Invented by Wei Zhao, Yabing FENG, Yu Liao, Junbin LAI, Haixia CHAI, Xuanliang PAN, Lichun LIU, Tencent Technology Shenzhen Co Ltd
The Tencent Technology Shenzhen Co Ltd invention works as follows
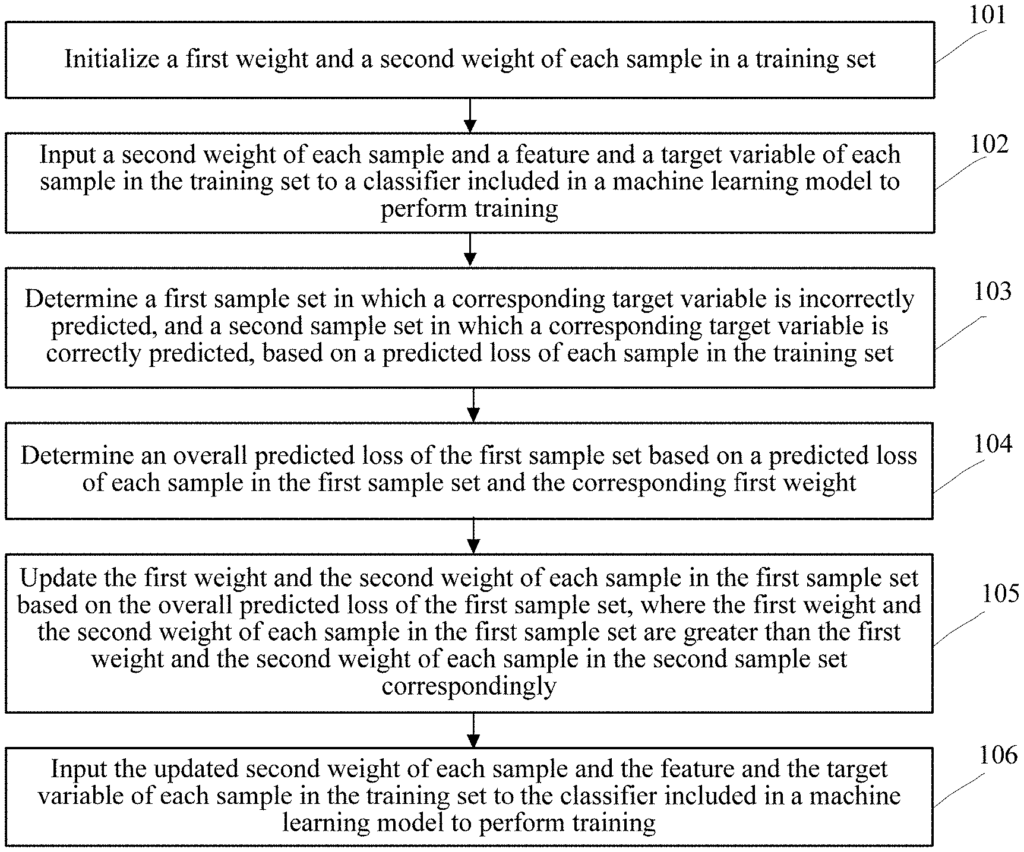
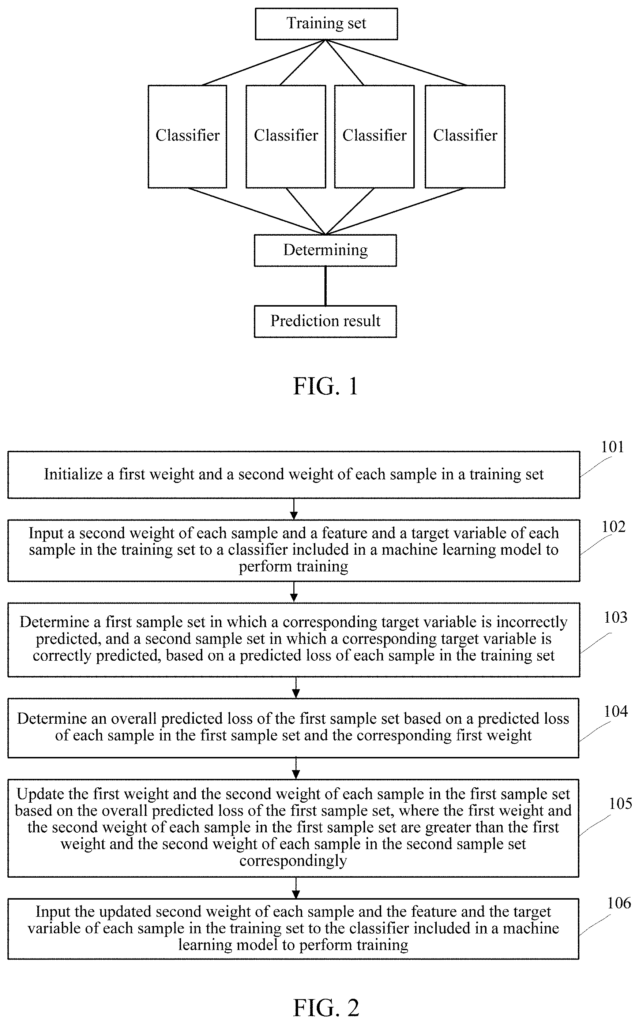
A machine-learning model training method” includes training a model based on the features of each sample within a training set, based on a first weight and a second weight. The method in one iteration includes determining the first set of samples in which the target variable was incorrectly predicted and the second set of samples in which the target variable was correctly predicted based upon a predicted lose of each sample. It also involves determining the overall predicted loss for the first set of sample based upon a predicted gain and the first weight of each of the sample in the set. The method includes updating a first weight and second weight for each sample of the first set, based on an overall predicted loss. Inputting the updated secondweight, the features and the target variables of each of the samples to the machine-learning model and initiating the next iteration.

Background for Machine Learning Model Training Method and Apparatus, Server, and Storage Medium
Machine Learning (ML) involves multiple fields and is continuously applied to real industry fields.
A supervised method is currently the most popular way to train a machine-learning model. A machine learning is model is trained on the features (for instance, title content in a mail, and credit reporting information of a person) of samples from a training set, and a classifier result (also called a target variable for example a credit score of an individual).
For example, using a machine-learning model, high-quality and low-quality customers can be distinguished in a credit report service. Spam mails and regular mails can be distinguished in a mailing system. And whether a client is a lost customer in business, it can also distinguished.
If training a machine-learning model involves training multiple classifiers in a supervised way, it is difficult to predict the classification results of some samples within a training set.
Embodiments” of the present disclosure are a machine-learning model training apparatus and method, a server and a storage medium that can improve machine-learning model prediction accuracy and training efficiency.
Technical solutions” of the embodiments in the present disclosure are implemented according to the following:
According to an aspect of the present disclosure, a computing device can execute a method for training a machine-learning model. The method involves training a machine-learning model using the features of each of the samples in a set of training samples based on a first weight and a second weight for each of them. The method determines a first set of samples that includes a sample for which the target variable has been incorrectly predicted and a subsequent set of samples with a target variable that is correctly predicted in one iteration. This is based on the predicted loss of every sample within the training set. The method includes calculating an overall predicted loss for the first set of samples based on a predicted loss and the corresponding weights of each sample. The method includes updating the weights of the samples in the first set, based on their predicted loss. The method includes introducing the second weight, features, and target variable for each sample of the training sets to the machine-learning model.
Accordingly, another aspect of the present disclosure is a machine-learning model training apparatus that includes: a memory, and one or multiple processors. The one or two processors are configured for training a machine-learning model using the features of each of the samples in a set of training data based on a first weight and a second weight initial to each sample. The one or more processors, in one iteration, are configured to determine, based upon a predicted loss for each sample, a first set of samples that contains a target variable that is incorrectly forecast, and a subsequent set of samples containing a target variable which is correctly predicted. The one or two processors can also determine the overall predicted loss for the first set of samples based on the predicted losses and the corresponding weights of each sample. One or more processors can also update a first weight and second weight for each sample of the first set of samples based on an overall predicted loss. One or more processors can also be configured to input to the machine-learning model the updated second weight for each sample of the training sets, as well as the features and target variables of each training sample.
Accordingly, another aspect of the present disclosure is a non-transitory medium that stores an executable programme. The executable program, when executed by a computer processor, can instruct the processor to: train a machine-learning model using the features of every sample in the training set. This is based on the initial first weight and initial second weight for each sample. The executable program instructs the processor, in one iteration, to determine a first set of samples that contains a sample for which the target variable has been incorrectly predicted and a set of samples for which the target variable has been correctly predicted. This is based on the predicted loss of every sample within the training set. The executable programme also causes the processor perform: determining a predicted overall loss of the training set based upon the predicted loss, and the corresponding first weight for each sample. The executable software also instructs the processor to update the first weight and second weight for each sample of the first set of samples based on the predicted overall loss. The executable program causes the processor to also perform: Inputting the updated secondweight of each training sample, the features for each training sample, and the target variables of each training sample, set to machine learning model and initiating the next iteration training the machine-learning model.
The following benefits are associated with the embodiments of this disclosure:
![]()

The machine learning model will be trained first when the samples are distributed according to the second weight. Once a sample is identified (the sample set), the machine-learning model will incorrectly predict it. A corresponding weight increase is then made to update the distribution of samples. The machine learning model will then pay more attention in future training to the sample which is incorrectly predicted. This improves the accuracy of the prediction.
The training efficiency of the model has improved.