Invented by Jack Copper, Neuralstudio Secz
Data preparation is a critical step in the machine learning process, as it involves cleaning, transforming, and organizing raw data to make it suitable for analysis by machine learning algorithms. This process ensures that the data is accurate, complete, and in a format that can be easily understood by the algorithms.
One of the main drivers of the market for data preparation systems and methods is the increasing adoption of machine learning across industries. From healthcare and finance to retail and manufacturing, organizations are leveraging machine learning algorithms to gain insights, make predictions, and automate processes. However, without proper data preparation, these algorithms may produce inaccurate or unreliable results.
Another factor contributing to the growth of this market is the exponential growth of data. With the advent of the Internet of Things (IoT) and the proliferation of digital devices, organizations are generating vast amounts of data every day. This data is often unstructured, messy, and scattered across various sources. Data preparation systems and methods help organizations tackle this data deluge by efficiently cleaning, integrating, and transforming data into a usable format for machine learning.
Furthermore, the increasing complexity of data sources and formats has also fueled the demand for data preparation tools. Data can come from a variety of sources, including databases, spreadsheets, social media, sensors, and more. Each source may have different data formats, structures, and quality. Data preparation systems and methods provide organizations with the ability to handle these diverse data sources and formats, ensuring that the data is consistent and ready for analysis.
The market for data preparation systems and methods is highly competitive, with numerous vendors offering a wide range of solutions. These solutions vary in terms of functionality, scalability, ease of use, and integration capabilities. Some vendors provide standalone data preparation tools, while others offer integrated platforms that combine data preparation with other machine learning capabilities.
In addition to traditional data preparation techniques, such as data cleaning, transformation, and integration, the market is also witnessing the emergence of advanced techniques like data wrangling and feature engineering. Data wrangling involves the process of cleaning and transforming data in a flexible and iterative manner, allowing data scientists to explore and experiment with different data transformations. Feature engineering focuses on creating new features from existing data to improve the performance of machine learning models.
As the market for data preparation systems and methods continues to grow, organizations are increasingly looking for solutions that offer automation, scalability, and ease of use. They want tools that can handle large volumes of data, integrate with existing systems, and provide intuitive interfaces for data scientists and business users alike.
In conclusion, the market for systems and methods for preparing data for machine learning algorithms is experiencing rapid growth due to the increasing adoption of machine learning, the exponential growth of data, and the complexity of data sources and formats. As organizations strive to derive meaningful insights and predictions from their data, the demand for efficient and effective data preparation tools will continue to rise.
![]()
The Neuralstudio Secz invention works as follows
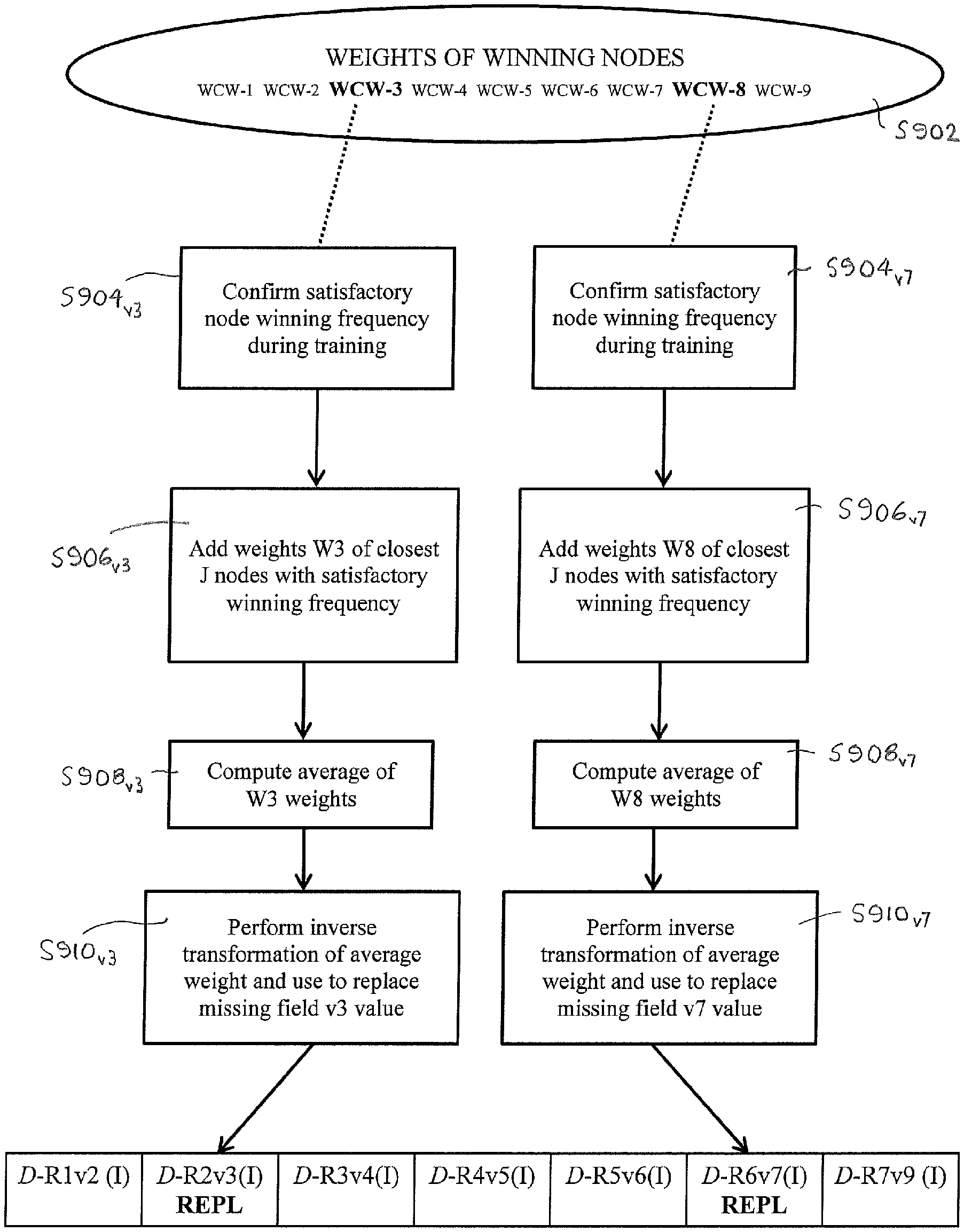
Historical data is used to train machine-learning algorithms. It can contain thousands of records and hundreds of fields. This data will inevitably include faulty data which affects accuracy and utility of the primary model machine-learning algorithm. To improve the integrity of the dataset, it is separated into two datasets: a clean dataset with no invalid values and a flawed dataset that contains invalid values. The clean dataset will be used to train a secondary machine learning algorithm to produce from multiple complete data records, a replacement value to replace a single invalid value in a record. A tertiary machine learning clustering model algorithm will then be trained to create from multiple complete data records, replacement values to replace multiple invalid values. The augmented data is created by substituting invalid data values with the clean dataset. This augmented data can then be combined with the clean data in order to train an accurate primary model.
Background for Systems and Methods for Preparing Data for Machine Learning Algorithms
Field of Invention
The present invention is related to machine learning and, more specifically, to systems and method for improving the quality and integrity of data used to train and apply machine learning algorithms in order to increase the accuracy and utility of computer implementations of and executions such algorithms.
Description of Related Art.
A mathematical expression is a mathematical description of a phenomenon that has enough accuracy and consistency to be useful in real life. There are two types of mathematical models. The first is called a “first principles” model. The first is a?first-principles? model that attempts to describe an interesting phenomenon on the basis fundamental laws in physics, chemistry and biology. The second model is called an “empirical” model. Models that attempt to describe phenomena of interest by collecting and analysing data are called ’empirical models.’ This type of data processing is also known as “machine learning”. It involves applying a learning algorithms iteratively to a set of data that supposedly describes an interesting phenomenon. The algorithm learns to discover and understand the relationships between the data which reflect or govern the behavior.
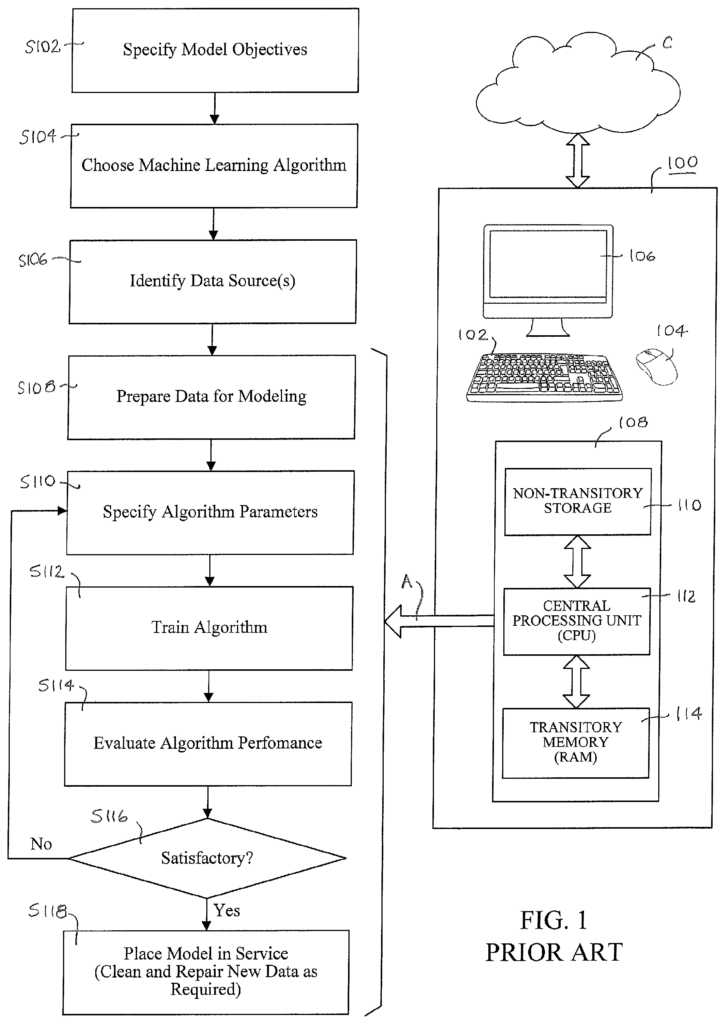
FIG. The overview of the computing system 100 is shown in Figure 1. The right side of FIG. The computing system 100 is shown in Figure 1 with a mouse 104 and keyboard 102 for the model developer to enter information into the computer system, and a display 106 to show outputs. Other conventional input/output device can be included in the computing system, including a printer, scanner or touch pad. USB ports are also possible. The computing system 100 comprises a computing unit 108, which consists of a non-transitory memory module 110 that is resident on a solid state memory or disc drive, a central processor (CPU 112) that loads data and programs into the memory module 110, executes these programs to process data, and a temporary random access memory (RAM), used by the CPU, when executing programs. The CPU 112 is controlled by the operating system software, which also controls the display of information on the monitor. The cloud C is connected to the computing system 100 via a two way connection, as shown in the diagram.
The left-hand part of FIG. The figure 1 shows a typical machine learning process that can be used with the data preparation techniques described in this document. At step S102, the goals of the modeling process will be specified. A person who has sufficient knowledge about the domain (subject) is required to identify the problem. For example, the performance metrics will be used for judging the quality and utility. If the model is either a classification or prediction model, then one or more values are required (commonly referred to by the term “target values”). The developer will identify one or more values (often referred to as?target values?) that represent one of several phenomena of interest.
In step S104, a machine-learning algorithm is selected for the generation of an empirical model. In general, supervised learning is used to solve prediction problems, with the target values being more or less continuous numerical values. The model output of a prediction machine learning algorithm is a continuous line (curve) that fits historical data. As with classification problems, supervised learning is also used. The model output for a classification problem is the target values. These are discrete classes that have labels. A classification machine learning algorithm, in general, maximizes the likelihood that data within a record indicates that it belongs to a specific category. Clustering problems are usually solved using unsupervised algorithms, which identify similarity in data. The nature of the problem – prediction, classification or clustering – determines which algorithm is used by the model designer. This computer implementation may be available commercially or developed by a developer. The machine learning algorithm, in general, seeks to establish a relationship between the data collected in one record and an output that is of interest. This output can be a numeric target value, a discrete categorical target value, or a result which indicates similarities in data values across a group of records.
The remaining steps of the process shown in FIG. The computing system implements 1 in accordance with chosen machine learning algorithms to develop the specified models using identified data. The machine learning process is conceptually distinct from the preliminary steps S102 to S106. This process is implemented by a computing system, as shown by the arrow in FIG. 1. The preliminary steps shown are conceptual. The computing system may include programs that organize data or interface with databases or files containing data. However, this is not an important aspect of computerized empirical model development, as it is commonly used.
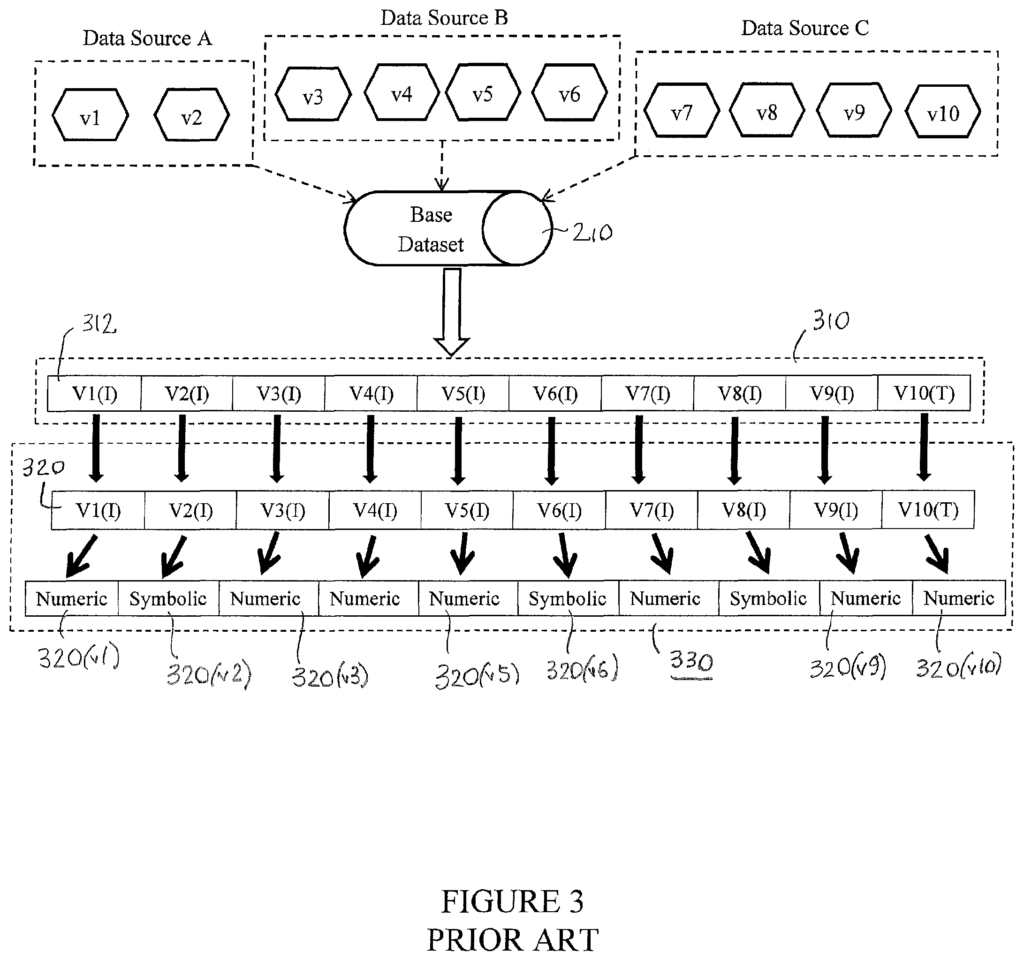
In a subsequent step S108, the computing system 100 prepares historical data to be used by a machine-learning algorithm. The data preparation involves putting the data into a format that is suitable for the machine-learning algorithm selected in step S104. For example, the data can be placed in sequential data records with the same number fields. Data is fundamental to the development of empirical models via machine learning. The integrity of the data therefore has a major impact on the quality and utility of the model. The data that is used in the machine learning algorithm is critical, but the machine learning algorithm does not directly address the issues of validity/integrity (for example how invalid values should be treated for certain data points). Below, we discuss some of the methods used in the prior arts to address such data issues independently of the machine-learning algorithm.
In the next step S110, the model developer specifies parameters that will be used by the algorithms to process the data. There are parameters that determine the behavior of an algorithm. For example, how long it will run, and what internal objective function is used to measure performance. The parameters of the algorithm may be determined by the experience of the algorithm developer, published heuristics, or automatically using a general-purpose optimizer, such as genetic algorithms.
![]()
The next step S114 is to evaluate the performance of the algorithms by comparing output values (credit score) generated by an algorithm with actual credit scores that were included in historical data. Model developers typically define what constitutes a satisfactory outcome based on the characteristics of the domain of application and the trade-offs that must be made between a high performance level and the costs of obtaining it, such as obtaining additional training data or spending extra time testing the effect of changing the algorithm parameters. If the model meets these criteria, then the answer to the decision step S116 will be ‘YES.’ The model is then placed into service as shown at step S118. If the answer to step S116 is “NO”, then the process will revert back to step S110 where new algorithm parameters are input and then proceed as before through steps S112 toS116. The process then returns to step S110, where the new algorithm parameters will be input. It will then proceed as before to the steps S112 and S116. The process (which is not shown in the drawing) can also include getting additional data at step S106, and then proceeding to step S116. The model can be used for generating an output value based on any new set data points, organized in the same way as the historical data but without target values. This data is inputted through the computing system 100 that executes the algorithm. The systems and methods described in this document are applicable to both supervised and unsupervised learning.
When applying machine learning algorithms to data produced by typical ?real world? data sources, problems with the integrity and quality of the data abound. Such problems include, but are by no means limited to: data accidentally or deliberately omitted when forms are completed by humans, typographical errors that occur when humans transcribe forms and enter information into a computing system, and errors made when optical character recognition or voice recognition systems process raw data and convert it into a form suitable for use by machine learning algorithms. Hardware problems can also cause errors when data moves from a source (such as a sensor) to a repository (for example, a database). Sensors can fail and thus provide no data at all. The conduit for the data can be ?noisy?-electromagnetic interference, simple corrosion of wire terminal connectors, or a faulty or damaged cable can all introduce artefacts-such that the data that is placed in a repository is not an accurate reflection of the information originally produced and transmitted. When faulty data are detected, the affected machine learning process essentially has only two choices: ignore the data (along with related possibly valid data acquired in the same context) or replace the data. Replacing a data point requires generating replacement values that are most likely to reflect what the ?correct? value should be, so that all of the data, in context, can be used as intended.
Despite the importance of data in the development of empirical models (machine-learning) and the significant advancements in empirical modeling algorithms, and the enormous quantities of raw data generated in systems all over the world every second, there have been few improvements in the quality of historic data to be used by the machine learning algorithms in order to develop primary model of an interest phenomenon. The prior art also saw a lack of progress with respect to techniques for preparing data that will be used by models after they have been put into service. Throughout the present invention, “missing data” is used. Refers to a field (data point) in a record that is empty. The term ‘invalid data’ is more general. This term refers to incorrectly represented data (for instance, a numeric value intended to be numeric but contains non-numeric character) or data whose values exceed the limits set by the developer or administrator who produced the data. The term “invalid data” is used to describe this. includes ?missing data? ; likewise, ?missing data? Invalid data is also referred to as’missing data.’ The terms may be used interchangeably, but those who are skilled in the field will know the meaning from the context.
In a report titled “Missing data techniques with SAS” published by the UCLA Institute for Digital Research and Education in 2017, some of the most common approaches to dealing with low-quality data are described. available online at https://stats.idre.ucla.edu/wp-content/uploads/2017/01/Missing-Data-Techniques_UCLA.pdf. Loely Bori, M., “Dealing with Missing Data: Methods and Assumptions for Applied Analysis”, is another source for prior art regarding data preparation for machine learning algorithms. Tech. Rept No. 4, Boston Univ. School of Public Health, May 6, 2013, available online at http://www.bu.edu/sph/files/2014/05/Marina-tech-report.pdf. These documents are incorporated by reference herein in full because they discuss prior art techniques to deal with invalid data within a machine-learning context.
The simplest way to deal with missing data would be to ignore them. If a field of a data record has no value then the whole record is discarded. This approach, although simple to implement, can have unacceptably negative consequences when the quantity of data is also a concern (i.e. when events of importance occur so rarely that it’s important to retain and use any data related to these events). If the invalid data is from a continuous series of numeric data, an alternative approach can be taken. The approach uses other data from the same series to calculate a replacement value (for instance, data points within the same column in an entire dataset presented in tabular format). In the case of a numeric data field, like an individual’s date of birth, valid data will fall within a certain range. Invalid data is either no data in that field or a number which clearly does not represent an individual’s age, like 430. In order to avoid ignoring the invalid data, it is best to replace the value with the average of all valid values within the same series. Using such methods to select replacement values is almost certain to produce unsuitable results, but it will prevent the need to throw away an entire record. The IDRE report describes more complex replacement schemes. However, they tend to force unwarranted linearity assumptions on data. These techniques are moderately effective for replacing a single invalid data value in a series of data, but they can introduce errors when multiple invalid values are used.
All of these approaches are mathematically feasible, and they’re relatively easy to implement. Their simplicity, however, can result in values being assigned to missing data which may not be justified by the valid data in the same field (column) or row (record), as a whole. They tend to hide the context that valid data values provide in the same record with the invalid data. The data values of any record have a logical relationship, for example, a representation of a system of interest, or the attributes of the entity that is represented by the particular record at a certain time. In general, the methods for replacing invalid or missing numeric values in a data record do not take into consideration the temporal and logical relationships between the valid data.
Similar approaches have also been used with non-numerical (symbolic) or categorical data. For such data, a typical approach is to use either the mode of all “good” Alternatively, you can use zero as a value. In this case, symbols or categorical value would be typically transformed into?1-of n? Binary values are used to represent invalid data. Consider a field that contains the occupation of an individual. The categories in the dataset are:?Attorney?,?Engineer? ?Manager,? The words?Manager? This is because n = 4 and the symbolic/categorical value that occurs in one field (column) will be converted into four binary fields (columns), where each column contains the value 0, or 1. Then, the data can be processed using a machine-learning algorithm. ?Attorney? Engineer? ?Engineer? Manager? The value?Physician? If a missing value or an invalid value were transformed into 0 0 1 by an algorithm, it would not be a true representation of reality, and the model would therefore be suboptimal.
The prior art lacks a method of preparing data to be used with a machine-learning algorithm that can account for invalid or missing data. This will allow the model that represents the algorithm, when placed into service, to produce a more accurate output. It is necessary to develop better systems and methods to replace invalid data values with replacement values that take into account the context of when the invalid values were generated. This will allow models already in use to be exploited more fully and produce a viable outcome when they are presented with invalid or missing values.
The present invention aims to improve systems and methods of preparing data used in training a primary algorithm for machine learning so that the algorithm performs better after training using corrected historical data, and then when placed into service with new data that contains invalid values. The assumption behind supervised machine learning is that a number of outputs in a set of historical values have a causal relation with the plurality of data values associated with the multiple instances of each historical output value.
Click here to view the patent on Google Patents.
Leave a Reply