks of data in snapshots 212 were created at a certain point in the history for the files in snapshots 212. Source storage system 200 may be configured to send portions of snapshot 212 to destination storage system 20 in a specific order. The predetermined sequence can be, for example, associated with ascending values of block identity. In another example the predetermined order may be associated to the order of the data blocks. Virtual snapshots are sometimes used to describe the parts of snapshot 212 that do not form the entire snapshot 212 and have been received by destination storage system 204. The snapshot does not materialize completely at the destination system immediately after creation. It is only fully realized when the asynchronous replica of its contents has finished.
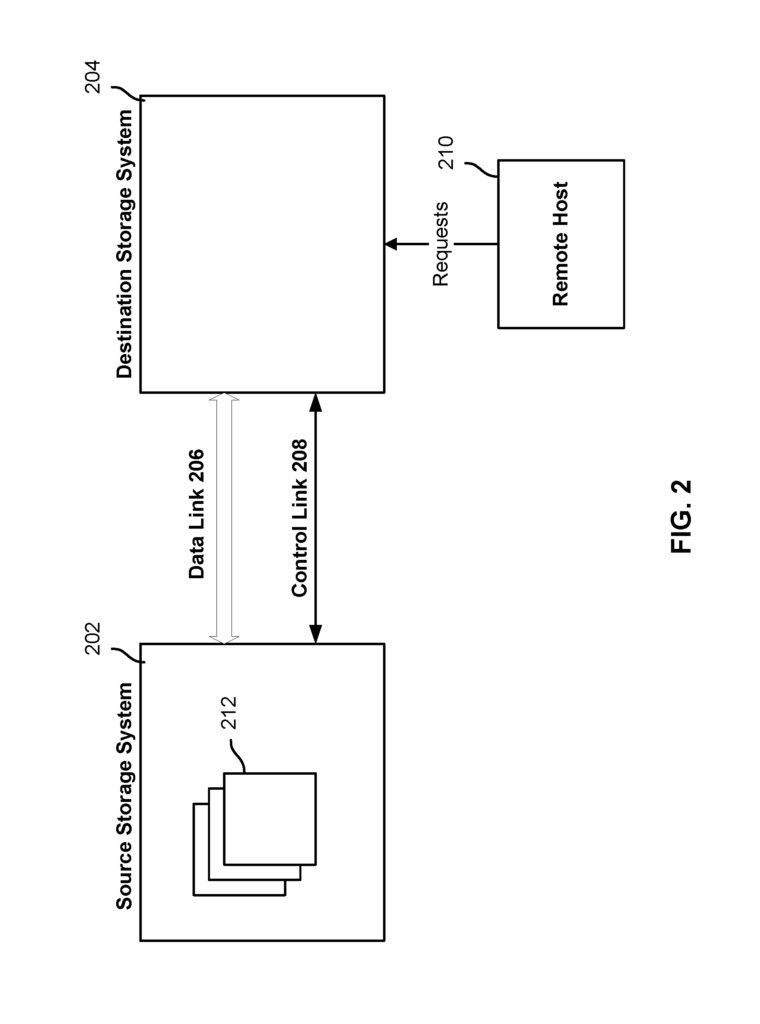
In certain embodiments, the destination storage system is configured to create a clone of snapshot 212 during an ongoing replication process. In various embodiments, a ?clone? A writable version of a snapshot is included in a “clone”. In various embodiments, a ?clone? The clone comprises a metadata set (e.g. a collection of one or multiple indices) which references (e.g. points to) the snapshot upon which it is based. This allows write operations on the clone to be written into the metadata set and for read operations, the snapshot can be used if there are no reads that can service the clone. In other words, when a read request is made to the copy, the data will be returned if it has already been written. If the data requested was present in the snapshot that the clone originated from, the snapshot will be used to determine the value. The clone at destination storage system is not a physical copy and therefore saves space.
As described below in more detail, data associated with the snapshot 212 may be read by the client (e.g. remote host 201) from the clone during the ongoing replicating of the snapshot 212 into destination storage system (i.e. before the destination storage system has completed replicating the snapshot 212). If the read operation received by the client is associated with a block or blocks that are not in the clone then those blocks will be obtained using the data associated to snapshot 212 which has been replicated on destination storage system 204. If the block(s), associated with the client’s read operation, are blocks in snapshot 212 which have not been replicated yet at destination system 204 then the read operation is delayed until destination system 204 has replicated the data. Destination storage system is configured in various embodiments to send an request (e.g. a control message), to source storage 202, over control link 208, to send the block associated with the read operations to destination storage 204 at a higher priority than usual from source storage 202. The block(s), associated with the read operations, are initially to be sent by source storage system to destination storage system according to a predetermined order of ascending values for block identity. In response to the request from destination storage 204 to send the blocks associated with the reading operation to the destination storage 204 at a higher priority than normal, the blocks associated with the reading operation could be sent earlier than they would’ve been based upon the predetermined order. The destination storage systems 204 may determine, based on metadata received for snapshot 212, whether or not the blocks associated with read operations are present. If, based on metadata received for snapshot 212 and the block(s), associated with the reading operation, are not present, destination storage system will return the appropriate data to the requestor, e.g. remote host 210.
In some embodiments, the network that controls link 208 uses must be operational in order to perform read operations on blocks that require communication between destination storage system and source storage system. If this is not the case, some embodiments will block read operations at destination storage system 204 indefinitely or fail, depending on the local requirements.
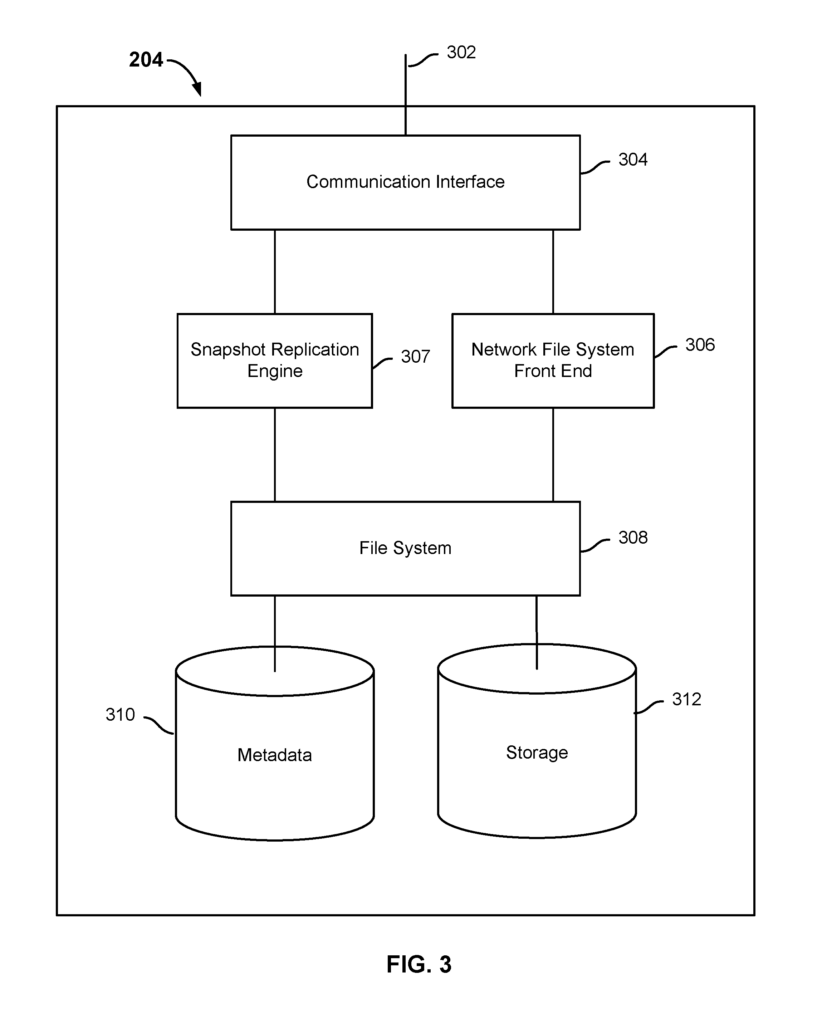
FIG. A block diagram 3 illustrates an embodiment of a data storage system that includes metadata, according to some embodiments. The destination storage system 204 shown in FIG. The example storage system shown in FIG. 3. The storage system 204 in the example includes a connection to a local network 302 as well as a communication interface such as a card for a local network or another interface. This allows the storage system to connect to a remote network, such as the network 104 shown in FIG. 1. The storage system 204 also includes a front end for the network file system 306 that is configured to process NFS requests coming from virtual machines running in systems like server 106 shown in FIG. 1. In different embodiments, the front end of the network file system is configured to associate NFS request received and processed, with a virtual machine or vdisk associated with the request, by using meta-information stored on the storage system 204, for instance. Storage system 204 comprises a file system configured and optimized for VM data. Metadata 310 in the example comprises a database or multiple databases that are configured to store metadata sets associated with different sets of data. A set of metadata, for example, may be associated to a VM or vdisk. Storage 312 can include at least one level of storage. Storage 312 can include at least two storage tiers. The first tier may be a solid state drive (SSD), and the second, a hard disk or other disk storage. In some embodiments, metadata 310 may include at least one index which includes mappings of storage 312 locations at which data (e.g. VM, Vdisk or File) associated with a metadata set is stored. A set of metadata at metadata 310 may include at least one index which is a snapshot of a data set stored in storage 312.
A clone can be created based on the source data set stored in storage 312. In some embodiments, a clone can be created using a snapshot from the set of metadata for the source data that is stored within metadata 310. The snapshot of source data that is used to generate a copy is sometimes referred as a “shared snapshot” in various embodiments. Metadata 310 stores data relating the clone to the metadata set associated with the original data. The clone is provided with at least some metadata from the source data. When a request is received that includes an operation to access data (e.g. read or write), to (e.g. a current or past state of), from a data set (e.g. a VM or vdisk or a file), a set metadata for the data set (e.g. a VM or a vdisk or a a file) will be retrieved. If the data that is associated with a request is a copy, it may be possible to access at least some of the metadata associated with its source.
Snapshot replica engine 307 facilitates the replication of data-associated snapshots from the source storage system into the storage system 204. In some embodiments the snapshot replication engine 307 receives metadata that is associated with a snap shot to be replicated on storage system 204. The metadata for the snapshot may include a count of how many files are in the image to be duplicated, names and sizes of those files, and information about which blocks in the image to be reproduced contain data. Snapshot replication engine 307 may store the received portions at storage 312, and update metadata 310 with a set or more indexes including mappings of storage 312 locations where the physical data of the snap is stored. Snapshot replication engine 307 can generate a copy of the not-yet-completed snapshot during ongoing replication. Snapshot replication engine 307 creates the clone in various embodiments by creating a set of metadata 310 indices that point to indices of the snapshot. File system 308 is the interface through which clients interact with storage system 204, and send read or write requests. In certain embodiments, clients receive read and/or writing operations via server message block (SMB), Fibre Channel or network file system. The file system 308 writes data associated with a write from a storage system 204 client to the clone to the set indexes associated with that clone. The data associated with read operations from a storage system 204 client to the clone can be serviced one of two ways. The data can be served directly from the storage 312. . . . In some embodiments read and/or writing operations from clients can be received via server message block (SMB), Fibre Channel, or network file system. If the requested data is not found in the set indices of the snapshot, the snapshot replication engine 307 will send a request for the source storage to send blocks of data with a higher priority to the storage 204. The source storage system can, for example, send the data blocks requested from the snapshot to the storage system in a predetermined order. Snapshot replication system 307 and the file system 308 will then be able to complete the read operation using the data blocks that have been sent from the source storage in a higher priority.
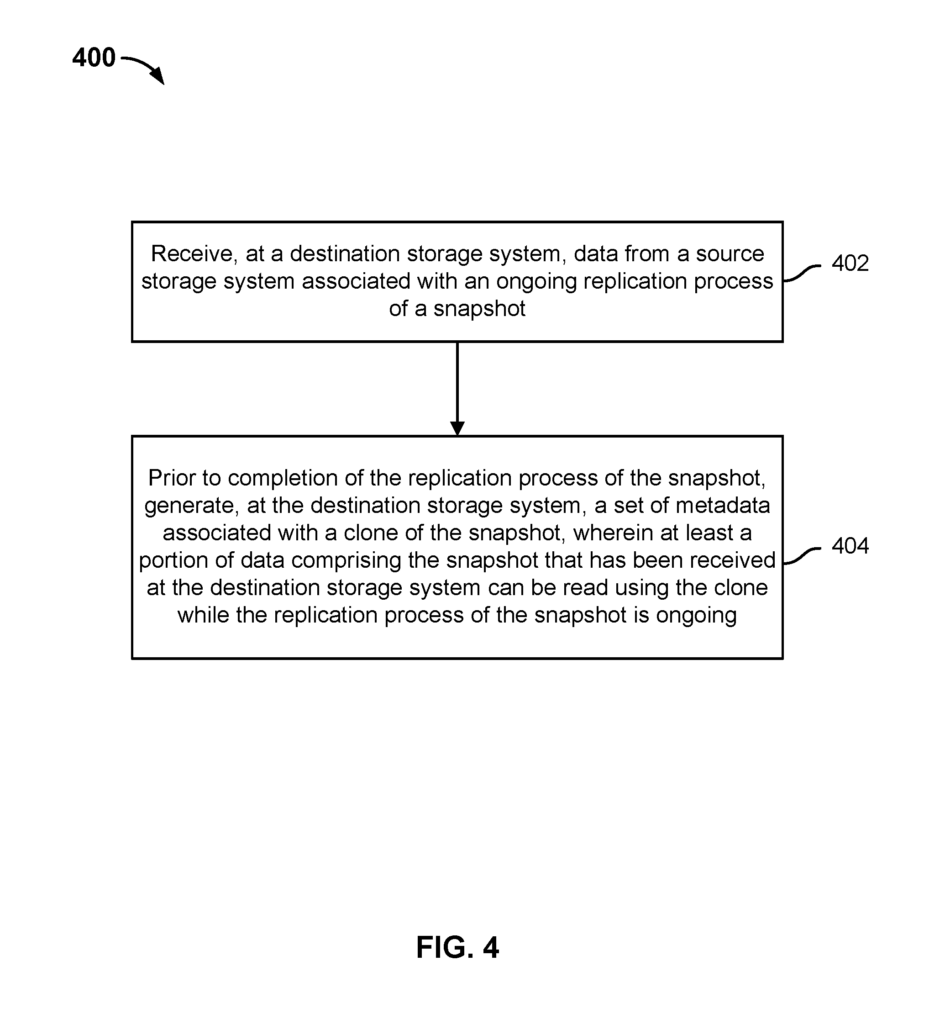
FIG. The flow diagram in Figure 4 shows an embodiment of the process for replicating snap-shot data according to some embodiments. In some embodiments process 400 can be performed entirely or partially by a storage device (e.g. storage system 102 in FIG. 1. and/or another processing system. For example, one that is configured to execute computer instruction which implements the steps of process 401.
At 402, at a storage system destination, data associated with a replication process is ongoing of a snapshot. In some embodiments the data associated the ongoing replication from a storage system source to a storage system destination also includes receiving metadata related to the snapshot. For example, a number of files within the snapshot that are to be duplicated, their names and sizes, or information about which blocks in the replicable snapshot actually contain data. In some embodiments, different portions of the image (e.g. blocks containing data), are transferred from the source storage system to the destination system as part of an ongoing replication of the picture until it is completely replicated. As portions of a snapshot arrive at the destination system, they are stored on a physical device. A set of indexes is updated continuously to store mappings between logical offsets and physical offsets where the snapshot data are stored.
At 404, prior to the completion of the replicating process of a snapshot, a metadata set associated with a copy of the snap shot is generated. At least a portion data of the snapped that have been received by the destination storage system, can be read while the replication of the picture is in progress. At the destination system, a clone that has not been fully replicated is created. “In various embodiments, creating the clone comprises generating a set of one of more indices that are associated with it and point to the set or indices of the snapshot at destination storage system.
The destination storage system receives a read request for a value of data associated with the snapshot before the replicating process is complete. The destination storage system receives a read operation for the clone that contains data from the snapshot. (e.g. data that can’t be found within the clone set of indexes).
The destination storage system determines that the requested data has not been received by the destination system yet from the source system. The data requested is searched first in the copy, but is not found in the copy. Therefore, the pointer of the clone to one or more snapshot indices is used to access snapshot data that has been received so far at the destination system. It is determined, however, that the data requested that is associated with a snapshot has not been received by the destination system. Therefore, the read operation can’t be performed until the data requested is received.
Click here to view the patent on Google Patents.
Leave a Reply