Invented by Nidhi Hegde, Gaurav Sharma, Facundo SAPIENZA, Royal Bank of Canada
The Royal Bank of Canada invention works as follows
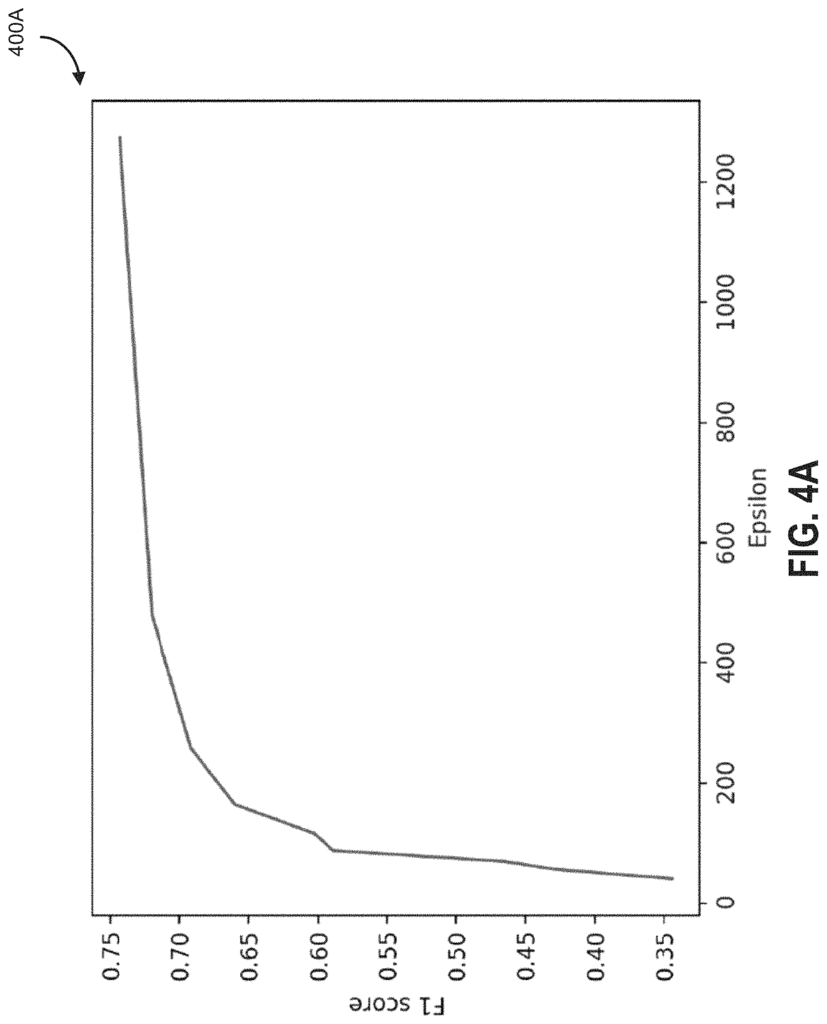
A computer system and method is presented for machine inductive-learning on a graph. In the inductive-learning computational approach, an iterative sampling approach is used to sample a set seed nodes. Then their k degree (hop) neighbors are considered for aggregation. This approach can be adapted to improve privacy by adding noise in the forward pass and backward pass steps of an inductive-learning computational approach. It is therefore more difficult for malicious users to try to reverse engineer edge weight information. The applicants were able experimentally to validate that acceptable privacy cost could be achieved with the various embodiments described in this document.

Background for System and Method for Machine Learning Architecture with Privacy-Preserving Node Embeddings
The invention describes various embodiments of technical mechanisms to improve privacy by using graph networks for data structures when training graph convolutional neural networks.
A graph network is an information structure whose data can be represented by proxy representations. These values are stored in data values. The graph data structure contains, in different types of data representations, a collection of “nodes”. The edges connect the objects. Nodes can also be called’vertexes’ in other nomenclature. The graph can be represented as a separate data object. Each node may be represented from a computational point of view as a data object, and a local data array or global data array can be stored to represent the relationship between each node and other nodes. These relationships can also be represented using data values that indicate ‘edge weights. The edge weights can represent different types of relationships and the strength of those relationships.
A graph data structure is a useful way to represent information when there are relationships between objects that can themselves have characteristics. Interrelationships are represented by ‘edges’. Objects may be represented using logical nodes. A graph network example is a network of social relationships where individuals can be represented as nodes with characteristics like age, height and name. Edges are interrelationships such as “father”, “son”, ‘last messaged five weeks ago’, or’sent $20. There are many ways to represent graph network data structures. These include linked lists, arrays and more. “For example, the interrelationships of individuals can be stored as one or more adjacency matrixes.
Graphs can be used to represent data with complex interrelationships. They are also an effective way to represent evolving networks, where nodes or information are added over time. This is especially useful when the majority of information on the graph remains relatively static and only a small number of nodes are updated or added during a specific period of time. The graph in the social network is updated when new users join, new connections form, or new information is updated. However, the overall structure of the graph remains stable.
In this simplified example, graph networks can be used as a representation of a social network. As new users create their accounts, these can be tracked by new nodes. In this simplified case, some nodes have labels. The nodes could be labeled with different characteristics (e.g. a primary movie that is of interest to each user) or data values. Some users may not be labelled as the information hasn’t been recorded. Edge weights are assigned to nodes based on their relationship with each other. This can be determined by whether they’re friends or not. The value of this friendship is determined through the interactions that occur on the social network.
In scenarios that are of interest to the present embodiments, these edge weights could contain sensitive information. They therefore require a certain level of privacy. This means that the edgeweights should not easily be observable by others.
For instance, it’s desirable that a user cannot accurately retrace all the friends or strength of relationship of another user. This is not the case with conventional graph convolutional networks. In non-private methods, malicious users can reverse engineer edgeweights by taking many observations of the outputs of a graph convolutional net. The number of observations grows, and it is possible to use “brute force” methods. “Using brute force” to determine the edge weights becomes possible as the number of observations increases.
In an example, where a social network is used to generate “friend recommendations”, a technical vulnerability can arise from the generation of inductive-learning based predictions. A malicious user could record thousands of recommendations and then use this information to reconstruct a part or the entire social network graph. This is because the observations were used to recreate rich latent data about correlation or dependency between the nodes.
The lack of privacy in some machine learning methods leads to a lower adoption rate, as these approaches shouldn’t be used with sensitive data.
Privacy breaches are a risk and an important technical issue to be dealt with as the edge weight information could include highly sensitive information (e.g., voting patterns; financial information such as whether a loan exists, and how much; personal/professional relationships). One example of a highly sensitive situation is when graph networks are used for pandemic contacts tracing and individuals provide information voluntarily, but do not want the contact tracing data to be attributed. Many real-world graphs are sensitive. Online social networks are a practical example where this could have serious consequences. A malicious adversary could create fake accounts on such social networks, and using the labels provided by this framework, they can infer sensitive edges between users. This limits the application of powerful GCN model with no privacy guarantee in these settings.

The techniques described in this paper are aimed at enhancing differential privacy for edges of graphs when graph convolutional network is used to predict the labels of nodes that were previously unknown. There are scalable methods that guarantee differential privacy when learning node embeddings or predicting labels for large graphs. “If privacy is improved, graph networks’ potential uses for sensitive information can be increased.
The embodiments address the technical question of whether machine learning techniques can incorporate improved privacy and still maintain a level of performance acceptable relative to non-private methods. While there may be some loss of technical performance with certain technical approaches for inductive-learning described herein, enhanced privacy remains practicable.
Inductive learning can be used to learn a node-embedding function from graph data. This framework, for instance, could be used to classify nodes that were previously unknown. Differential privacy is now the de facto standard in privacy-preserving methods to ensure strong mathematical privacy. In the course of experiments, it was discovered that standard techniques to ensure differential privacy in the GCN setting are not scalable for large graphs.
In particular techniques are investigated and proposed to ensure differential privacy in a graph when GCNs are being used to predict labels of previously unknown nodes.
The contributions relate to: (1) a proposed approach to sampling for GCNs, which is scalable for large graphs while preserving privacy; and (2) an approach to perturbation that provides edge differential privacy in the GCN framework according to certain embodiments. In some embodiments these contributions can be viewed separately or together. These approaches are implemented in computer hardware (electronics circuitry) as well as software. They are used to process graph data networks and implement scalable methods of promoting differential privacy when learning node embeddings or predicting labels for large graphs. Computer systems, methods and computer program products can all be used to implement the variations.
The system receives a graph data structure to be processed, which represents a graph network.
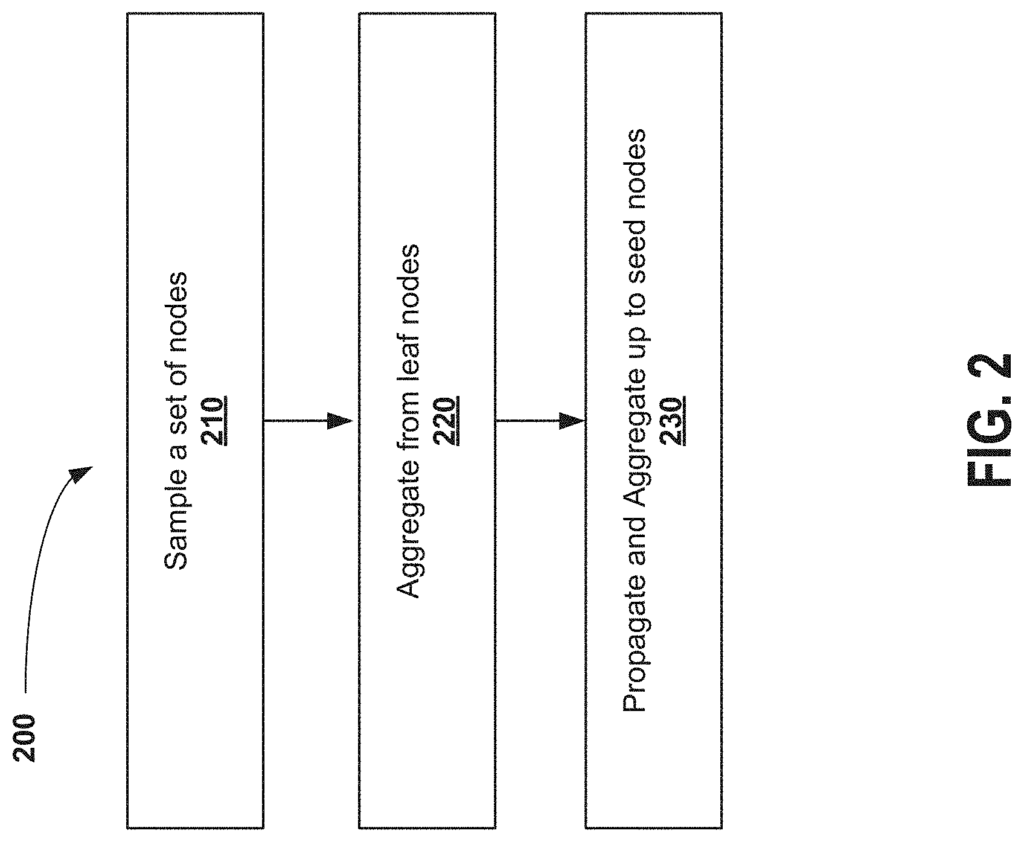
The proposed sampling method includes selecting, for each of the training epochs in a series, a seed set that will be used to compute a number of embeddings. The embeddings are determined by adding the embeddings from neighboring nodes (e.g. a sum) and applying dimensionality reduction (e.g. multiplying the adjacency matrix by the feature matrix). The number of nodes that are incorporated into the model can be multiple levels (?hops ?).
The number of hops is from zero to a multitude. In some embodiments, the use of two hops is used because two hops yields good results experimentally. At two hops, for example, the friend of a Friend of a Seed Node is used to determine the embedding.
Accordingly the sampling method includes a ‘forward pass’ for each epoch. Node sets can be created based on the hops of the first, second, etc., and used to obtain embeddings. Then, a “backward pass” is performed. Sage is used to calculate private gradients for the loss in relation to the embeddings, and weights.
The sampling approach iterates over T epochs, where each node is used to update gradients in a loss function. This results in an iterative updating of the weight matrix. The graph convolutional networks track the loss function, and weights are updated in each epoch in order to optimize loss. It is the goal to refine and learn, iteratively, the weight matrix. This can be initially set as, for instance, a uniform weight or random weights. The weight matrix can be used to reduce dimensionality against embeddings in various steps so that a prediction relating to the desired output can be generated. Weight matrix can be referred to as “feature matrix”.

The embedding weight matrix can be used to predict a classification correctly or incorrectly. A reward will be given when this embedding weight matrix does so. The weight matrix can be initialized in different ways and with different hyperparameters. This may affect the convergence rate of training to achieve an acceptable accuracy level for either the test or training data before deployment.