Invented by Werner Paulus Josephus De Bruijn, Aki Sakari Harma, Arnoldus Werner Johannes Oomen, Koninklijke Philips NV
The Koninklijke Philips NV invention works as follows
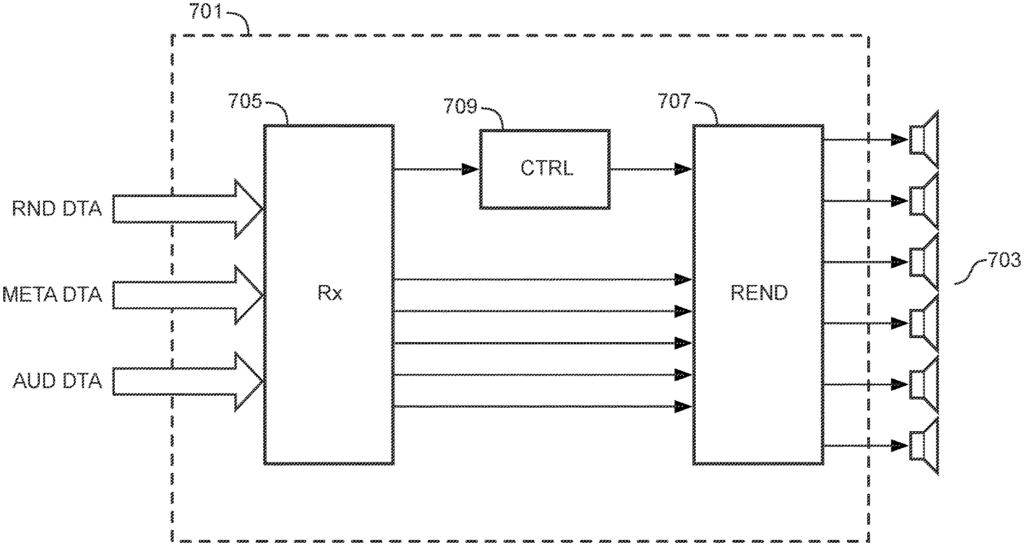
An audio-processing apparatus comprises a render configuration data, including audio transducer positions data for a group of audio transducers (703) and a receiver (705), which receives audio data, including audio components. A renderer (707), which generates audio transducer signal for the set audio transducers, from audio data. The renderer (7010) can render audio components according to a plurality rendering modes. The render controller (709), based on audio transducer data, selects rendering modes from the plurality. The renderer (707 can use different rendering modes to render different subsets from the set audio transducers. The render controller (709) selects independently the rendering mode for each subset of the audio transducers set (703). The render controller (709), in response to the position of a first audio transmitter of the set audio transducers (703), can select the mode of rendering for that audio transmitter. This approach can provide better adaptation, for example. The approach may provide improved adaptation, e.g.

Background for Audio Processing Apparatus and Method Therefor
In the last decade, the flexibility and variety of audio applications have increased enormously. The variety of audio rendering apps is vast. The audio rendering systems are also used in a variety of acoustic settings and for varying applications.
Traditionally, spatial sound systems have been designed for one or several specified loudspeaker arrangements. The spatial experience depends on how closely the actual configuration of loudspeakers matches the nominal configuration. A high-quality spatial experience can only be achieved with a system set up correctly. According to the specified loudspeaker setup.
However the requirement to use a specific loudspeaker setup with a typically high number of speakers is cumbersome. In fact, consumers perceive a major inconvenience when using e.g. The need to place a large number of speakers at specific locations is a requirement for home cinema surround sound system. Most practical surround sound speaker setups deviate from an ideal setup because users find it difficult to place the loudspeakers in the best locations. The spatial experience and experience provided by these setups are suboptimal.
In recent years, there has been a strong trend for consumers to demand less strict requirements regarding the location of loudspeakers. They also want the system to be able to provide high-quality sound, but they still need it fit their environment. As the number of speakers increases, these conflicting demands become more apparent. The issue has also become more important due to a recent trend to provide full three-dimensional sound reproduction, with sound coming from multiple directions to the listener.
Audio encoding format supporting spatial audio has been developed.
Well-known audio coding techniques like DTS or Dolby Digital create a coded, multi-channel audio that represents the spatial picture as a fixed number of channels around the listener. The spatial image will not be optimal if the loudspeaker configuration is different than the one that corresponds with the multi-channel audio signal. Audio coding systems that are channel-based cannot cope with different loudspeaker numbers.
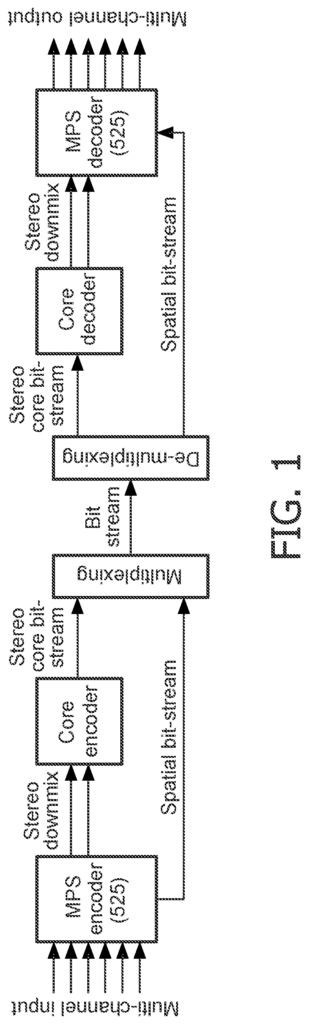
(ISO/IEC MPEG-2) provides a multichannel audio coding system where the bitstream format includes both a 2-channel and 5-channel mix of audio signals. The 2 channel mix of the audio signal is reproduced when the bitstream is decoded with an ISO/IEC MPEG-1 decoder. “When decoding the bitstream using a MPEG-2 encoder, three additional data channels that are combined with the stereo channels to create the 5-channel mix of the audio signals (de-matrixed), is decoded.
(ISO/IEC MPEG Surround) MPEG Surround is a multichannel audio coding software that allows mono or stereo coders to extend to multichannel audio applications. FIG. FIG. “Using spatial parameters derived from the analysis of the multichannel input signal, an MPEG Surround encoder can recreate the spatial picture by controlling the upmixing of the mono or stereo signal in order to obtain a multiple channel output signal.
MPEG Surround is able to decode the same bitstream of a multichannel audio signal by devices that don’t use multichannel speakers. MPEG Surround binaural encoding is used to reproduce virtual surround on headphones. This mode allows for a realistic surround sound experience to be achieved using standard headphones. A second example would be the pruning of multichannel outputs at higher orders, such as 7.1 channels. “Another example is the pruning of higher order multichannel outputs, e.g. 5.1 channels.
As has been mentioned, in recent years the variety and flexibility of rendering configurations for spatial sound have increased dramatically. More and more formats are now available to mainstream consumers. It is important to have a flexible audio representation. With the introduction of MPEG Surround, important steps were taken. Audio is still produced for a particular loudspeaker configuration, e.g. An ITU 5.1 loudspeaker configuration. Reproduction of different setups, including non-standard ones (i.e. The specification does not specify flexible or user-defined loudspeaker configurations. There is a desire for audio encoding to be independent of predetermined loudspeaker configurations. The decoder/rendering is more and more preferred to be able to adapt to different loudspeaker configurations.
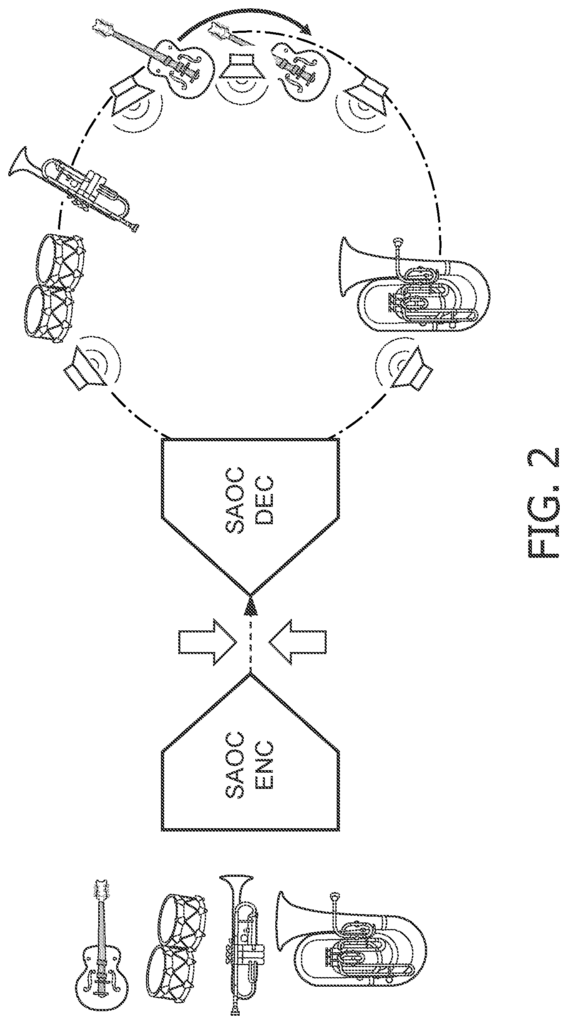

In order to allow for a more flexible presentation of audio, MPEG standardized a standard format called?Spatial Object Coding’. (ISO/IEC MPEG-D SAOC). SAOC is more efficient than multichannel audio coding such as DTS and Dolby Digital, or MPEG Surround. It codes individual audio objects, rather than audio channels. While in MPEG Surround each loudspeaker can be considered as originating from a mix of different sound objects, SAOC allows interactive manipulation of individual sound objects within a multi-channel mix, as illustrated in FIG. 2.
SAOC creates a stereo or mono downmix, just like MPEG Surround. Additional object parameters are also calculated and included. The user can manipulate these parameters on the decoder to control different features of individual objects such as level, position, equalization or even apply effects like reverb. FIG. FIG. A rendering matrix maps individual sound objects onto loudspeaker channel. SAOC provides a flexible and adaptable approach, allowing audio objects to be transmitted in addition only to reproduction channels. The decoder can place audio objects in any position, as long as the area is sufficiently covered by loudspeakers. So, there is no relationship between the audio transmitted and the loudspeaker configuration. This can be useful for example. In a typical living-room setup, the loudspeakers almost never are at their intended position. SAOC decides where objects in the scene are to be placed (e.g. FIG. This is not always desirable from an artistic perspective. The SAOC standard provides ways to transmit default rendering matrices in the bitstream. This eliminates the decoder’s responsibility. The methods provided rely either on fixed reproduction setups, or unspecified syntax. SAOC doesn’t provide a standard way to transmit an audio scene independent of loudspeaker configuration. SAOC also isn’t well-equipped to render diffuse signal components faithfully. “Although there is a possibility to include a Multichannel Background Object to capture diffuse sound, the object is tied to ONE specific loudspeaker setup.
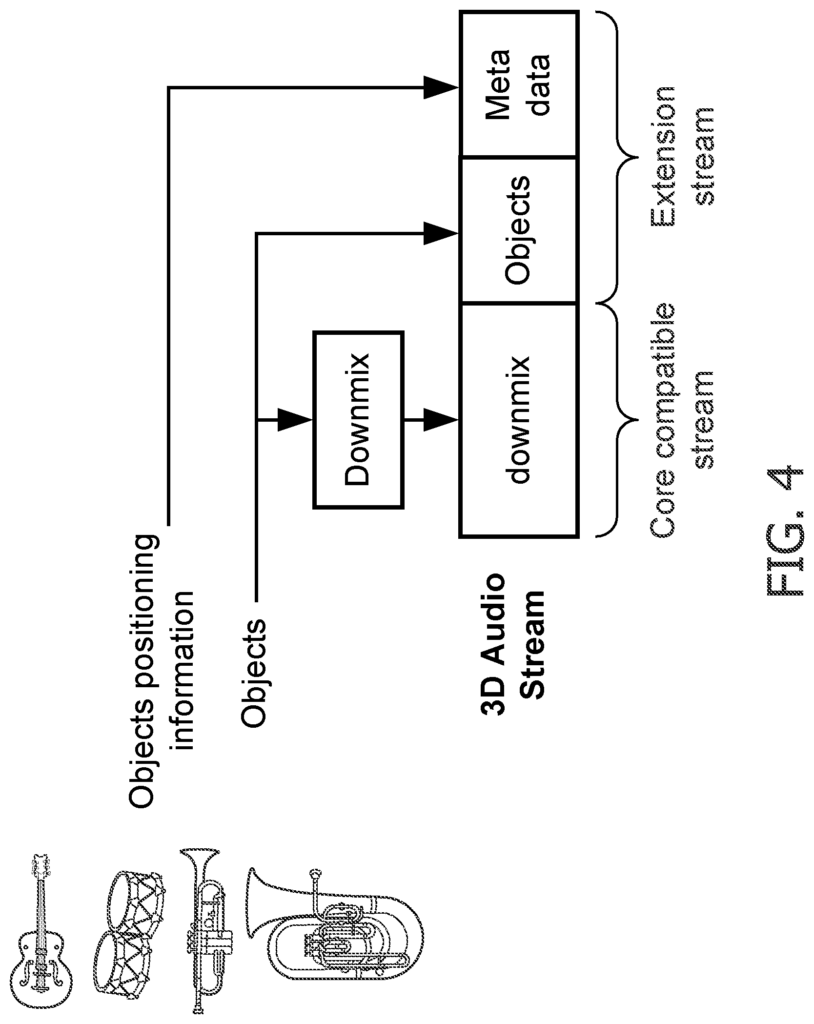
DTS Inc. has developed a new specification for 3D audio. DTS, Inc. has developed Multi-Dimensional Audio (MDA?) Open object-based audio authoring and creation platform, Multi-Dimensional Audio (MDA?) was developed by DTS Inc. to speed up next-generation content production. The MDA platform adapts to all speaker configurations and quantities. It supports audio objects as well as channel. The MDA format allows for the transmission of an old multichannel downmix, along with sound objects. The MDA format also includes object positioning information. In FIG., the principle of creating an MDA audiostream is shown. 4. The MDA method receives the sound objects separately in the extension streams and they can be extracted from the downmix. The multi-channel downmix resulting from the MDA approach is rendered with all of the objects individually available.
The objects can be made up of stems. These stems are essentially grouped tracks or objects. An object can be made up of several sub-objects. MDA allows a multichannel mix to be transmitted along with audio objects. MDA transmits 3D positional information for each audio object. The 3D data can be used to extract the objects. The inverse matrix can also be sent, which describes the relationship between the objects, and the reference mix.
The MDA description is likely to transmit sound-scene information by assigning angles and distances to each object. This indicates where the object should placed relative to, e.g. The default forward direction. This information transmits the position of each object. This works well for point sources, but does not describe large sources (like e.g. This is useful for point sources, but does not describe diffuse sound fields such as ambience or a choir. After all point sources are removed from the reference mix a multichannel ambient mix is left. The residual is also fixed to a particular loudspeaker configuration in MDA, similar to SAOC.
Both the SAOC and MDA approach incorporates the transmission of audio objects which can be individually modified at the decoder’s side. The SAOC approach provides information about the audio objects through parameters that characterize the objects in relation to the downmix. The difference between the two approaches is that SAOC provides information on the audio objects by providing parameters characterizing the objects relative to the downmix (i.e. They can be independently generated from the downmix on the decoder’s side. Position data can be transmitted for audio objects in both approaches.
At the moment, an ISO/IEC MPEG standard MPEG 3D Audio, which will facilitate the transport and rendering 3D audio, is in preparation. MPEG-3D audio is intended to be part of the MPEG H suite, along with HEVC (High Efficiency Video Coding) and MMT systems layer. FIG. FIG. 5 shows the high-level block diagram of the MPEG 3D Audio system as it is currently intended.
The approach will also support scene-based and object-based formats in addition to the channel format. The system should be able to scale its transparency and quality with increasing bitrate. As the data rate increases, the degradation caused by encoding and coding should continue decreasing until it becomes insignificant. This requirement is problematic for the parametric coding methods that were used in the past. HE-AAC v2, MPEG Surround (SAOC), USAC, and SAOC. The parametric data tends not to fully compensate for information loss in the individual signals, even at high bit rates. In fact, the inherent quality of the model will limit the quality.
MPEG-3D Audio aims to deliver a bitstream that is independent of any reproduction setup. The reproduction possibilities envisaged include flexible loudspeaker configurations up to 22 channels, as well virtual surround over headphones or closely spaced speakers.
US2013/101122A1 discloses a object-based audio content generating/playing device that allows the object-based audio content to be played with at least one WFS scheme or a multichannel surround scheme, regardless of the reproducing environment of an audience.
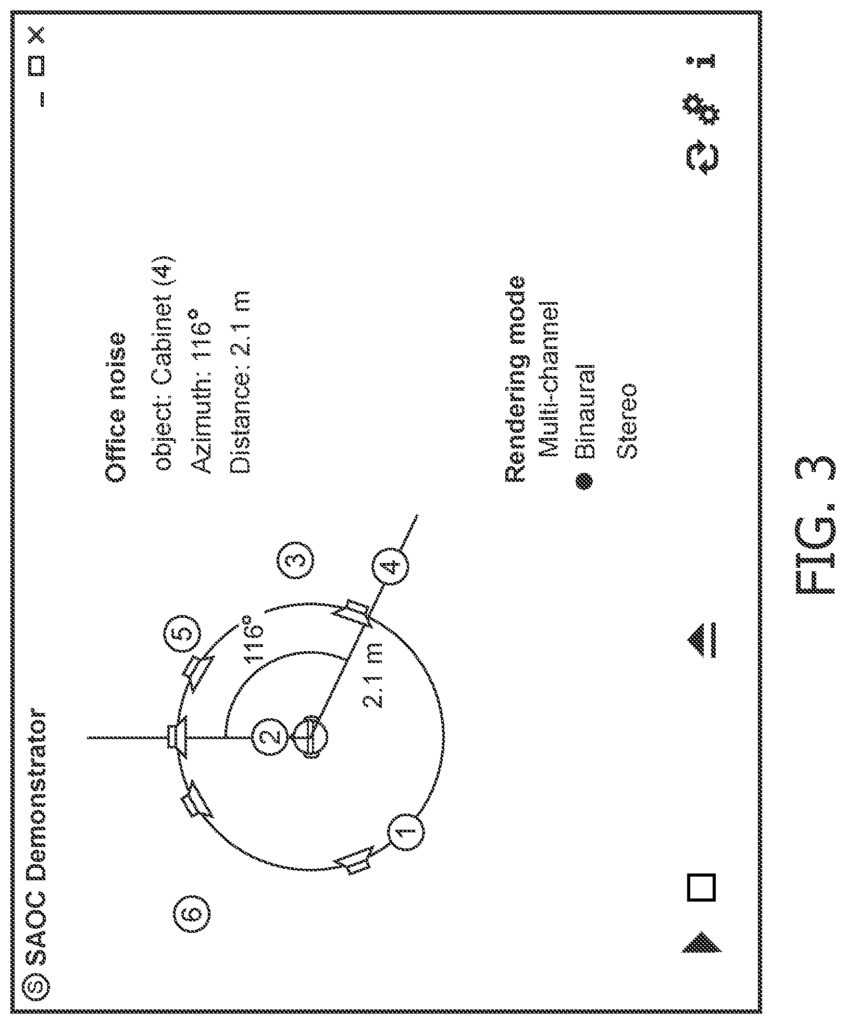

WO2013/006338A2 discloses a systems that includes a speaker layout (channel configuration), and an associated space description format. The WO2013/006338 A2 is a system that provides an adaptive audio format and system to support multiple rendering technologies. The metadata for the “mixer’s intention” is transmitted with audio streams. “Including the desired position of audio objects.