Invented by Peter Kecskemethy, Tobias Rijken, Kheiron Medical Technologies Ltd
The Kheiron Medical Technologies Ltd invention works as follows
The present invention is concerned with the identification of areas of interest in medical imaging. The present invention is more specifically a method of identifying regions of interests in medical imaging based upon encoding or classification methods that have been trained using multiple types of medical image data.

Background for Multi-modal medical image processing
Computer-aided diagnostics (also known as CAD) are a set of tools that have been used by medical professionals for over 40 years to help interpret medical images created using techniques like magnetic resonance imaging, ultrasound imaging, and x-rays.
Medical imaging techniques produce large amounts of image data that are typically processed manually by medical professionals, such as radiologists, and then analysed or evaluated in relation to the diagnoses being made. “Typical diagnoses relate, for instance, to cancer detection and screening, as in mammography.
Computer-aided diagnostics can be used in conjunction with medical imaging techniques to process image data in order to highlight regions that are conspicuous in each image and may indicate a region of the image that is of interest to a number of medical professionals. For example, a radiologist.
Computer-aided diagnostics are almost never substituted for the opinions of medical professionals, as they have not reached a level that medical professionals find acceptable.
Further, certain medical image data such as x ray image data is not always optimal to reach a diagnosis due to the lack of clarity or resolution in the images obtained. As such, further data or tests need to be performed by the medical professional or other medical professionals to confirm any preliminary diagnosis on the basis of the immediately-available image data.
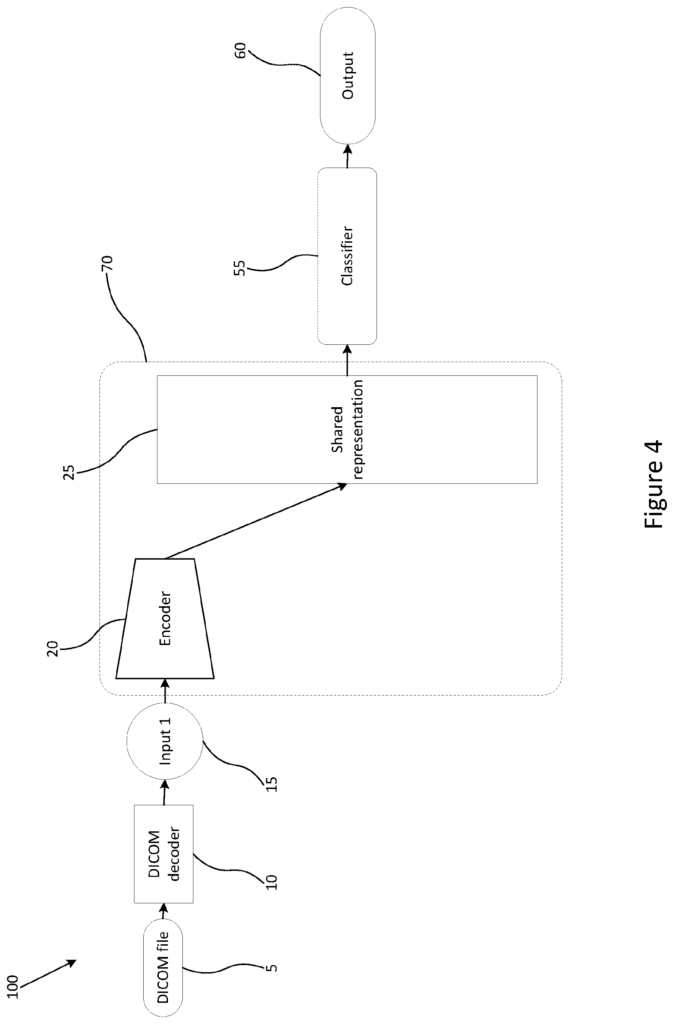
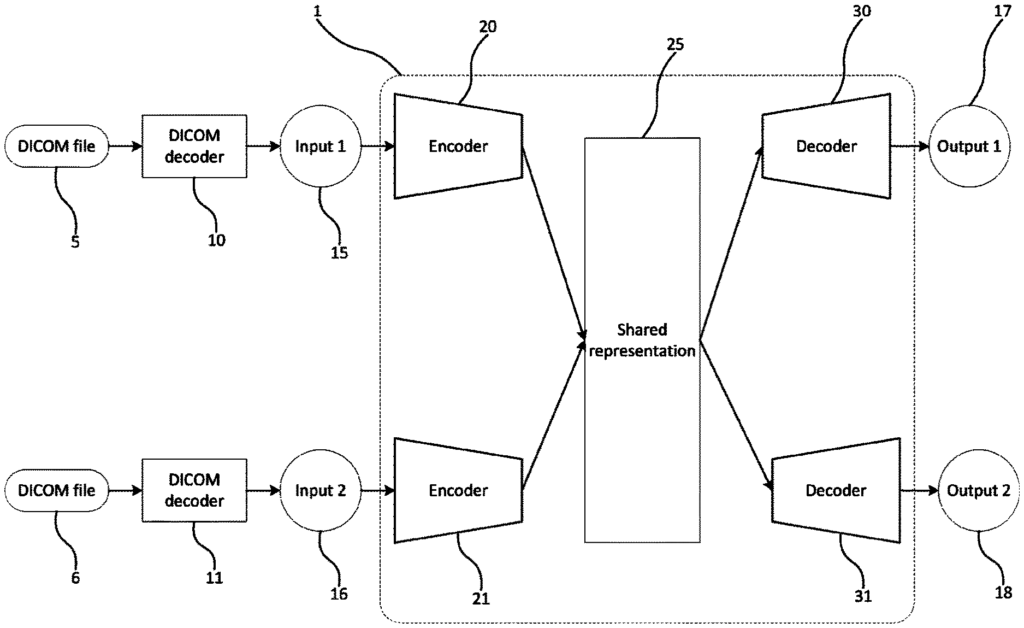
Aspects or embodiments seek to provide an algorithm for training an encoder, and/or a classifier, based on multimodal inputs. This allows the classification of regions of interest within medical images using a single source of input data.
The method comprises the following steps: receiving unlabelled data and encoding it using a trained encoder. Using a joint representation module, determining the joint representation. And generating labelled information for the input by using the joint presentation as input to a classifier.
The method can be used to automatically determine a joint representation using a number of pre-trained components. The method determines a joint image automatically using pre-trained components.
Optionally the encoder module, the joint representation and the classifier can be trained using input training data that include a variety of modalities. During test time (or run-time), a single input modality may be received by the method. To improve the accuracy in identifying regions that are of interest when analyzing medical or clinical data the pre-trained component is trained using multiple input modalities. These can be used to determine a joint representation even if only one input was received.
Optionally one or more input data modalities are provided.” In some cases, inputs can include more than one medical image.

The input data can be a combination of: a mammography, an X-ray, a computerised Tomography (CT) scan, a magnetic imaging (MRI) scan; histology; mammography data; a genetic sequence and/or ultrasound data.
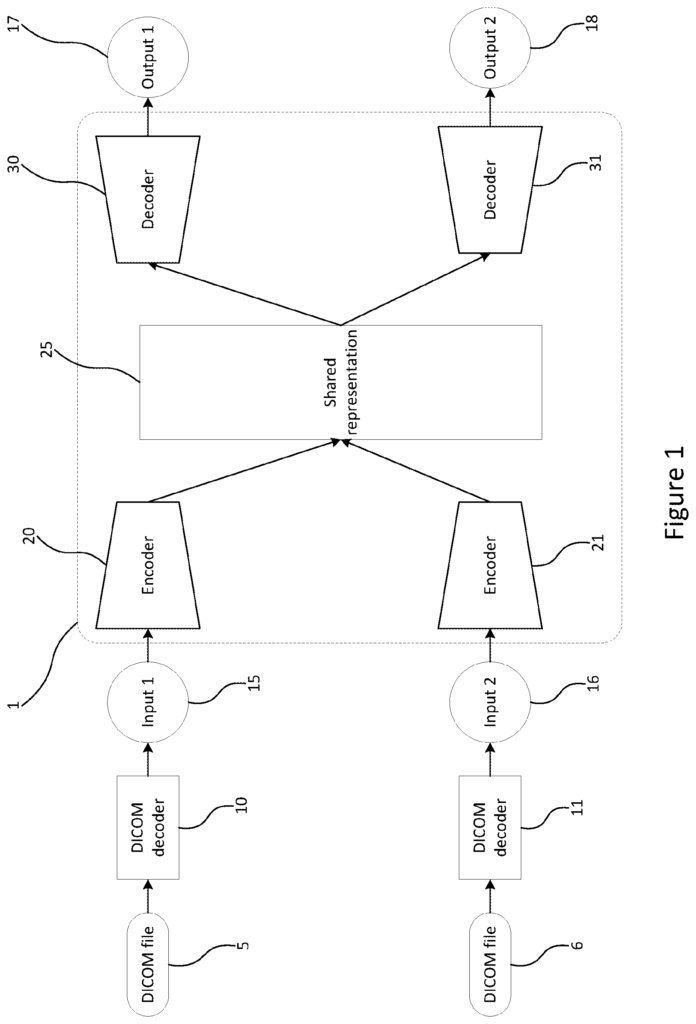
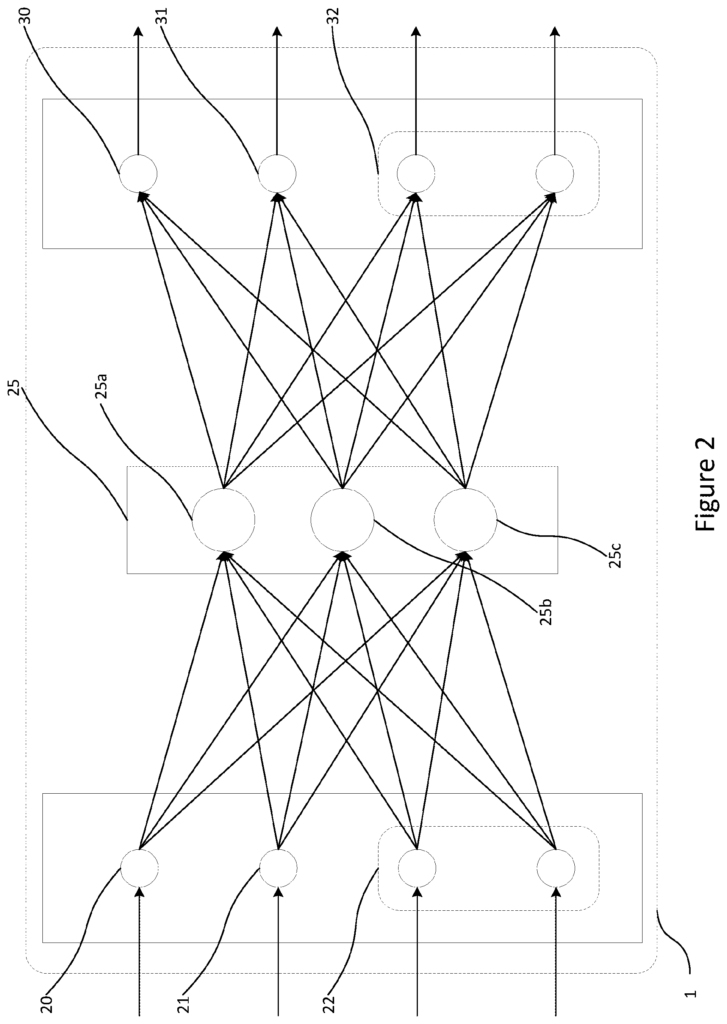
The joint representation module can be trained by using the outputs of the encoders.
The joint representation module can receive the encoded data in the form of three-dimensional tensors. The joint representation can be in the form a vector.
Optimally generating labelled input data also includes generating an indicator of one or multiple regions of interest within the unlabelled input data.
The number of modalities for unlabelled data can be one less than the number modalities used for input training data to train the encoder module, joint representation module, and classifier. This will ensure that the components are always provided with an additional data modality to aid input data.
The second aspect of the invention is a method for training a classifier to handle medical or clinical data. It involves: receiving unlabelled data in a prelabelled data set; encoding unlabelled data to create a joint representation, performing classification on the joint to produce labelled information; comparing the prelabelled data to the labelled information and generating comparison data; adjusting an adaptable algorithm to respond to the comparison; and finally repeating these steps until the comparison has reached a threshold that indicates no more adjustments are needed to
The encoders can be connected or paired to perform the step of encoding unlabeled input data.
By training a classifier with at least two data sources, a trained encoder pair and joint representation for classification of medical or clinical data can be created, for example, to identify areas of interest.
Optionally the input data may include data from multiple sources. Two different input data formats are possible. The unlabelled data can be in the form one or more images of medical conditions. The unlabelled data can be in the form a number of medical images. The plurality of images can be related. The input data can include one or more: a CT scan, an X-ray, a computerised Tomography (CT) scanner, an MRI scan and/or an ultrasonic scan. The medical image can be in the form a DICOM.
This data can be used to train a classifier and encoders. The training of a classifier, encoder and joint representation is more robust if the medical images are related. For example, if all of them relate to the same type of cancerous growth.
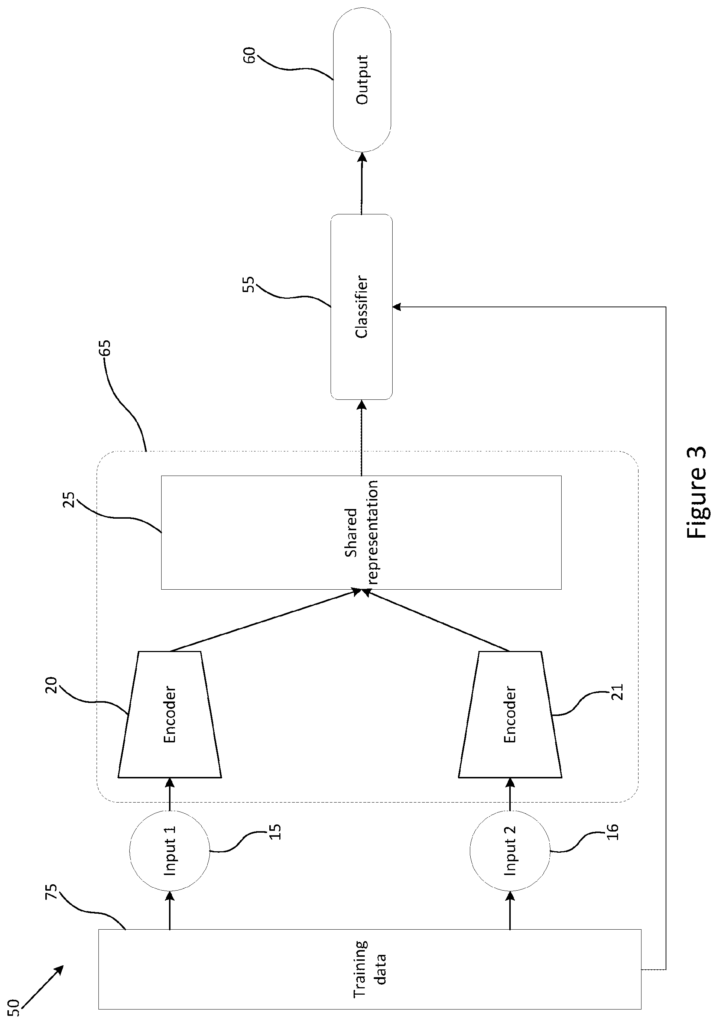

Optionally the step of encoding unlabelled input data for a plurality modalities in order to form a combined representation is performed separately by each modality.