Invented by Scott B. Miserendino, Robert H. Klein, Ryan V. Peters, Peter E. Kaloroumakis, BluVector Inc
Machine learning is a subset of artificial intelligence that enables computers to learn and make predictions without being explicitly programmed. By analyzing vast amounts of data, machine learning algorithms can identify patterns and anomalies that may indicate the presence of malware. This technology has revolutionized the field of cybersecurity, allowing organizations to stay one step ahead of cyber threats.
The System and Method for Machine Learning Model Determination and Malware Identification offers a comprehensive solution for businesses seeking to enhance their security posture. This system combines the power of machine learning with advanced algorithms to determine the most suitable model for malware identification. By continuously analyzing new data and adapting to evolving threats, this system ensures a high level of accuracy in detecting and mitigating malware attacks.
One of the key advantages of this system is its ability to automate the process of model determination. Traditionally, organizations had to manually select and fine-tune machine learning models, which required significant time and expertise. With this system, businesses can save valuable resources by relying on automated model determination, allowing security teams to focus on other critical tasks.
Furthermore, the System and Method for Machine Learning Model Determination and Malware Identification offers real-time monitoring and alerts, enabling organizations to respond swiftly to potential threats. By continuously analyzing network traffic, file behavior, and system logs, this system can detect and block suspicious activities before they cause significant damage. This proactive approach to cybersecurity is crucial in today’s rapidly evolving threat landscape.
The market for this technology is driven by several factors. Firstly, the increasing frequency and complexity of malware attacks have made traditional signature-based detection methods obsolete. Machine learning models offer a more robust and dynamic approach to identifying and preventing malware, making them an attractive solution for businesses across various industries.
Secondly, the growing adoption of cloud computing and the Internet of Things (IoT) has expanded the attack surface for cybercriminals. As more devices and systems become interconnected, the need for advanced malware identification and prevention becomes even more critical. The System and Method for Machine Learning Model Determination and Malware Identification can seamlessly integrate with cloud platforms and IoT devices, providing comprehensive protection across the entire network.
Lastly, regulatory requirements and compliance standards are driving the demand for advanced cybersecurity solutions. Organizations are under increasing pressure to protect sensitive customer data and ensure the privacy of their users. By implementing a robust system for malware identification, businesses can demonstrate their commitment to cybersecurity and meet regulatory obligations.
In conclusion, the market for System and Method for Machine Learning Model Determination and Malware Identification is witnessing rapid growth due to the rising threat of malware attacks and the need for advanced cybersecurity solutions. This technology offers businesses a comprehensive and automated approach to malware identification, enabling them to stay ahead of cyber threats. As organizations continue to prioritize data security, the demand for this system is expected to grow, making it a promising investment for both cybersecurity vendors and businesses seeking enhanced protection.
The BluVector Inc invention works as follows
The method produces a parent classifier model in one location and provides it to one or more in-situ retraining systems at a different location. It adjudicates the class determination of the parent classifier over varying samples evaluated by the system. The method creates an in-situ classifier in one place and provides it to another in-situ system in a different area. It then adjudicates class determinations of the parent model over a plurality of samples evaluated by that system. It determines the minimum number of adjudicated sample required to begin the insitu process.
Background for System and Method for Machine Learning Model Determination and Malware Identification
Machine learning is a method that utilizes the high-speed processing power of computers to run algorithms in order to predict behavior or characteristics. Machine learning techniques can execute algorithms using a collection of training samples with a label or class, for example, a group of files that are known to be malicious or benign. This allows them to learn the characteristics or behaviors of unknown objects, like whether they will behave maliciously or benignly.
Many current approaches to machine-learning use algorithms that require static training sets. These machine learning methods that use algorithms that require static training sets (such as decision trees) assume all samples will be available during training. On-line, or continuous learning algorithms are supervised machine-learning algorithms that update their model with each new sample. These algorithms, however, assume that each new sample is classified by a user with expertise.
Batch mode active learning is a relevant machine-learning method. BMAL retrains a classifier based on a set of new samples, in a repeatable process. BMAL focuses, however, on selecting unlabeled sample to be presented to the user for adjudication. BMAL: Repeated learning is conducted until a certain objective performance criteria has been met. BMAL also does not cover situations where training data are split across multiple locations, and the original test and training data must be sent back to the user for new samples.
Patents and published applications that describe other relevant prior art methods can be found below. U.S. Pat. No. 6,513,025 (?the ‘025 patent? Patent 6,513,025 (?the ‘025 patent? The training sets are divided into time intervals, and multiple classifiers are generated (one for every interval). In the preferred embodiment, time intervals are periodic/cyclic (fixed frequency). The ‘025 Patent uses dependability models to determine the classifier to be used. This patent also includes methods for adding training samples and updating the classifier. “The ‘025 Patent is also limited to Telecommunications Network Lines.
U.S. Pre-Grant Publication No. 20150067857 (?the ‘857 publication?) This publication is aimed at an “In-situ trainable intrusion detection system.” The system described in the publication ‘857 is based upon semi-supervised (unlabeled) learning. The learning is based not on files but rather network traffic patterns (netflow, or other flow metadata). The ‘857 publication only uses a Laplacian Regularized Less Squares learner. It does not allow users to choose between classifiers, or analyze the performance of multiple classifiers. The ‘857 publications also uses only in-situ (samples taken from the client enterprise) samples.
U.S. Pre-Grant Publication No. 20100293117 (?the ‘117 publication?) The publication titled ‘Method for Facilitating Active Batch Learning’ is entitled 20100293117. The document entitled ‘Method and System for Facilitating Batch Mode Active Learning,? The method reveals a way to select documents for inclusion in a training set based on an estimate of the?reward? The reward may be based on the uncertainty of a document that is not labeled or its length. The publication ‘117 does not reveal how to detect malicious software or files. U.S. Pre-Grant Publication No. 20120310864 (?the ‘864 publication? 20120310864 (?the ‘864 publication? This technique is primarily used to analyze image, audio and text data. Binary files are not included in this application. The ‘864 publication also requires a stop criteria, which is usually based on predetermined levels of performance. The ‘864 method of publication does not accommodate in-situ training, such as the need to provide partial training samples, or express those as feature vectors rather than maintaining the entire sample.
Existing machine learning techniques reveal learning algorithms and processes, but they do not disclose the method of augmenting or recreating a classifier using data that is not available to the original trainer. The existing machine learning techniques don’t allow training with data samples which an end-user does not want to share with a third party who was initially responsible for the machine learning.
Also, prior art malware detectors have an inherent issue in that each instance of a mal-ware sensor (antivirus, IDS etc.) has a different signature or rule set. If their signatures or rules sets are updated, they will be identical. Since each cyber-defense sensor deployment is identical in such cases, a malicious actor or malware author can acquire the sensor, test it, and modify their malware until they are not detected. All such sensors would be vulnerable.
Described in this document are embodiments which overcome the disadvantages associated with the prior art. This and other benefits are provided by a batched, supervised in-situ classifier retraining method for malware identification and heterogeneity. The method creates an in-situ classifier in one place and provides it to another in-situ system in a different area. It then adjudicates class determinations of the parent model over the plurality samples evaluated by that system. It determines a minimal number of adjudicated sample required to begin the insitu process.
Described herein are embodiments for a system for in-situ classification retraining to identify malware and models heterogeneity. The embodiments described here overcome the above problems. As an example, embodiments allow for the enhancement of a machine-learning-based classification model using user-driven correction or confirmation of the model’s prediction of class and in-situ training. In-situ refers to the conduct of machine learning at a physical location where a classifier is installed. When applied across multiple instances, embodiments enable each instance to create its own model.
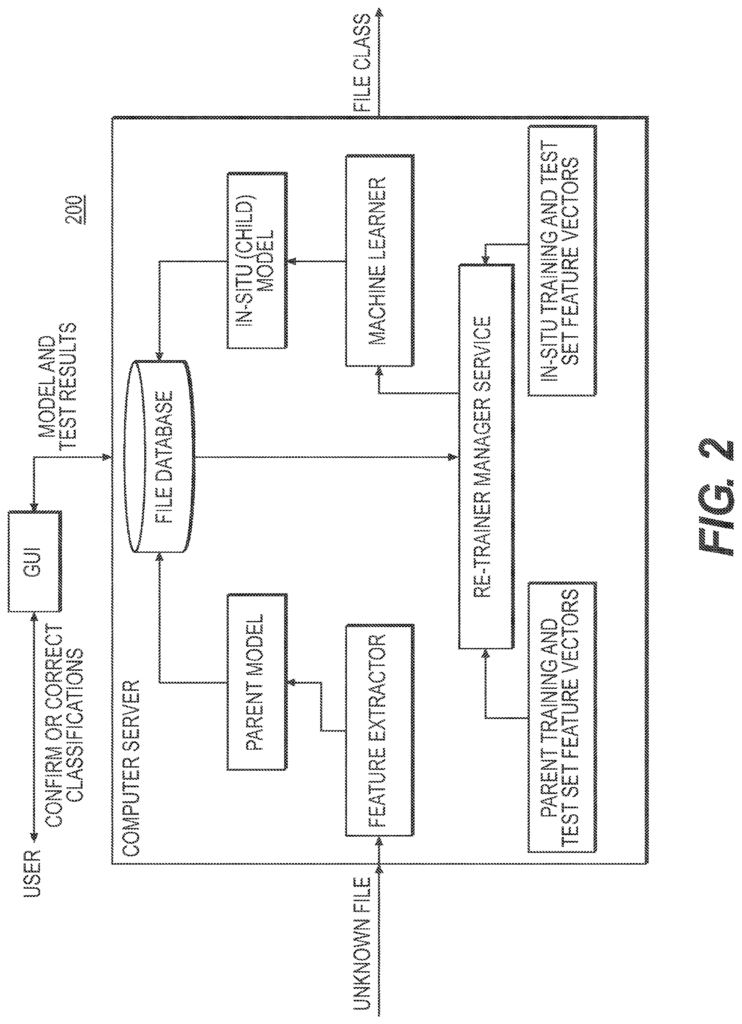
A preferred embodiment” is used to solve the problem of determining whether software files or applications that are unknown/untrusted are benign or malicious. This method creates child classifiers that are not only unique, but also maintain or improve statistical performance. Particularly, embodiments were shown to reduce the false positive rate of software classification. Embodiments allow for retraining the parent classifier by combining the original training sets with a supplemental set of training data, also known as an in-situ set of training data. The in-situ set is generated inside a local instance, removing the need to share potentially sensitive or proprietary information with anyone else?including the party that constructed the parent classification. Users may, in embodiments, elect to establish trusted relationships with others and securely share all or part of their in situ training data by using an abstraction.
The embodiments described in this document include many significant differences from the prior art. In contrast to the prior art described above embodiments may require recurring batches of new samples at non-fixed periods prior to retraining, but does not assume that every new sample is classified by an expert or will otherwise be eligible to be included in a batch for retraining. This makes embodiments of the method and system distinct from on-line learning techniques.
In addition, unlike BMAL, embodiments permit a user the freedom to select samples to judge at their discretion. In embodiments, the user decides how many cycles of retraining are needed rather than relying on an objective criteria. In embodiments, the data for training is divided between different locations. The original data from training and testing must be sent back to the user.
Furthermore, unlike the ‘025 Patent, the in situ learning of embodiments described herein requires the complete replacement the current classifier and not the division of the input space or continued use of older models. The embodiments described are also user-driven batch (not all events included in additional learning). In another aspect of the disclosure, batch learning can be driven by an automatic process. In contrast to the ‘857 publications, in-situ implementations described herein can be fully supervised as opposed to Laplacian Regulated Least Squares learner which is semi-supervised. Although unsupervised or semi-supervised learning can be implemented, supervised is preferred. For example, supervised learner may result in the classification of an unknown sample. In contrast to the ‘117 publications, embodiments use all labeled sample. The ‘864 publication is not the same as the embodiments, which have a simple stop criteria (single-pass with the user deciding whether performance is satisfactory) that does not require any calculation of distance functions between the batch unlabeled and the remaining unlabeled samples and does not select training elements on the basis of an objective function.
Embodiments” allow users to retrain classifiers based on machine learning in situ, before the deployment of classification software/hardware by the user. Retraining improves the performance of the classifier (e.g. reducing false positives or false negatives). In-situ retention allows for the creation of unique versions of the classification models. This version can be specific to the instance or user. A tailored model ensures that malware producers cannot test their malware against detection technology before attempting to compromise a user’s network. The tailoring can also be used to create biased models that target proprietary or sensitive malware. This is not available to the creators of the classifier parent model. In certain embodiments, the sharing of samples can be made easier among multiple users using abstracted representations. These representations completely hide the content of the sample but allow other users to use it for retraining. Users can also choose to share models that have been trained at one location among other locations within their network, or with trusted partners. The models that are generated by in-situ training can be exported or imported to trusted partners.
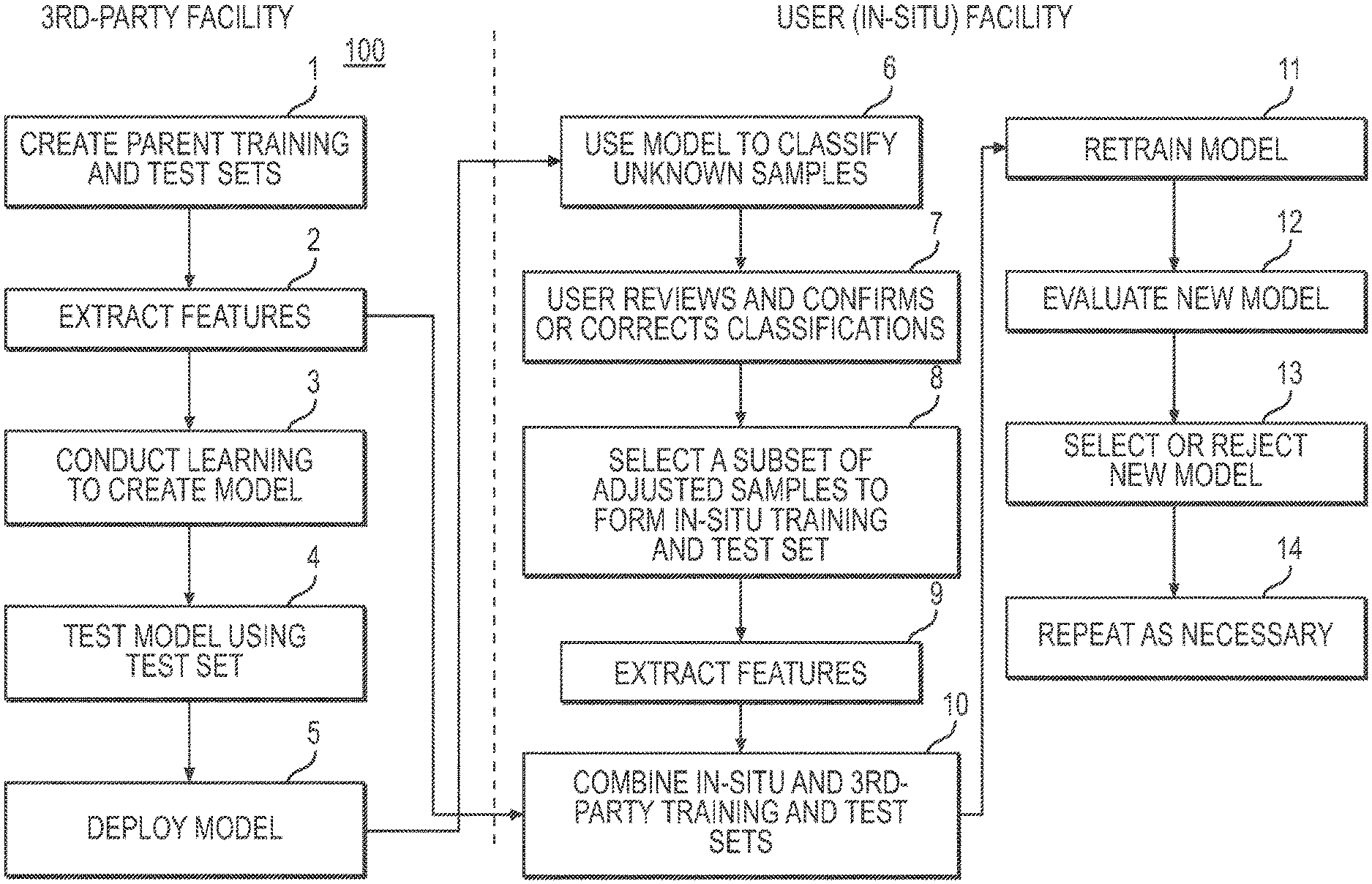
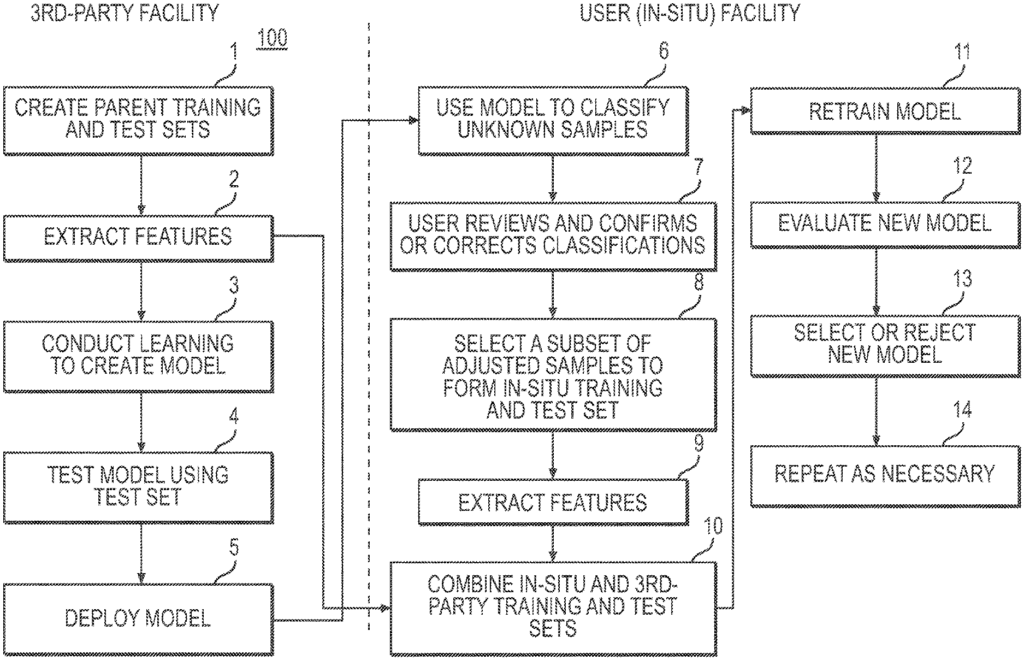
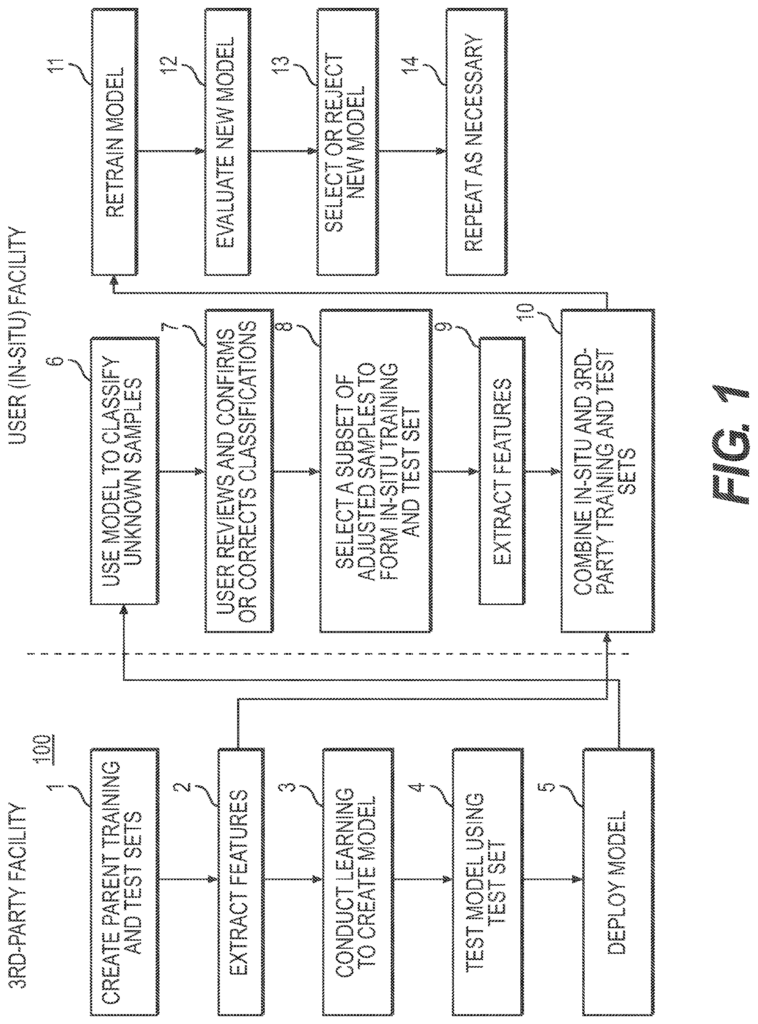
Referring to FIG. In Figure 1, an exemplary embodiment 100 of a classifier retraining method for malware detection and model heterogeneity is shown. The method 100 is described in fourteen (14) steps. As shown in FIG., method 100 can be implemented using a software/hardware architectural design. 2. The in-situ training process can be performed at two locations that are physically separate, the?3rd Party Facility? In FIG. 1, the retraining process occurs at two physically separated locations, denoted as?3rd-Party Facility? Figure 1. Third-parties (e.g. an enterprise selling malware detection hardware/software), build an initial version (see blocks 1-5), known as the base classification. This base classifier uses a supervised machine-learning algorithm such as decision trees or artificial neural networks. Block 1 is built by the third party. Learning is done using a set of training samples that are identical in type and cover all classes. In one embodiment, only two classes can be used: malicious and benign. Samples may include executable computer program files (PE32+, DMG, DMG+, ELF etc.). Files used by popular computer software (Microsoft Word and Excel, PDF, etc.). Block 2: Third party extracts (e.g. features that are more likely to appear in malicious or benign files) features from the training data (e.g. as extracted feature vectors), then conducts learning using supervised machine-learning algorithm to create a new model, block 3, and tests the model with the test data, block 4. This classifier can be constructed according to the methods described in U.S. Patent Application Ser. No. The reference is made to 14/038,682 published as US20140090061, which is herein incorporated. “One or more classifiers can be created to cover a variety of file types.
Once a third party has created the classifier, it is sent/deployed as a classifier to the user facility (e.g. a customer), block 5. This deployment 5 can be part of a multiple-user facility (e.g. multiple customers) multiple-instance deployment. User facilities house system hardware and software. 2. The term “user facility” is used in this document to refer to the entire enterprise of an end-user. This enterprise may have multiple locations, with one or several in-situ training systems installed at any or all locations. The third-party delivers the classifier model as well as the extracted feature vectors. Feature vectors represent a sample in a summary manner based on certain properties or attributes. A feature vector is a representation abstracted of the sample, which obfuscates its content and simplifies model training. Features can include file header properties, existence or parts of a particular file, binary sequences called n-grams and computations on the binary representation, such as entropy. The embodiments of the present invention are characterized by the transfer to the user’s facility of this generalized version of the original test and training sets.
Referring to FIG. The original base classifier created by a third party becomes the first classifier parent in the repeatable process. This base classifier is used by method 100 to evaluate unknown content in the user network, predicting a classification (e.g. benign or malicious) of each sample. In one embodiment, the user can use the system GUI to inspect all or some of the predicted class and determine whether the sample is malicious or benign (e.g. confirm or correct classifications). A further aspect of this disclosure is that the in-situ training system can inspect some or all predicted classes without human interaction and determine if the sample has a benign or malignant nature (e.g. confirms or incorrects classifications). Adjudication is the act of correcting or confirming a classification. In one embodiment, the retrainer (e.g. instantiated as a service) monitors user adjudication activities and determines when enough in-situ sample have been adjudicated.
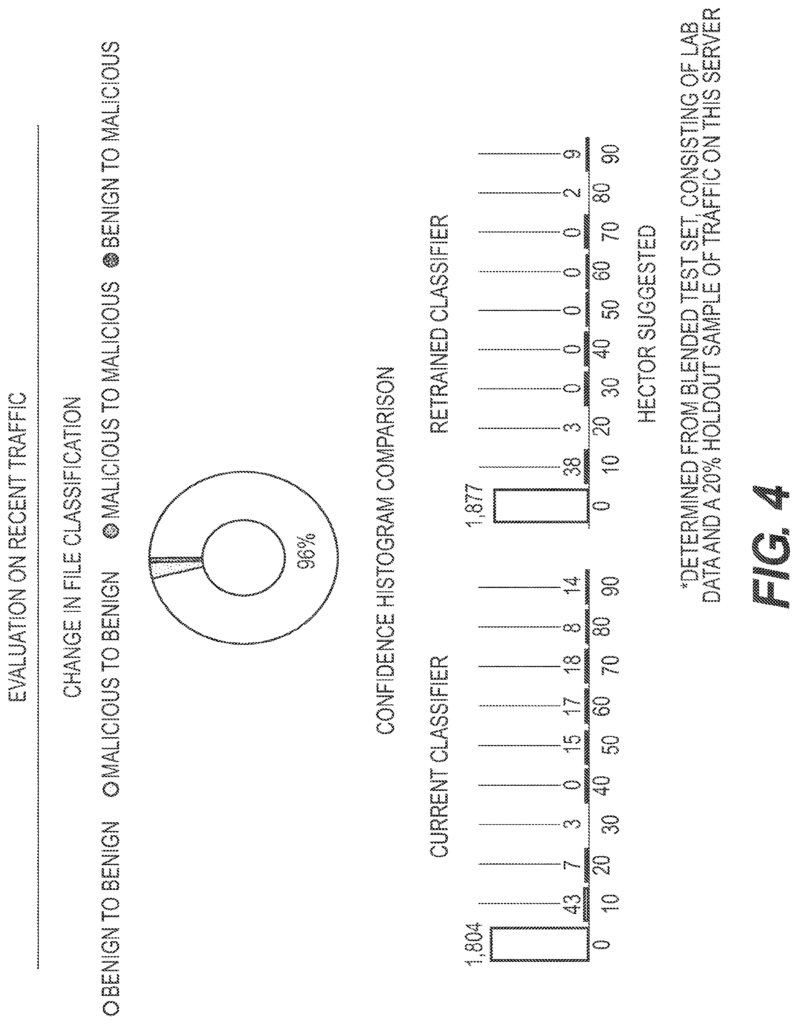
In embodiments, a threshold number of adjudicated event must be reached before a retrain can occur. The user can elect to retrain when they reach the threshold of adjudicated event. Adjudicated sample data may be stored in one or more systems for in-situ training. Sharing information about adjudicated sample with other users is also possible, provided that a trusting relationship exists. The retrain manager, when the user initiates the retrain, creates the training and test sets from the adjudicated samples in situ, block 8. The in-situ training system can initiate a retrain without any human involvement. A subset of adjudicated samples can be used to select the training and test sets. Block 9 is where Retrain Manager can extract feature vectors both from the retrain test and training sets. The method 100 can then blend the in-situ vectors with those of the base classifier (and any feature vectors shared by sharing partners, if applicable), block 10. In a different mode, an embodiment could use a subset from the feature vectors of the base classifier (and any from sharing partner’s, if applicable) without using any additional in situ samples. This subset can be randomly selected from all the available feature vectors. In one aspect of a blending method known as additive method, in-situ feature vectors can be added to parent classifier feature vectors. In another aspect, a second implementation of blending, also known as a method for replacing feature vectors, may use the in-situ feature vectors to replace an equal number. In a third blend implementation known as the hybrid method, it is possible to add the in-situ feature vectors to a subset the parent classifier vectors. The training set may be larger than the parent set, but smaller than that created using the additive method. By using a hybrid blend, the user can limit the impact of in-situ sample on the new model. Block 11: A new classification model will be trained by the machine-learning algorithm that was used to create parent/base classifier. Block 12: Once the new classifier has been created, it is evaluated using the retrain testing set. This includes feature vectors both from the third party (the base classifier test set) and user facility (the retrain testing set). The evaluation 12 is performed on both unlabeled and labeled samples that are not part of the training set. An evaluation GUI can be provided for the user to assist them. Embodiments can also provide an automated recommendation (e.g. provided by the retraining supervisor) as to which classification is better. “Figures 3 and 4.
Referring to FIG. In embodiments, at the end the evaluation period the user can choose to accept the new classifier in place of the current parent classification or reject it, and keep the existing parent classification, block 13. A second aspect of the disclosure is that the in-situ training system can accept the new classifier, replace the current classifier, or reject it, and keep the classifier. The process can be repeated in either case. The user can choose to do so or the system will automatically do it. Block 14 is the in-situ training system. After a new in situ classifier has been accepted, it will become the base classifier/parent for the next in-situ training 100. The user may also elect to deploy the model of a retrained classification to all in-situ training systems within their enterprise, replacing the parent classifier for each system with the new trained classifier. The in-situ training system can, in another aspect, deploy the retrained model without any human intervention to all the in-situ training systems in their enterprise.

In embodiments successive retraining uses the previous training and testing set as a base for augmentation. The system for in-situ classification retraining can be configured to anchor. The retraining can be done using the original base classifier from a 3rd party and the associated test and training set. “When retraining anchor mode, all subsequent anchored trainings are done using the original base classification, original base classification training, or original base-classifier test set.
Click here to view the patent on Google Patents.
Leave a Reply