Invented by Shiqiang Wang, Theodoros Salonidis, International Business Machines Corp
Collaborative distributed machine learning involves the use of decentralized networks to train machine learning models. Instead of centralizing data in one location, this approach allows data to remain on individual devices or servers. This distributed nature ensures that data privacy is maintained, as sensitive information does not need to be shared with other parties.
One of the main drivers behind the growth of this market is the increasing need for privacy and security in the era of big data. Many organizations possess vast amounts of valuable data, but they are often hesitant to share it due to concerns about privacy breaches or intellectual property theft. Collaborative distributed machine learning addresses these concerns by allowing organizations to collaborate on training models without sharing the underlying data.
Another factor contributing to the market growth is the rise of edge computing. With the proliferation of Internet of Things (IoT) devices, there is a growing need to process data at the edge of the network, closer to where it is generated. Collaborative distributed machine learning enables organizations to train models directly on these edge devices, reducing the need for data transmission to centralized servers. This not only improves efficiency but also reduces latency and bandwidth requirements.
The market for collaborative distributed machine learning is not limited to a specific industry. It has applications in healthcare, finance, manufacturing, and many other sectors. For example, in healthcare, multiple hospitals can collaborate on training models to improve disease diagnosis or predict patient outcomes without sharing patient data. In finance, banks can collaborate on fraud detection models without revealing customer transaction details.
Several companies are already capitalizing on the opportunities presented by collaborative distributed machine learning. They offer platforms and tools that enable organizations to securely collaborate on training models. These platforms often incorporate privacy-preserving techniques such as federated learning, differential privacy, or secure multi-party computation.
As the market continues to grow, there are challenges that need to be addressed. One of the main challenges is the complexity of implementing collaborative distributed machine learning. It requires expertise in both machine learning and distributed systems. Additionally, ensuring the security and privacy of the collaborative process is crucial, as any vulnerabilities could lead to data breaches or model poisoning attacks.
Despite these challenges, the market for collaborative distributed machine learning is poised for significant growth. The benefits it offers in terms of privacy, security, and efficiency make it an attractive option for organizations looking to leverage machine learning capabilities while protecting sensitive data. As more industries recognize the potential of this approach, we can expect to see increased adoption and further advancements in the field.
The International Business Machines Corp invention works as follows
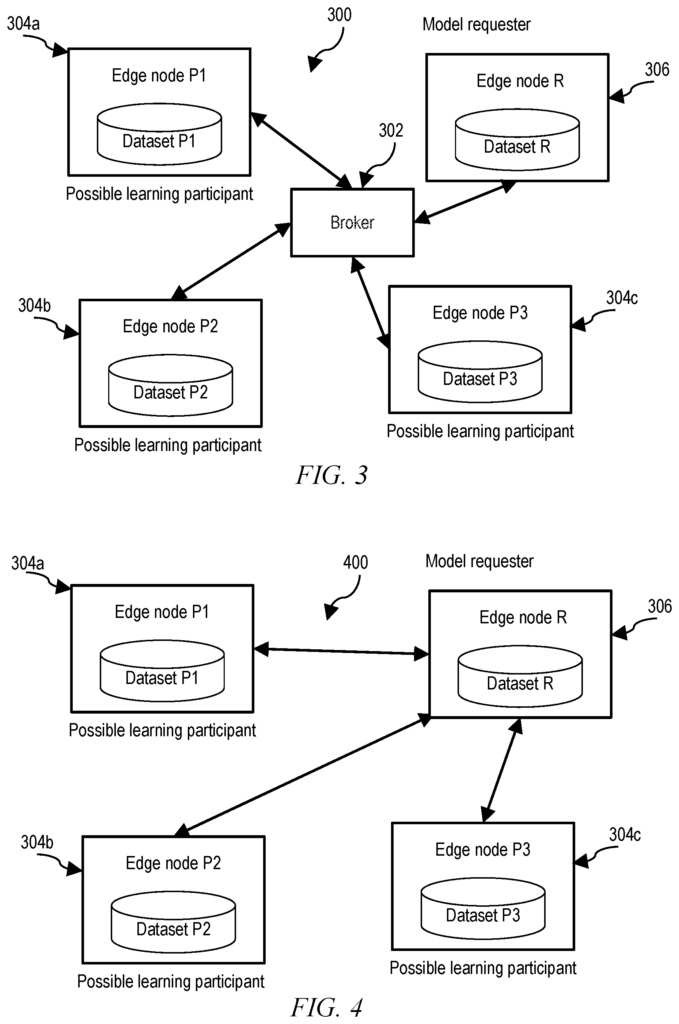
A model node is an edge node in a cloud computing system. It generates a machine-learning model specification, distributes it to other edge nodes and receives their replies. The model requester node then identifies the set of participating edgenodes in response to the replies based on the learning utility and cost estimates of each of the other edgenodes. The model requester then trains the machine-learning model without exchanging data between the model requester and the edge nodes. It does this by: repeatedly distributing the most recent parameters of machine learning to the edge nodes participating in the training; receiving updates on the most recent parameter from the edge nodes participating in the training; and establishing the new parameters for machine learning by aggregating updates from participating edgenodes.
Background for Collaborative distributed machine learning
The present invention is related to machine learning and, more specifically, the distribution of machine-learning across collaborative computing nodes.
Many emerging applications, such as Internet of Things, social networking and crowd-sourcing, generate a huge amount of data on the edge. The amount of data is predicted to increase exponentially, but the growth in communication bandwidth per year has decreased over the past few years. Research organizations predict that 90% of data in the future will be processed and stored locally.
Machine Learning is a popular technique for using large datasets to build models. Models can be trained and then used for various applications. “Distributed machine learning and Federated Learning enable model training without having to send raw data to a centralized location.
In general, machine learning is implemented using a cognitive network. A cognitive neural networks includes a number of computer processors configured to work together in order to implement one or several machine learning algorithms. Implementation can be synchronous, asynchronous, or both. In a network of neural units, the processors can simulate thousands or even millions of neurons that are interconnected by axons, synapses, and other axonal structures. Each connection has a different effect on the activation states of neural units connected. Each neural unit has its own summation function that combines all of the input values. In some implementations there is a threshold or limiting function for at least certain connections and/or neural units. This means that the signal has to exceed the limit in order to propagate. A cognitive neural net can be used to implement unsupervised or semi-supervised machinelearning. The cognitive neural networks learns by changing parameters in a model that creates outputs based on inputs. Model parameters include output weights for each neuron as well as threshold functions (optionally).
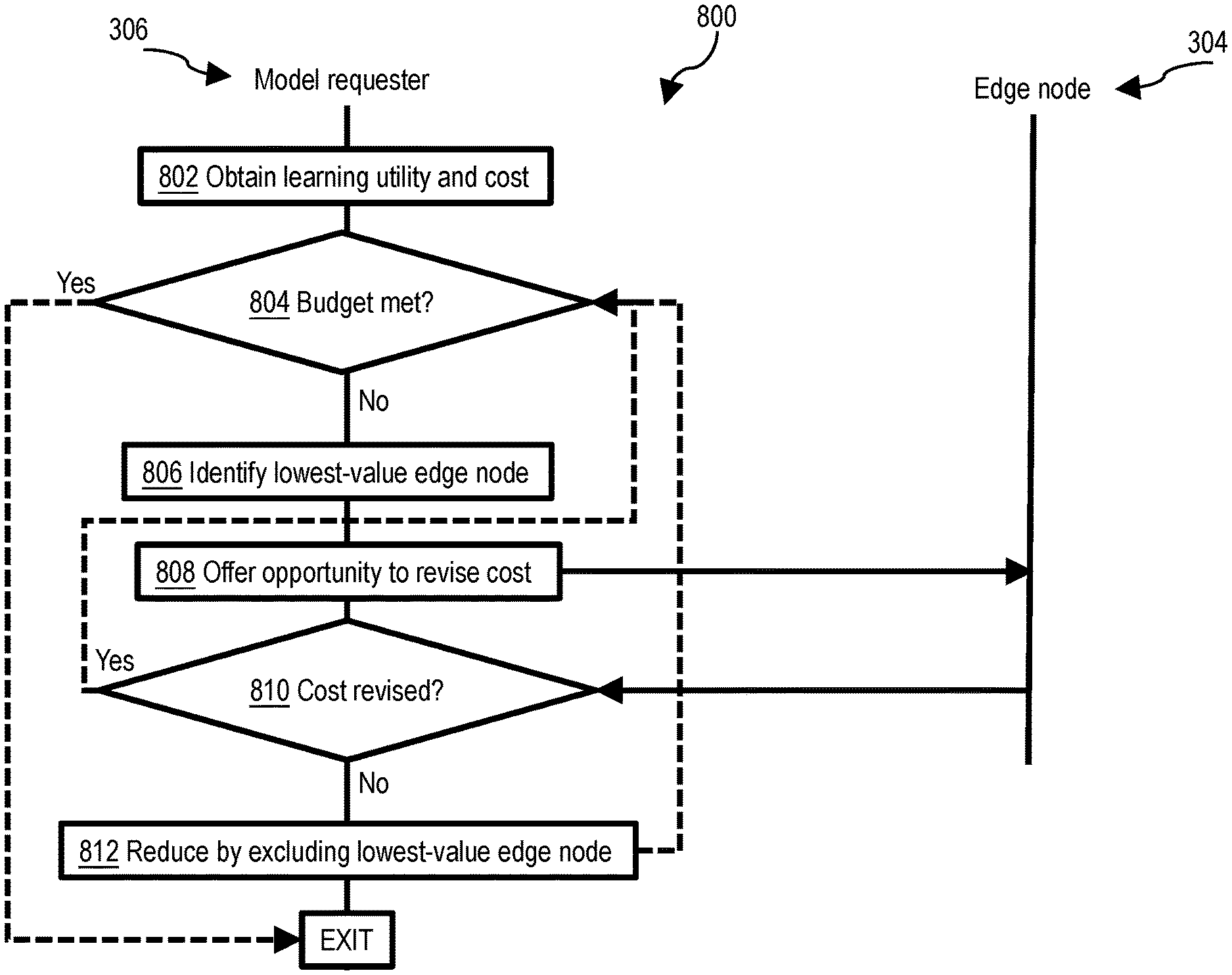
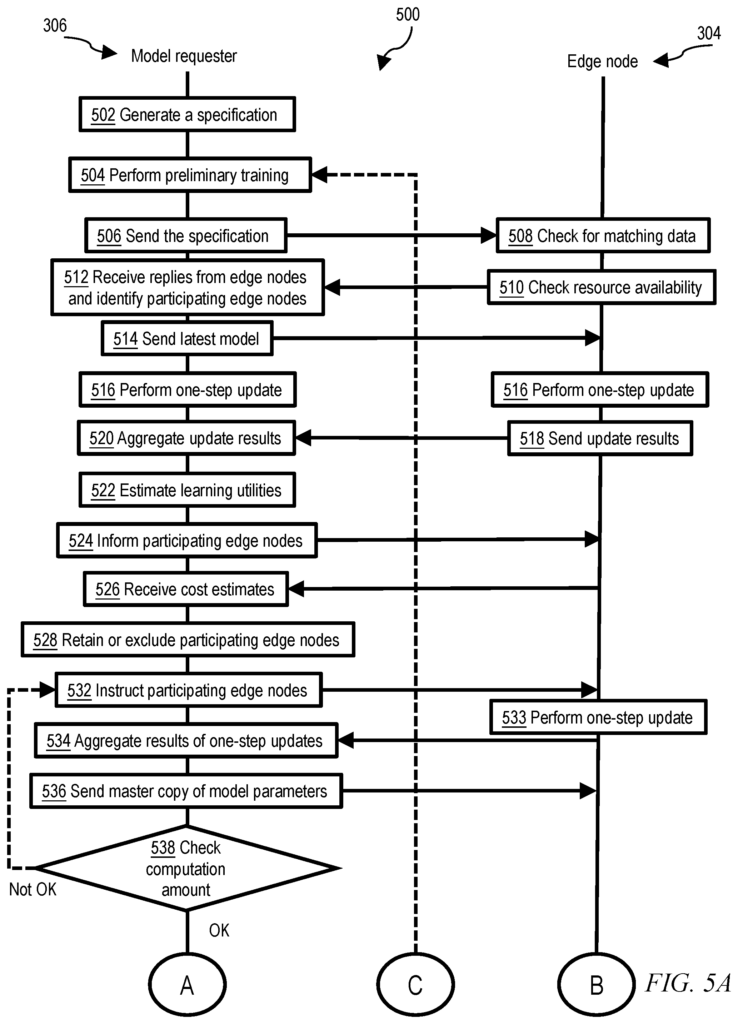
The principles of the invention provide techniques to collaboratively distributed machine learning. A computer-implemented distributed machine learning method includes, in one aspect, a model node that is an edge node within a network. The model node generates a specification for a machine learning node. It then distributes the specification to other edgenodes on the network and receives replies from those other edgenodes. The model requester node then identifies the edge nodes who are able to match the specifications in response to the replies. The model requester then trains the machine-learning model without exchanging data between the model requester and the participating edges nodes. It does this by: repeatedly distributing the most recent parameters of machine learning to the participating edges nodes. Receiving updates to the most current parameters from the participants edge nodes.
The model requester then aggregates the external and internal updated parameters at the requester, estimates learning utility of each of the plurality of edge nodes (based on comparison of the external updated parameters to the internal updated parameters), requests cost estimates from each of the plurality of edge nodes, and identifies a lowest-value edge node among the plurality of edge nodes based on a smallest value of a ratio of learning utility to cost estimate for each of the other edge nodes. The model node aggregates external and internal parameters, then estimates the learning utility for each other edge-node (based on comparisons of external updated parameters and internal updated parameter), requests cost estimates from all of the other edge-nodes and identifies the lowest value edge node based on the smallest ratio of learning utility and cost estimate. The model requester then reduces the number of edge nodes in the plurality by excluding the edge node with the lowest value. It generates a group of participating edge-nodes from this plurality by repeating the steps of identifying, reducing and increasing until the total cost estimate from the other edge-nodes falls within the budget of the requester. The model requester node uses the set of participating edges to train the machine-learning model. It does this by continuously distributing the most recent parameters to the edge nodes participating in the training, by receiving updates to these parameters from those edge nodes participating, and by aggregating updates from all the edge nodes participating.
As used herein, ?facilitating? An action can be defined as performing an action, making it easier to perform the action, assisting in the execution of the action, or causing it to be performed. By way of illustration, and without limitation, instructions running on one processor could facilitate an action performed by instructions running on another processor by sending data or commands that cause or assist the action to be carried out. To avoid any doubt, even if an actor performs the action but facilitates it, that action is still performed by another entity or combination.
One or more embodiments or elements of the invention can be implemented as a computer-readable storage medium including computer-usable program code to perform the method steps specified. One or more embodiments or elements of the invention can also be implemented as a system or apparatus including a memory and at least one computer coupled to the memory to perform exemplary methods steps. In another aspect, however, one or several embodiments of this invention or its elements can be implemented as means for performing one or more method steps described in this document. The means can include: (i), hardware module(s), or (ii), software module(s), stored on a tangible computer-readable storage medium or multiple such media, and implemented by a hardware processor.
The present invention has a number of technical benefits. “For example, one embodiment or more provides one or both of:
Distributed Machine Learning with Enhanced Speed.
Distributed Machine Learning with Reduced Bandwidth Consumption.
Distributed Machine Learning with Resource-efficient Selection of Learning Nodes.
Distributed Machine Learning with Price Negotiation among Different Learning Nodes.
The following detailed description, in conjunction with the accompanying illustrations, will reveal these and other features and benefits of the invention.
It is important to note that, although this disclosure contains a detailed description of cloud computing, the implementation of the teachings contained herein aren’t limited to a computing cloud environment. The present invention can be implemented with any type of computing environment, whether it is now known or developed in the future.
Cloud computing is a service delivery model that enables convenient, on demand network access to configurable computing resources, such as networks, network bandwidths, servers, processors, memory, storage and applications. This can be provisioned quickly and released without requiring much management or interaction with the service provider. This cloud model can include at least five features, at least three services, and at most four deployment models.
Characteristics include:
On-demand Self-Service: A cloud consumer can unilaterally provide computing capabilities such as server time or network storage as needed without needing to interact with the service provider.
Broad Network Access: Capabilities are available on a network, and can be accessed by standard mechanisms, which promote the use of heterogeneous thin and thick client platforms, such as mobile phones, laptops and PDAs.
Resource pooling is a method of pooling computing resources to serve many consumers. This is done using a multitenant model. Different physical and virtual resources are dynamically assigned to and reassigned based on demand. Location independence is achieved by the fact that consumers are not aware of or have no control over the location of provided resources. However, they may be able specify the location of those resources at a higher abstraction level (e.g. country, state or datacenter).
Rapid Elasticity: Capabilities can be provisioned rapidly and elastically, in some instances automatically, for quick scaling out, and released rapidly to quickly scale up. The consumer may perceive that the provisioning capabilities are unlimited and available at any time.
Click here to view the patent on Google Patents.
Leave a Reply