Invented by Bin Gao, Tie-Yan Liu, Microsoft Technology Licensing LLC
To address this limitation, researchers have developed methods that incorporate morphological information into the word embedding process. These methods use morphological analysis to generate word forms and then use these forms to create word embeddings. This approach has shown promising results in improving the performance of NLP tasks such as sentiment analysis, named entity recognition, and machine translation.
The market for learning word embedding by using morphological information is growing rapidly. This growth is driven by the increasing demand for NLP applications in various industries, including healthcare, finance, and e-commerce. These industries are using NLP to extract insights from large amounts of text data, improve customer experience, and automate processes.
The demand for NLP applications has led to the development of various tools and platforms that incorporate word embedding with morphological information. These tools include libraries such as spaCy, Gensim, and TensorFlow, which provide pre-trained models for word embedding with morphological information. Additionally, there are online platforms such as Hugging Face and Google Colab that provide easy-to-use interfaces for training and deploying NLP models.
The market for learning word embedding by using morphological information is also driven by the increasing availability of data. The availability of large amounts of text data has enabled researchers to develop more accurate and robust models for word embedding with morphological information. This has led to the development of state-of-the-art models such as ELMo, BERT, and GPT-2, which have achieved impressive results in various NLP tasks.
In conclusion, the market for learning word embedding by using morphological information is growing rapidly due to the increasing demand for NLP applications in various industries. This growth is driven by the development of tools and platforms that incorporate word embedding with morphological information and the availability of large amounts of text data. As the demand for NLP applications continues to grow, the market for learning word embedding by using morphological information is expected to expand further.
The Microsoft Technology Licensing LLC invention works as follows
In some cases, a machine-learning system can use morphological information to improve a deep-learning framework for word embedding. As morphological information, the system can use, for example, edit distances between words and between words. It may also consider longest common substrings, morpheme similarity, and syllable similarity. The deep learning framework can be applied to tasks such as query classification, text mining and information retrieval. The system can perform such tasks at a relatively high rate of efficiency and speed while using less computing resources compared to other systems.
Background for Learn word embedding by using morphological information
Data-driven or supervised algorithms for machine learning are becoming important tools in the analysis of information on portable devices, cloud computing, and other devices. Machine learning is a collection of algorithms that learn automatically over time. These algorithms are based on math and statistics, which can be used to diagnose problems, classify entities and predict events. These algorithms are used in a variety of applications, including semantic text analysis and web search. They can also be used for speech and object recognition and speech and object identification. Supervised machine learning algorithms are usually divided into two phases, training and testing. In the training stage, input examples that are typical of the data are used to create decision models. The learned model is then applied to new instances of data to determine different properties, such as similarity and relevance.
In general, a search engines processes a query directly by comparing terms from the query to terms from documents. In some instances, a search engine and a document may use different words to express a similar concept. In such cases, the search engine could produce unsatisfactory results. Search engines can enhance a query with synonyms. This technique, however, may not uncover conceptual similarities between the query and the document.
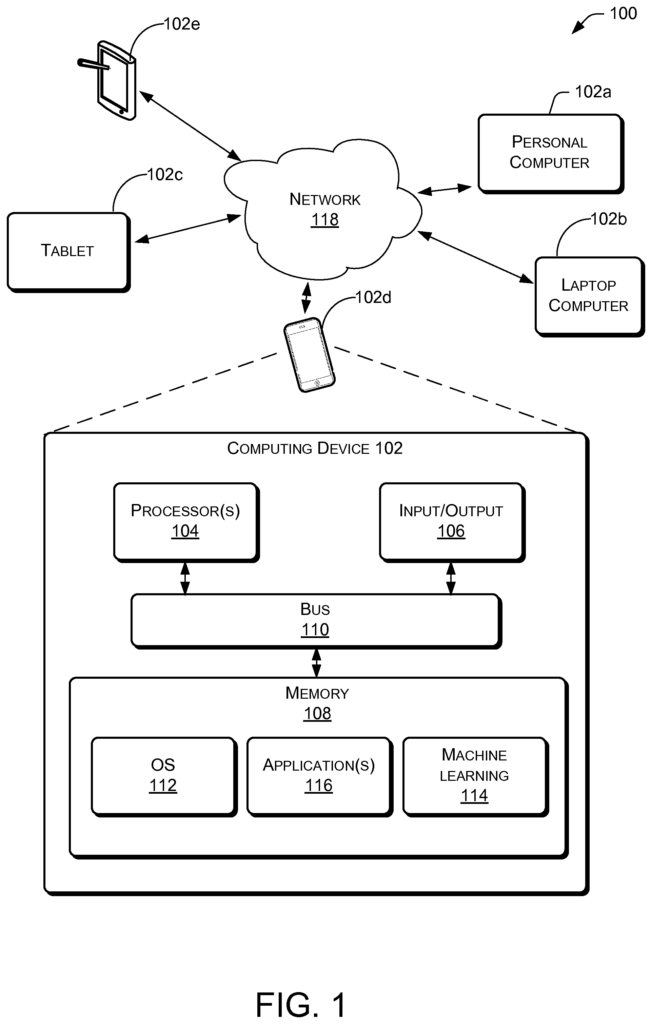
The use of neural network techniques to get high-quality representations of words is widely used to solve text mining, information retrieval and natural language processing problems. Although some methods can learn word embeddings by capturing both syntactic and semantic relationships between words in context, they may not be able to handle rare words or unseen words with inadequate context.
This disclosure describes techniques and architectures that can be used to improve a deep-learning framework for learning words embedding by using morphological knowledge. The system can, for example, use morphological information to create a relation matrix that includes morphological similarity between words and between words. The deep learning framework can be applied to tasks such as query classification, web searches, text mining and information retrieval. The system can perform such tasks at a relatively high rate of efficiency and speed while using less computing resources compared to other systems.
This Summary is intended to present a number of concepts that will be further explained in the detailed description. This summary is not meant to identify the key features or essential elements of the claimed matter. Nor is it meant to be used to determine the scope of claimed subject matter. The term “techniques” is used. The term?techniques’ is used throughout this document.
Word embeddings are a collective name for a set of language modeling and feature learning techniques in natural language processing. Word embeddings are a group of techniques for language modeling and feature-learning in natural language processing. In this technique, words (and perhaps phrases) from the vocabulary can be mapped into vectors of numbers in a low-dimensional space relative to the size of the vocabulary. The continuous bag-of word (CBOW), and the continuous Skip-gram models, can use the context surrounding a word to convert it into vectors in a continuous area. This allows them to capture both syntactic and semantic relationships. According to a fundamental principle, words with similar syntactic or semantic properties may have similar contexts. It may be hard to find word embeddings of new words that have not been seen before, since they do not appear in the previous vocabulary. The embeddings of rare words can also be unreliable because there are not enough contexts. The aforementioned methods are based on statistical methods. When a word is only found in a small number of training data, it may be difficult to extract statistical clues that will correctly map the word in the embedding area.
According to studies in cognitive psychology on word recognition, a person may be able, by contrast, to find effective ways to comprehend a new or uncommon word. One can, for example, conduct phonological recoding by blending graphemes to phonemes and blending syllabic unit into recognizable words. You can also use the root/affix to connect the new word with words you already know. Imagine the new word inconveniently. It is easy to assume that the new word inconveniently is an adverb of the original inconvenient. The latter is likely the opposite of convenient. Using morphological similarity to bridge between words can be a powerful tool for learning new words or uncommon words. In some embodiments, this word recognition is used to improve a deep-learning framework for word embedding. “Morphological similarity can be used to enhance machine learning processes that handle rare or new words, in addition to the context information currently used in CBOW or skip-gram.
Although morphological information can be valuable, blindly relying upon it may pose a risk. The prediction made based on word similarity could be a guess and there might exist examples that contradict the guess. If only morphological similarities are considered, it is possible to link convenient with convention, since they share a substring. These two words, however, are not similar in either syntactic or semantic terms. If we limit our considerations to morphological knowledge in this case, then the effectiveness of learned word embeddings could be low. For this problem, cognitive psychology findings on word recognition may be used. Humans can use contextual information to correct unreliable word similarity. This includes both the context of the reading and the context stored in the memory. Comparing their contexts allows one to distinguish between convenient or convention, and weaken their morphological link between the two words. In this application, some methods may use context to update morphological information during a machine-learning process. Methods need not trust the morphological information, but may alter the knowledge to optimize the consistency between contextual data and morphological similarity.
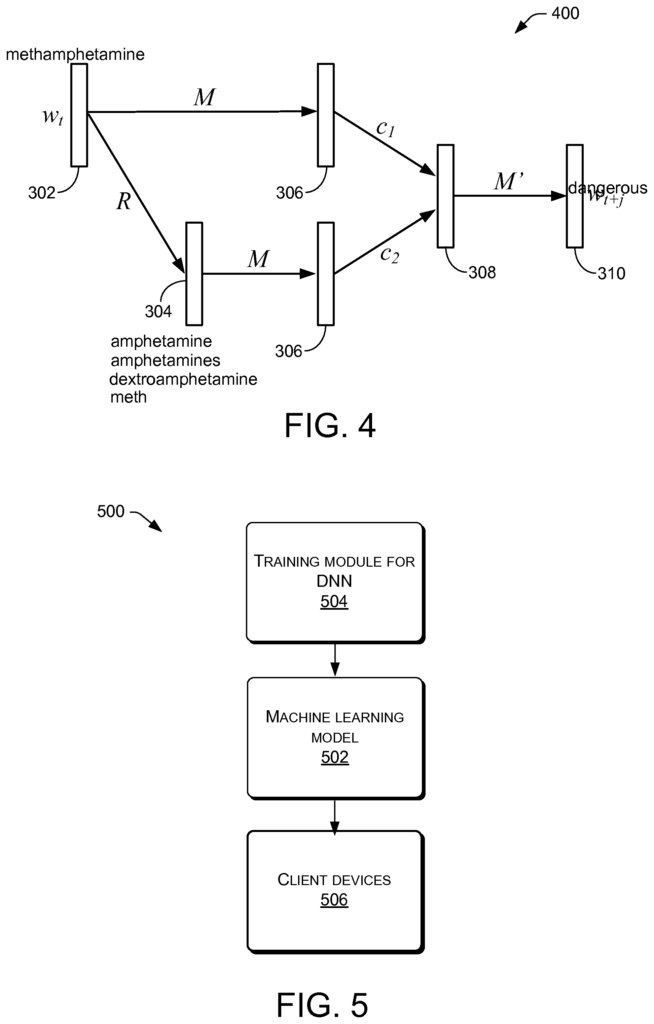
In various embodiments of the invention, methods that improve the performance of computer networks or systems, such as developing a neural-network architecture, can be developed to leverage morphological similarity in words for embedding. These methods can include a branch for contextual information and another branch for morphological knowledge. One way to include skip-gram models as a branch of contextual information is that they are relatively effective and efficient. The methods can also use edit distances, longest-common substring similarity, morpheme similarity, or syllables as morphological information to create a relation matrix among or between words. This relation matrix is then put into the branch of morphological learning. The two branches can share the same embedding space and be combined using tradeoff coefficients to feed forward the predicted target word. The back propagation may change the word embeddings and/or weights of the relation matrix, layer by layer. This framework is called “KNET” (e.g., Knowledge-powered neural NETwork). The KNET method may improve processing speed and accuracy as well as produce better word representations when compared to methods used on tasks such analogical reasoning and word similarity, for example.
In some embodiments, the neural network framework KNET can effectively use both contextual information as well as morphological knowledge in order to learn word embeddings. KNET can learn high-quality word embeddings for new and rare words with morphological information, even when the knowledge is not reliable. In some implementations KNET can benefit from noise knowledge and balance of contextual information and morphological know-how.
The following examples will be described in detail with reference to FIGS. 1-7.
The environment described below is only an example, and does not limit the claims in any way to a particular operating environment. “Other environments can be used without compromising the spirit and scope” of the claimed subject.
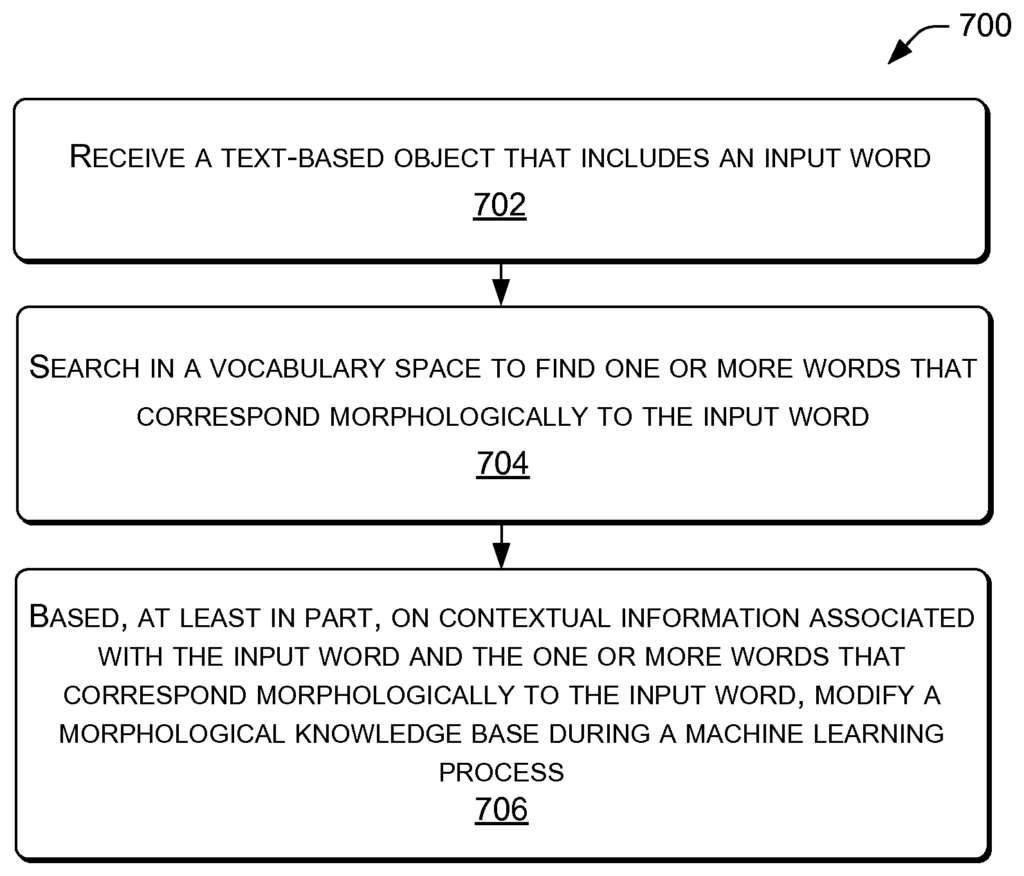
FIG. “FIG. 1 illustrates a typical environment 100 within which processes such as those described herein involving representational learning can be implemented. In some cases, computing devices 102 are included in the devices or components of environment 100. Computing devices 102, for example, may include devices from 102 a to 102 e. However, they are not limited by the device types shown. Computing devices 102 may include any device that has one or more processors 104 connected via a bus to memory 108 and an input/output interface. Computing devices 102 include personal computers like desktop computers 102a, laptops 102b, tablets 102c, telecommunications devices 102d, PDAs 102e, electronic books, wearable computers and automotive computers. Computing devices 102 may also include devices for business or retail, such as server computers, thin client terminals and/or workstations. Computing devices 102 may include components that are integrated into a computing device or appliance.
In some examples, all or part of the functionality described by computing devices 102 can be performed by one or several remote peers, a server or servers located remotely, or by a cloud computing service. In some cases, a computing system 102 can include an input port that receives an object containing linguistic information. The computing device 102 can further include one or more processors 104 that represent the object, for example, as an n dimensional representation.
In some cases, such as the example shown for device 102d, memory (108) can store instructions that are executable by a processor 104. These include an operating system 112, a module of machine learning 114 and programs or applications, 116, which processors 104 may be able to load and execute. One or more of the processors 104 can include central processing units, graphics processing units, video buffer processors and others. In some implementations the machine learning module comprises executable code that is stored in memory and can be executed by processors 104. This allows computing device 102 to collect data, either locally or remotely, using input/output system 106. Information may be linked to one or more applications 116. The machine learning module 114 can selectively apply one of the machine learning decision models that are stored in memory (or more specifically, in machine learning 114) in order to apply input data.
Although certain modules are described as performing different operations, they are only examples. The same or similar functionality can be performed by more or less modules. The functions that are performed by the modules shown do not have to be localized by one device. Some operations may be performed remotely (e.g. by a server, peer device, cloud etc .).
Hardware logic components can perform some or all functionality described in the present invention. Examples of hardware logic components include, but are not limited to, Field-programmable Gate Arrays, Program-specific Integrated Circuits, Program-specific Standard Products, System-on-a Chip systems, Complex Programmable Logic Devices, etc.
In some cases, the computing device 102 may be equipped with a camera that can capture images or video and/or audio. Input/output module (106, for example) can include a camera or microphone. Images of text can be converted into editable text. Then, they are entered in a database containing words, phrases and/or sentences. Audio recordings of speech can be converted into editable text, then entered into a database containing words, phrases and/or sentences. Memory 108 can include a single computer-readable medium or a combination.
Computer readable media can include computer storage media or communication media. Computer storage media include volatile and nonvolatile media, removable and not removable, implemented in any technology or method for storing information, such as computer-readable instructions, datastructures, program modules or other data. Computer storage media include, but are not limited to: phase change memory, static random-access memories (SRAM), and dynamic random-access memories (DRAM), as well as other types of random access memory, read-only storage (ROM), electrically eraseable programmable memory (EEPROM), Flash memory or other memory technologies, compact disk read only memory (CDROM), digital versatile discs (DVD), or other optical storage.
Communication media, on the other hand, embodies computer-readable instructions, datastructures, program modules or other data, in a modulated signal such as a carrier or another transmission mechanism. Communication media are not included in computer storage media as defined here. Memory 108, in various examples is an example computer storage media that stores computer-executable instruction. The computer-executable instruction(s), when executed by the processor(s), 104, configures the processor(s), among other things to: represent an input as a n-dimensional image; find a group or set of similar words; extract embedded words within the set from an embedding matrices based at least partly on contextual information related to the input; and generate a word with a meaning that is based at least partially on the set and contextual information.
In various examples, the input device for input/output interfaces (I/O) 106 could be a direct touch device (e.g. a touchscreen), an indirect touch device (e.g. a touchpad), or an indirect input (e.g. a keyboard, camera, or camera array). “An input device of an I/O interface 106 can be a direct-touch device (e.g., a touch screen), an indirect-touch device (e.g., a touch pad), or if you prefer ? i.e. ? based on purely visual means ? i.e. a camera array.
Click here to view the patent on Google Patents.
Leave a Reply