Invented by Vijay H. Agrawal, Commvault Systems Inc
The Commvault Systems Inc invention works as follows
Perform data management operations in a computer networking.” Data management operations are recorded in log entries for an application running on a source computer. Consistency points are used to identify a specific time when an application was in a good or recoverable state. The destination system can be configured to use a copy log entries and consistency point entry to replicate the data in the replication volume. This replicated data is a copy the application data from the source system. The consistency point entries determine that the replicated application data represents the known good application state. When this is the case, the destination systems may perform a copying operation (e.g. snapshot or backup) in order to copy and logically link the copied data to the time (e.g. time stamp) of the source system when the application was at the known good status.

Background for Network redirector system and methods for performing Data Replication
1. “1.
The present disclosure is related to copying and/or managing data in a computer system, and in particular to systems and methods of performing data replication within a storage management software.
2. “2.
Computers have become a vital part of many businesses. Many banks, insurance firms, brokerage firms and financial service providers rely on computer network to store, manipulate and display constantly changing information. The success or failure in a transaction can often be determined by the accuracy and availability of current information. Businesses worldwide are aware of the value their data has in terms of commercial transactions and they seek cost-effective, reliable ways to secure the information on their computer network.
Many approaches to protect data involve creating copies of the data. This can be done by backing up or replicating data onto one or more storage media. In general, certain factors must be considered when creating a duplicate of this data. A copy of data must not contain corrupted or improperly terminated data files. A copy of data must be up-to-date to prevent data staleness. This is done by not allowing too much time to pass between copies. In certain applications such as networks that hold financial transactions, copies older than a week may not be useful and more frequent copying is needed.
In an effort to meet such storage needs, certain systems check the date and time of each file. The system will send a copy to the storage system if data has been added to the file in the time since it last checked its status. These systems are not suitable for large files. Data shadowing may not be feasible if, for example, it is assumed that the large database could be copied. It takes a lot of time and storage space to make multiple copies of large databases.
Another method that has been tried to overcome these limitations is the process of capturing and saving a sequence of data. Many systems, for example, incorporate disk duplexing or mirroring. Disk mirroring and duplexing are methods of sending changes from a primary storage system to backup systems or secondary storage systems. When a datablock is written into the primary mass-storage system, it is also written to another secondary mass-storage system. Two mass storage systems can be kept in sync by copying every write operation onto a secondary mass storage system. This ensures that both mass storage systems are almost identical at the same time. Mirroring is expensive because it requires an enormous amount of space to store and uses a lot of processing power.
Furthermore each of the processes described above for copying or back up data can have an impact on the primary or source system.” The processing resources of the primary system can be used to copy data to the destination system instead of being used to process requests.
In light of the above, it is necessary to improve systems and methods of copying or replicating data on computing systems. There is a particular need for systems and techniques that reduce the impact on a primary system (e.g. processing load) when performing data management or storage operations, such as application-specific data.
In certain embodiments, methods and systems are disclosed that perform substantially continuous replication in a networked computer environment. In certain embodiments systems and methods can perform additional data management operations to the replicated data. This is done in order not to burden the source system. One or more storage operations can be performed, for example, on replicated data which represents a recoverable or “known good” state. “An application on the source system may run in a known good state.

In certain embodiments known good replication copies can be viewed like copies of production volume. This feature allows the management component of the computing system directly access, copy or restore production data copies as if they were the original production data.
In certain embodiments the copies of production data that are replicated include time information, such as a time stamp. This indicates the time on the client’s system when the production data were modified or when the application was in an accepted state. These time stamps can then be associated with replication data or copies of replicated data to allow for synchronization between time references.
Accordingly, certain embodiments may recognize points in application data that represent an application known to be in a good state. The replication system uses this information to intelligently copy sections of application data which represent a recoverable condition, rather than copying certain blocks based on criteria unrelated to the application’s recoverability or hardware capacity. In certain embodiments, the systems and methods described herein provide the benefit of being able to replicate data based on application-specific criteria rather than simply copying physical blocks based on file type, buffer size or other uncoordinated data groups.
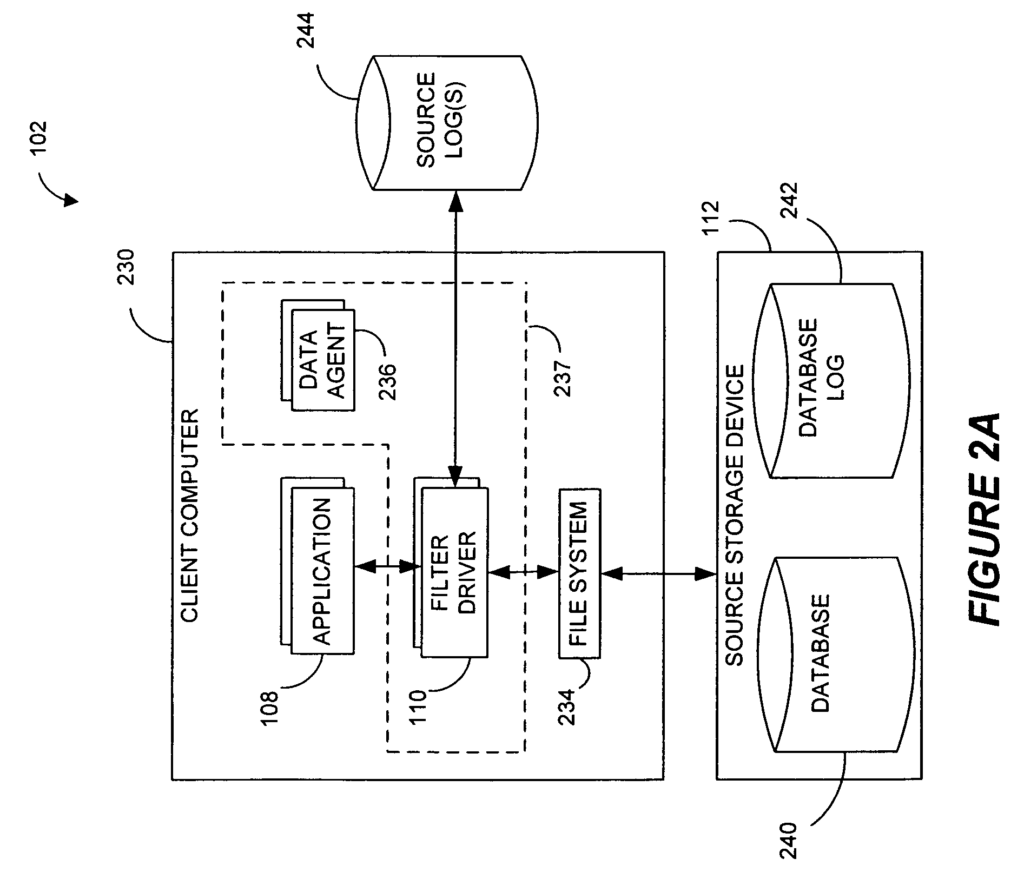
In certain embodiments, data management operations are performed in a computer networking by a disclosed method. The method includes monitoring: operations that are associated with an app which is operative to write to a storage device, inserting a marker in a log file comprising time data identifying a known state of application; copying data to second storage device at a later time based on the operations.
In certain embodiments, this method further comprises performing a copy or backup operation on the snapshot. The resulting copy is then associated with the time information that identifies the time of the good known state of the application.
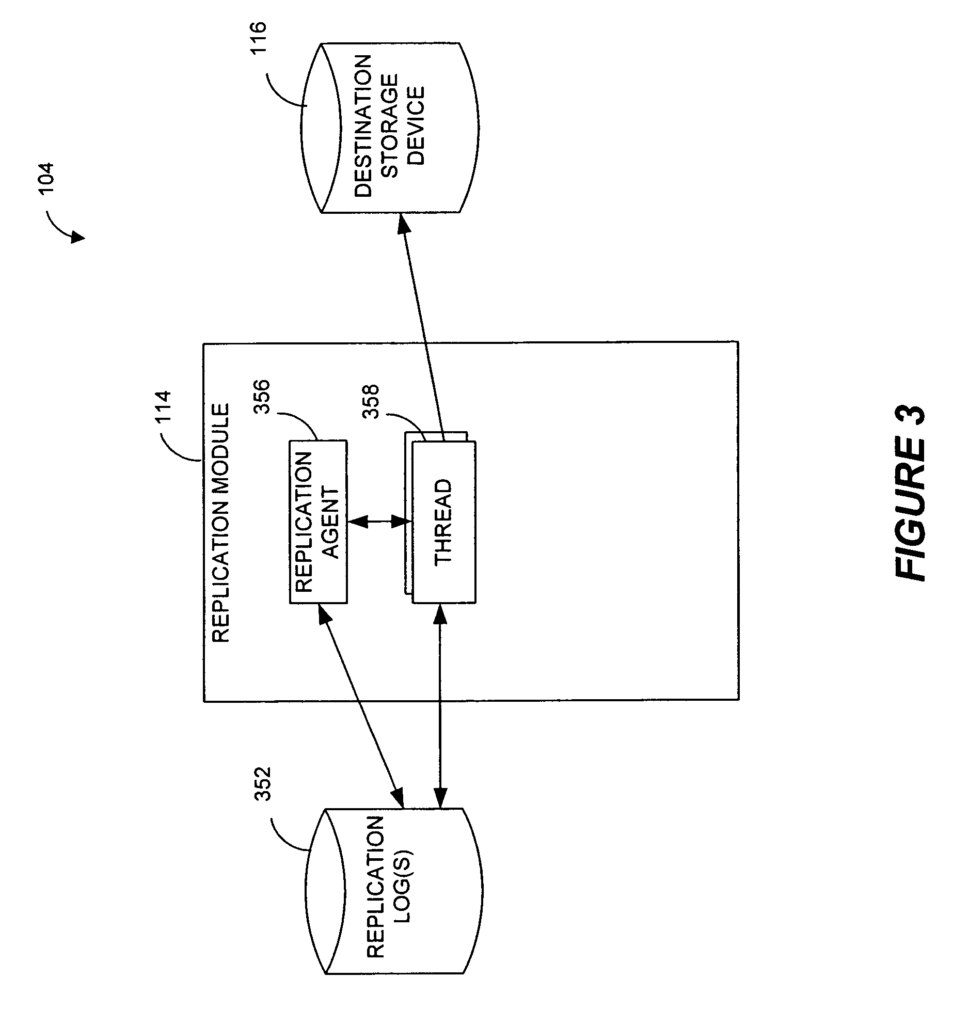
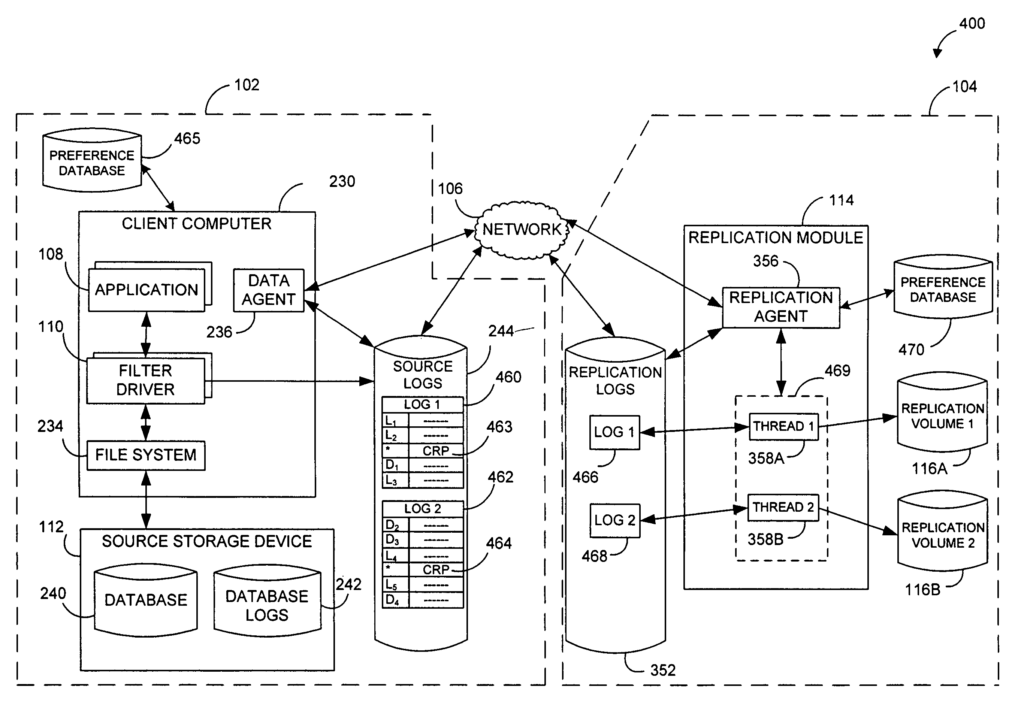
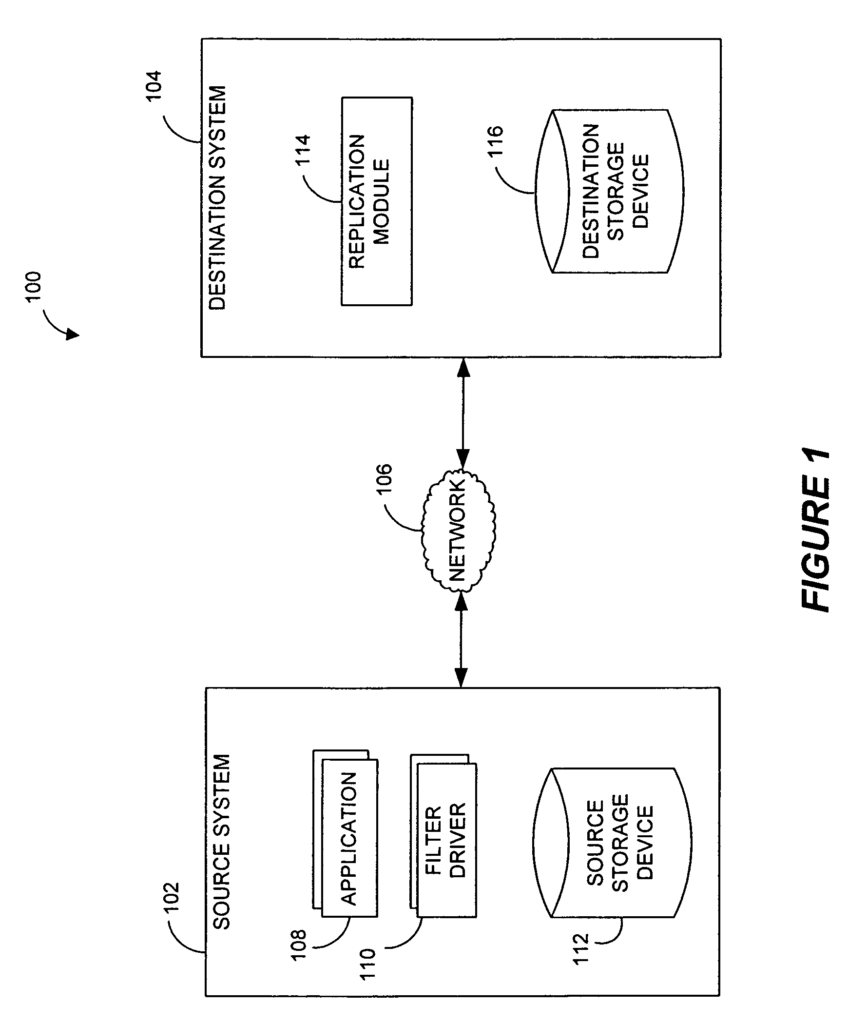
In certain embodiments, there is disclosed a system for performing data management in a networked computer environment. The system consists of at least one application that is configured to run on a computer source and a storage device connected to the computer source to receive data writes from the application. The system also includes a second device and at minimum one module that monitors the data writes operations and generates log entries on the basis of those data writes operations. At least one log entry has a date stamp indicative of the time when the computer application was in a known-good state. The system includes a replication unit coupled to the 2nd storage device. This module is configured to perform the following: process the log entries to replicate the data in a first place on the 2nd storage device. Perform a storage operation to copy the replicated data from the 1st location to a different location than the first. Logically associate the copied data on the 2nd location with the time stamped indication of the known state of at least one application.
In certain embodiments, it is disclosed a method for performing data management in a network. The method involves monitoring data operations that are associated with an app, and the data operations write data to a storage device. A first log file is then populated with entries indicating the data operations. The method further comprises inserting a marker in the first log that indicates a known state of an application. The marker includes a time information that identifies a specific time when the known state was achieved.
In certain embodiments, it is possible to copy data over a network. The system includes: means for monitoring the data operations generated by one computer application which are operative to store data on a first storage medium; means to store data entries indicative the data operations; a means to insert in the storing a marker that indicates a known-good state of computer application. The marker contains a time stamp associated to the source system of the known-good state of computer application.
In certain embodiments, it is disclosed a method for monitoring a data replication application in a network. The method consists of: detecting data transfers from a computer program to a filesystem on a source PC, where the data transfers are operative to write to a storage device, populating a log with entries indicative of these data transfers, detecting a “known good” state for the computer app, quiescing the data transfer to the filesystem at this known good status, and inserting a time stamp in the log identifying the time of that known good condition.
In certain other embodiments, the method described above is paused at regular intervals. The method can, for example, include receiving input from the user to select the periodic periods or the intervals can be automatically selected. The frequency of periodic intervals can be determined at least in part by: the type of data that is associated with the application, the average failure rate of one or more computers in the network, the load on at least some of those computers, the availability of one or more of them, and combinations thereof.
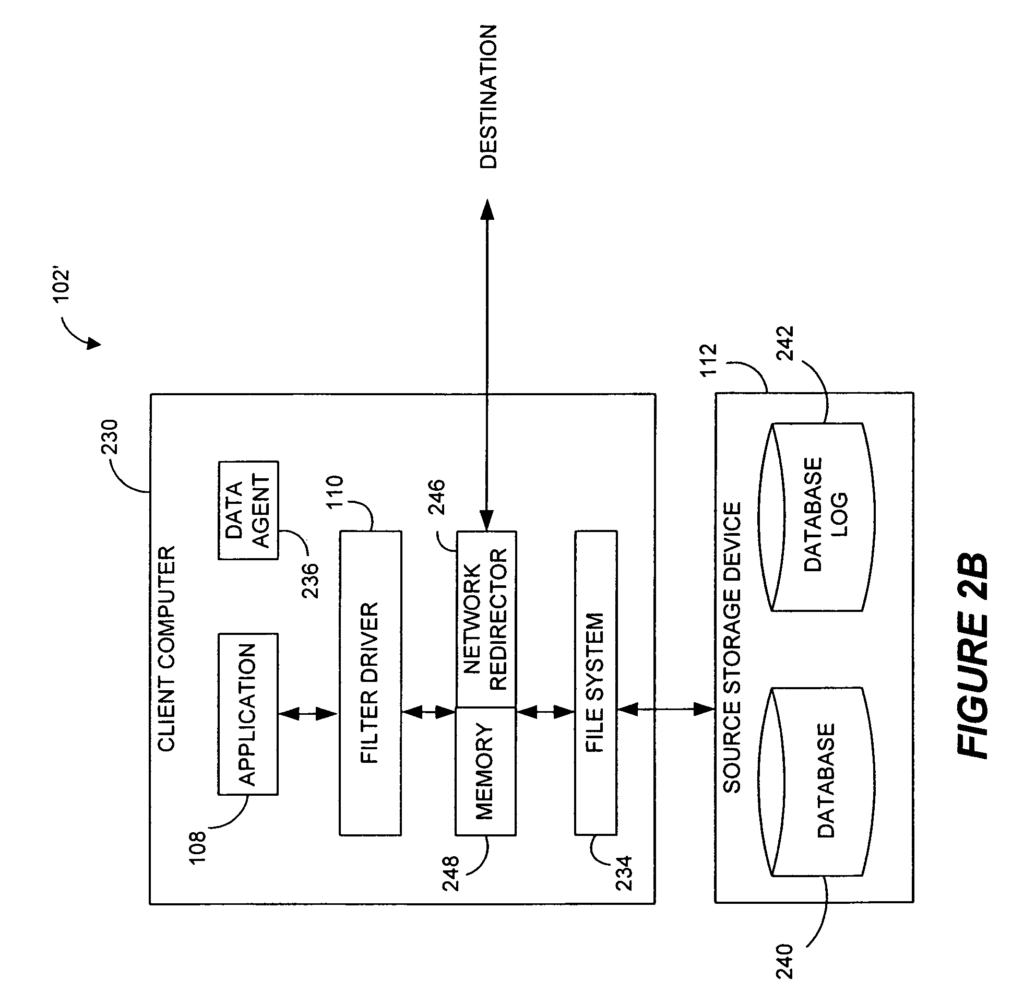

In certain embodiments, it is disclosed a system for generating data to be used in a replication environment. The system includes a monitor that monitors data write operation of a computer program and generates first log entries. The monitor is further configured to quell or buffer any additional data writes operations when the application is in a known-good state and generates a second log with a time stamp indicating the time at which the application was in the known-good state. The system further comprises at least one logging file configured to store first and second log entry.