Invented by Nikolai Smolyanskiy, Ryan Oldja, Ke Chen, Alexander Popov, Joachim Pehserl, Ibrahim Eden, Tilman Wekel, David Wehr, Ruchi Bhargava, David Nister, Nvidia Corp
The Nvidia Corp invention works as follows
A deep neural networks (DNNs) can be used to detect object from sensor data in a three-dimensional (3D) space. A multi-view perception DNN, for example, may consist of multiple DNNs or stages that are chained together to process sequentially different views of the 3-D environment. A DNN example may consist of a stage for class segmentation (e.g. perspective view) in the first view and a stage for class segmentation or regressing instance geometry (e.g. top-down) in the second view. The DNN outputs can be processed to produce 2D or 3D bounding box and class labels for detected object in the 3D space. The techniques described in this document may be used to classify and detect animate objects or parts of an environmental, and may then be passed to an autonomous vehicle’s drive stack for safe planning and control.

Background for Multi-view deep neural network for LiDAR perception
It is extremely difficult to design a system that can safely drive a car autonomously without supervision. A vehicle that is autonomous should be able to perform as the functional equivalent of a driver attentive to the environment. It must have the ability to react and identify moving and static objects in a complex setting. The ability to detect animate objects (e.g. cars, pedestrians etc.) is therefore critical for autonomous driving perception systems. It is important for autonomous driving systems to be able to detect other elements of the environment. Deep Neural Networks have been used to develop a number of different approaches to LiDAR and Camera perception. DNNs are used to perform panoptic segmentation in perspective view of camera images, as well as DNNs for top-down or “Bird?s Eye View”. BEV object detection using LiDAR point cloud. These conventional approaches, however, have some drawbacks.
For instance, conventional panoptic DNNs perform class and example segmentation of images when viewed in perspective (e.g. RBG images taken from front-facing camera or LiDAR scans). FIG. FIG. 1 shows an example of LiDAR scans in a perspective view with segmented classes derived from the panoptic segmentations. In FIG. In FIG. To simplify the figure, we have omitted segmented examples. 1 . FIG. FIG. In FIG. In FIG.
Panoptic segmentation is often successful for some classes such as pedestrians and cyclists. This is due to their characteristic geometry, i.e., the consistent structures. Panoptic segmentation can be difficult to evaluate features not visible from the viewpoint of the view that is being analyzed. While panoptic segments may be able detect a pedestrian on a frontal image, DNNs that perform panoptic segmentation often struggle to accurately predict the 3D bounding box or BEV 2-dimensional (2D), bounding boxes of detected objects. Panoptic segmentation algorithms that use perspective views often have difficulty detecting objects that contain distinguishing features not visible in the perspective view. “As a result, panoptic DNNs with a perspective view have limited accuracy when predicting object class, object instances and dimensions.
In predicting 2D bounding box for BEV, conventional DNNs detect objects from projections BEV (top down) of LiDAR points clouds. This includes cars, trucks and buses. FIG. FIG. 3 shows an example of object detection on a top down projection of a LiDAR cloud. DNNs performing BEV object recognition often have difficulty detecting pedestrians and bicycles because top-down images of these objects can look similar to other objects such as poles, trees trunks, or shrubs. Conventional DNNs, which perform BEV object recognition, are limited in their accuracy when predicting classification, dimension, and orientation. This problem can be solved by using 3D convolutions on a 3D volume. 3D convolutions can be computationally expensive, and they would have to process a large amount of empty space within the searched volume. This could lead to significant inefficiencies.
Embodiments” of the present disclosure are related to LiDAR perceptual systems for autonomous machines that use deep neural networks (DNNs). The systems and methods described in this document, for example, use object detection techniques to detect or identify instances of obstacles, such as cars, trucks, pedestrians cyclists etc. Other objects, such as environmental components for use by robots, autonomous vehicles, or other object types, can also be used. The system disclosed herein may be different from conventional systems such as the ones described above. It can include multiple DNNs or stages that are chained together to process sequentially different views of a 3D environment. A multi-view perception example DNN could include a stage that performs segmentation of classes in a perspective view and a stage that performs segmentation or regresses instances geometry in a top-down view.
For instance, the first step may extract classification information (e.g. confidence maps, segmentations, etc.). From a LiDAR image or RGB image. The extracted classification information may be transformed into a second environment view by, for instance, labeling 3D locations with the extracted data and then projecting those labeled 3D places to the second view. In some embodiments, sensor data can be used to obtain geometry data of objects (e.g. height data), by projecting LiDAR data into one or several height maps (in a top down view), and/or by using images of 3D space. The extracted classification and/or geometries data can be stacked, then fed into the DNN’s second stage, which will extract classification data, such as class confidence maps, and/or regress different types of information, including location, geometry and orientation, about detected objects. The DNN outputs can be processed to create 2D or 3D bounding box and class labels for detected object in the 3D environment.
The techniques described in this document can be used to detect and categorize animate objects or parts of an environmental environment. These detections and classes may then be given to an autonomous vehicle’s drive stack for safe planning and controlling of the autonomous car. By sequentially processing sensor data using a DNN for multi-view perception, present techniques can retain the benefits of processing each view separately while minimizing potential drawbacks. The approaches described herein can detect motorcycles, bicycles, pedestrians, and other vulnerable road user (VRU) or objects with a high rate of recall. The embodiments may also provide an effective and simple way to detect, classify, and regress the dimensions and orientations of objects where conventional methods fail.
Systems and Methods are disclosed in relation to multi-view LiDAR perceptual for autonomous machines using Deep Neural Networks (DNNs). The systems and methods described in this document, for example, use object detection techniques to detect or identify instances of obstacles, such as cars, trucks pedestrians, cyclists etc. Other objects, such as environmental components for use by robots, autonomous vehicles, or other object types, are also included.
Although this disclosure can be described in relation to a vehicle 1600, (also referred to as’vehicle? “Although the present disclosure may be described with respect to an example autonomous vehicle 1600 (alternatively referred to herein as?vehicle? An example is given in the following paragraphs with reference to FIGS. This is not meant to be restrictive. The systems and methods described in this document can be used, for example, by non-autonomous cars, semi-autonomous cars (e.g. one or more advanced driving assistance systems (ADAS), robots and/or warehouse vehicles. The present disclosure is not limited to the autonomous driving. The systems and methods described in this document may, for example, be used for robotics (e.g. path planning of a robot), aerial vehicles (e.g. path planning of a drone or another aerial vehicle), or boating systems.
At the highest level, a DNN can be used to detect object from LiDAR and/or sensor data that captures an environment in three dimensions (3D). In some embodiments the DNN can include several constituent DNNs that are chained together to process the different views of the three-dimensional environment. A multi-view perception example DNN could include a stage that performs segmentation of classes in the first view (e.g. perspective view), and a stage that performs segmentation of classes and/or regresses instances geometry in the second view (e.g. top-down).


In some embodiments, input to the DNN can be derived from LiDAR (e.g. a LiDAR image range, a projection a LiDAR cloud point). The input may include data from other sensors, such as images taken by any number cameras, and/or class confidence data, such as confidence map for any number classes. The confidence maps or a composite segmentation can be used to segment (and represent) the first view of a 3D space (e.g. perspective view). The confidence maps or composite segmentation can be projected in a second (e.g. top-down) view to produce transformed classification data that will then be processed by a DNN stage. The extracted classification data can be used to label 3D locations identified by LiDAR images, for example. These labeled 3D positions (e.g. the LiDAR image range) may then be re-projected into a second view.
In some embodiments, the geometry data of objects in 3D space can be obtained by LiDAR (e.g. by projecting the LiDAR point clouds into one or several height maps from a top down view) and/or by images of the 3D environment (e.g. by unprojecting the image into world-space and projecting it into a bottom-up view). The transformed classification and geometry data can be stacked, then fed into the second stage of DNN. This may extract classification (e.g. class confidence data, such as confidence map for any number classes), and/or regress different types of information such as location and orientation. The DNN outputs can be processed to create 2D or 3D bounding box and class labels for detected object in a 3D environment.
In general, the DNN for multi-view perception may accept some representation of LiDAR and/or sensor data from a 3D world as input. Raw LiDAR detections of an environment surrounding an ego-object, such as a moving car, may be pre-processed to a format the DNN can understand. In particular, LiDAR data (e.g., raw LiDAR detections from an ordered or unordered LiDAR point cloud) may be accumulated, transformed to a single coordinate system (e.g., centered around the ego-actor), ego-motion-compensated (e.g., to a latest known position of the ego-actor), and/or projected to form a LiDAR range image.
In some cases, the formation of a LiDAR image range scan may lead to some sensor data loss. It may be possible to binned multiple reflections in a scene into a single range scan pixel, for example, when the ego object is moving and accumulating sensor data over time, or when using different sensors at different locations on the ego object (i.e. capturing sensor information from different views of a scene) and/or collapsing the sensor data into a pixel with a low resolution to capture adjacent sensor data. When reflections are binned in a single pixel, in some embodiments the closest reflection may be displayed in the range scan image. The other reflections can be removed. The resolution of the image can be chosen to minimize the loss in sensor data or accuracy. The height (or the vertical resolution) of a range image can be adjusted to match the number of horizontal scanlines of the sensor that captures the sensor data. (For example, a row of pixels per scanline of corresponding LiDAR sensors). The horizontal resolution (or width) of the range images can be determined by the horizontal resolution of sensor that captures the sensor data. Horizontal resolution is often a design decision. A lower resolution can have fewer collisions but be easier to process.
In certain embodiments, the LiDAR image range may be fed into a multi-view perception DNN. The LiDAR image range and/or sensor data can be stacked in corresponding channels and fed to the multi-view perception dnn. The DNN can include several stages that are chained together to process data from different views sequentially in order to predict object instances and/or classification data. These outputs can be converted into 2D or 3D bounding box and class labels. In one example application, DNN can be used to predict bounding boxes (2D bounding boxes in top-down views, 3D bounding boxes) for every detected object on the road, sidewalk or other static environment parts, as well as a 2D Mask delineating a driving space, sidewalks or buildings, poles or trees. In some embodiments 2D bounding box in top-down views may be adapted to 3D bounding box by determining the height of the boxes from predicted object instance data.
In embodiments where the multi-view DNN has multiple stages, each stage can be trained separately or together. In some embodiments the stages can be trained by implementing a transform from the output of a first stage (the view) to an input to a second stage (the view), using a differenciable operation (e.g. a diffenciable re-projection). Annotating the data of a number of sensors within a sensor set-up can be used to obtain training data. In some embodiments, since data can be obtained at different frequencies from different sensors, a specific sensor (e.g. a LiDAR) may be used to serve as a “reference sensor”. A set of sensor information can be curated for each frame from the sensor setup (e.g. each frame from LiDAR sensor) by identifying the frame closest in time from each other sensor. The set of sensor information (e.g. a frame with LiDAR data and an image closest to the timestamp of T taken by each of the plurality of cameras within the sensor setup), may be called a “set of curated data” at the timestamp of T. Data from each sensor can be labeled separately from data from other sensors. In some embodiments object detection and tracking can be used to track annotated objects’ movement from frame to frame in time. In this way, object tracking can be done using annotations (e.g. persistent identifiers). In some embodiments object tracks or detections from sensor information from one sensor can be linked with corresponding object track and/or detectors for the same objects from sensor information from another sensor. Annotations or links between different types sensor data of the same object can be generated automatically and/or manually, and used to generate data for training the DNN multi-view perception.
The techniques described in this document can be used to detect and categorize animate objects or parts of an environmental environment. These detections and classes may then be given to an autonomous vehicle’s drive stack for safe planning and controlling of the autonomous car. By sequentially processing sensor data in multiple views with a DNN for multi-view perception, these techniques can retain the benefits of processing each view separately while mitigating any potential disadvantages. The approaches described herein can detect motorcycles, bicycles, pedestrians, and other vulnerable road user (VRU) object with a high rate of recall. The embodiments may also provide an effective and simple way to detect, classify, and regress the dimensions and orientations of objects where conventional methods fail.
Example Object Detection System
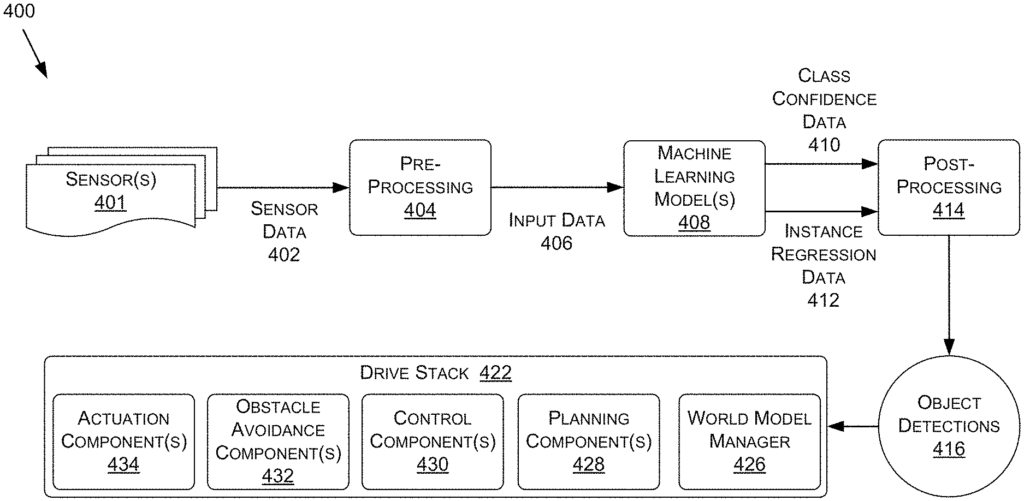
Referring to FIG. 4 , FIG. According to some embodiments, FIG. 4 shows a data flow chart illustrating a process example for an object-detection system. This and other arrangements are only examples. Other arrangements and components (e.g. machines, interfaces functions, orders groupings etc.) may also be used. Other elements and arrangements may be substituted or added to those shown. Some elements can be completely omitted. Many of the elements described in this document are functional entities which can be implemented in a variety of ways, including as discrete components or distributed components, or in combination with other components in any suitable location and combination. The various functions that are described as being performed by entities can be performed by hardware, software, or firmware. “For example, a processor may carry out various functions by executing instructions in memory.
The process 400 can include machine learning models 408 that are configured to detect objects such as instances of animated objects or parts of an environment based on sensor information 402 from a three-dimensional (3D). The sensor data may be preprocessed into input data 406 in a format the machine-learning model(s), 408 can understand. This input data 406 may then be fed to the machine-learning model(s), 408 for detection of objects 416 within the 3D environment. In some embodiments the machine learning model 408 can include multiple machine learning stages or models chained together to process 3D views sequentially. The machine learning models 408 can predict a representation for class confidence of detected objects, such as class confidence data 410, and/or an object instance data representation for detected object, such as instance regression data 412, which may then be post-processed into object detections 416, including bounding boxes or closed polylines to identify the location, size, and/or direction of detected objects. The object detections may include obstacles surrounding an autonomous vehicle, environmental static parts, or other objects. They may be used to control components of the vehicle, such as controllers 1636, ADAS systems 1638, software stacks 422, and/or any other components. 16A-16D), to assist the autonomous vehicle with one or more operations. “Within an environment.


Generally, object recognition can be done using sensor data 402 of any type and number of sensors. This includes, but is not limited to, LiDAR, RADAR, cameras and/or any other types of sensors such as those described in the following paragraphs with regard to the autonomous vehicle of FIGS. 16A-16D. The sensors 401 can include, for example, one or more sensors 401 of a ego-object (such as LiDAR sensor 1664) of the autonomous vehicle of FIGS. 16A-16D, and the sensors 401 can be used to create sensor data 402 that represents objects in the environment surrounding the ego-object.