Invented by Geoffrey B. Rhoads, Tony F. Rodriguez, William Y. Conwell, Digimarc Corp
Content processing refers to the various techniques and tools used to manipulate and analyze content in order to derive meaningful insights and make informed decisions. This can include tasks such as text extraction, data cleansing, sentiment analysis, topic modeling, and natural language processing (NLP). These methods are essential for businesses looking to gain a competitive edge by leveraging the wealth of information available to them.
One of the key drivers of the market for content processing methods is the need for businesses to automate and streamline their operations. Manual content processing can be time-consuming, error-prone, and inefficient. By adopting automated methods, businesses can save time and resources, improve accuracy, and enhance productivity. For example, NLP techniques can be used to automatically extract relevant information from large volumes of text, enabling businesses to quickly identify trends, patterns, and insights that can inform their decision-making processes.
Another factor contributing to the growth of this market is the increasing focus on customer experience and personalization. In today’s digital age, consumers expect personalized and relevant content tailored to their specific needs and preferences. Content processing methods enable businesses to analyze customer data, understand their preferences, and deliver personalized content and recommendations. This not only enhances the customer experience but also increases customer engagement and loyalty.
Furthermore, the market for content processing methods is driven by the need for effective content management and organization. With the exponential growth of digital content, businesses and individuals struggle to keep track of and manage the vast amounts of information they generate and consume. Content processing methods provide solutions for organizing, categorizing, and tagging content, making it easier to retrieve and access relevant information when needed.
The market for content processing methods is highly competitive, with a wide range of vendors offering various solutions and tools. Some of the key players in this market include IBM, Google, Microsoft, Amazon, and Adobe. These companies offer comprehensive platforms and tools that encompass a range of content processing techniques, catering to the diverse needs of businesses across industries.
In conclusion, the market for methods for processing content is experiencing significant growth due to the increasing demand for efficient and effective ways to handle large volumes of information. Businesses are adopting these methods to automate and streamline their operations, enhance customer experience and personalization, and improve content management and organization. As the digital landscape continues to evolve, the market for content processing methods is expected to expand further, offering innovative solutions to address the ever-growing challenges of content management and analysis.

The Digimarc Corp invention works as follows
Mobile phones and portable devices have a wide range of technologies that can improve existing functionality and provide new functionality. Some aspects are related to visual search and the determination of appropriate actions in response to different input images. Other aspects relate to the processing of image data. Others are concerned with the generation, processing and presentation of metadata. Others are concerned with improvements to the user interface. Another aspect relates to imaging architectures in which the mobile phone’s camera is just one of a series of stages that act sequentially on packetized data/instructions to capture and process images. Other aspects concern the distribution of processing tasks among mobile devices and remote resources (the cloud). Other operations, such as simple edge detection and filtering, can be delegated to remote service providers. Remote service providers can also be selected by using reverse auctions in which they compete to complete processing tasks. “A large number of features and arrangements have also been detailed.

Background for Methods for processing content
Digimarc’s U.S. Pat. No. No. This derived identification is then submitted to a datastructure (e.g. a database) which will indicate corresponding data and actions. The cell phone displays the information or performs an action in response. This sequence of operations can be referred to by some as “visual search.
Patent publications 20080300011(Digimarc), U.S. Pat. No. No. No. No. 6,491,217 (Philips), 20020152388 (Qualcomm), 200020178410 (Philips) and 20050144455(AirClic), U.S. Patent No. No. 7,251,475 (Sony), U.S. Pat. No. 7,174,293 (Iceberg), U.S. Pat. No. 7,065,559 (Organnon Wireless), U.S. Pat. No. 7,016,532 (Evryx Technologies), U.S. Pat. Nos. Nos. 6,993,573 (Neomedia) and 6,199.048 (Neomedia), U.S. Pat. No. 6,941,275 (Tune Hunter), U.S. Pat. No. 6,788,293 (Silverbrook Research), U.S. Pat. Nos. Nos. 6,766,363 (BarPoint) and 6,675,165 U.S. Pat. No. 6,389,055 (Alcatel-Lucent), U.S. Pat. No. No. 6,121,530 Sonoda) and U.S. Patent. No. 6,002,946 (Reber/Motorola).
Aspects” of the technology are improvements. Moving towards intuitive computing, devices can hear and/or see the user and determine their desire based on the sensed context.
The present specification describes a diverse range of technologies that have been assembled over a long period of time to meet a wide variety of objectives. They are related in different ways and therefore presented in a single document.
This complex, interrelated material does not lend itself well to a simple presentation. The reader is asked to be patient as the narrative sometimes proceeds in a nonlinear manner amongst the various topics and technologies.
Each section of this specification describes a technology that should be incorporated into other sections. It is therefore difficult to identify “a beginning”. This disclosure is logically supposed to begin at the beginning. “That said, let’s just dive in.
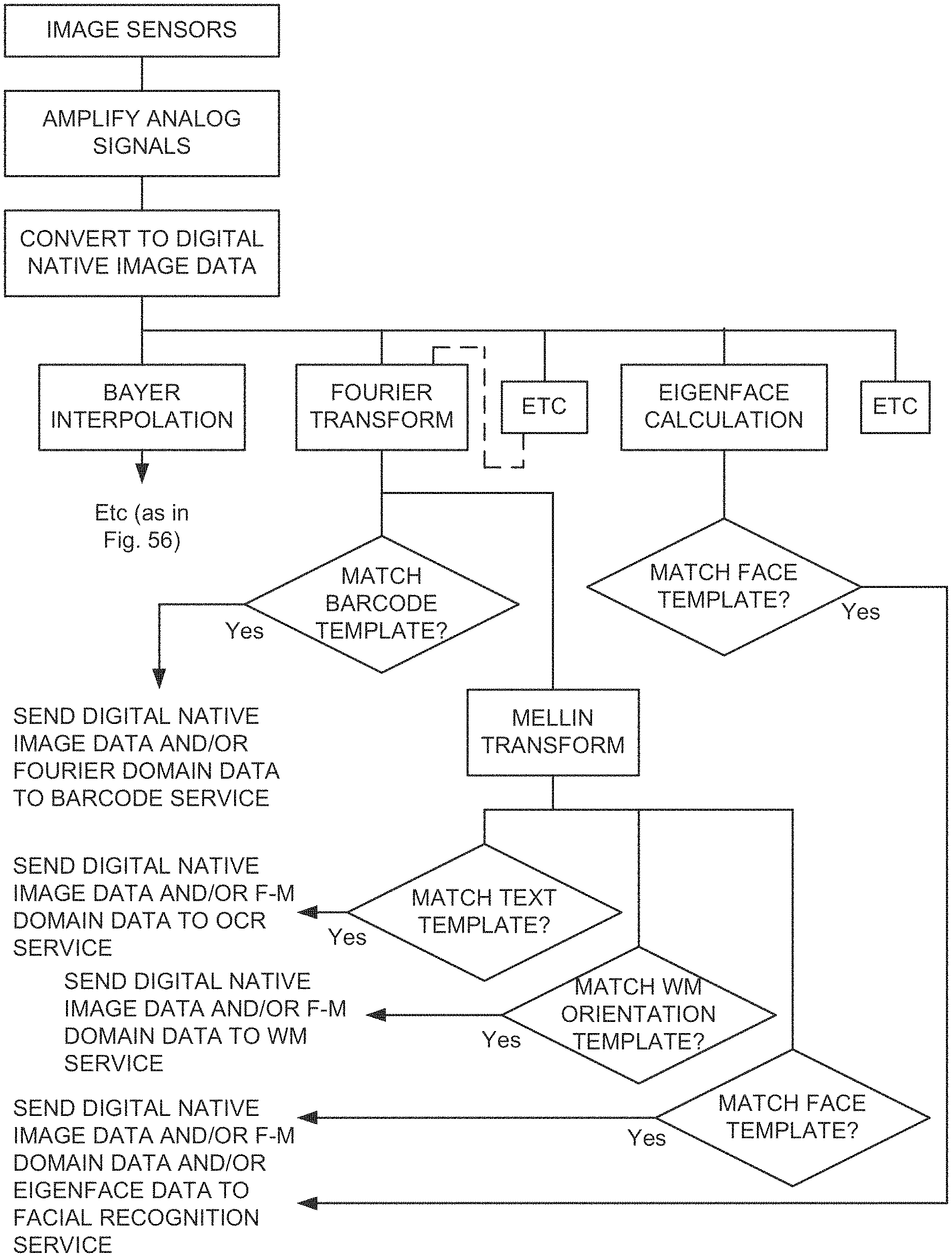
There is currently a large disconnect between the enormous amount of data that is present in the high-quality image data streamed from a mobile phone camera, and the device’s ability to process that data. ?Off device? Processing visual data is a great way to handle the firehose of data. This is especially true when multiple visual processing tasks are desired. These issues are even more important when’real-time object recognition and interactivity’ is considered. The user expects to see augmented reality graphics on the screen of their mobile device as soon as they point the camera at an object or scene.
According to one aspect of current technology, a network of distributed pixel processing engines serves such mobile device users. This meets the most qualitative “human real-time interactivity” requirements. Feedback is usually received in less than a second. Implementation should provide certain basic features for mobile devices, such as a close relationship between the output pixels of the image sensor and the native communication channel. Some basic levels of?content classification and filtering? The local device performs certain levels of basic?content filtering and classification? pixel processing services. The word “session” is the key. The term’session’ also refers to fast responses sent back to mobile devices. Or ‘interactive? A session is essentially a duplex communication that uses packets. Several incoming ‘pixel packets’ and several outgoing packets are sent every second. Every second, several packets of incoming data (which could be updated pixel packets) and several packets of outgoing data may occur.
The spreading out of applications from this starting point is arguably dependent on a core set of plumbing features inherent to mobile cameras. These features (which are not exhaustive) include: a. higher quality pixel recording and low-level processing; b. better CPU and GPU local resources for on-device processing of pixels with subsequent feedback from users; c. structured connectivity to ‘the cloud? In addition, there is a maturing infrastructure for traffic monitoring and billing. FIG. FIG. 1A shows a graphic view of some of the plumbing features that make up what could be described as a visually-intelligent network. For clarity, we have not included the usual details of a mobile phone such as a microphone, an A/D converter and modulation and demodulation system, IF stages or cellular transceiver.
It is great to have better GPUs and CPUs on mobile devices, but it’s not enough. Cost, weight, and power concerns seem to favor ‘the cloud’. Cost, weight and power considerations seem to favor getting ‘the cloud? “We will do as much of the?intelligence?

Relatively, it appears that there should be an overall set of ‘device-side’ operations. Operations on visual data will be used for all cloud processes. This includes certain formatting, graphic processing and other rote tasks. It seems that there should also be a standard basic header and address scheme for the communication traffic back and forth (typically packetized).
FIG. The list is not exhaustive but it serves as an example of the many visual processing applications available for mobile devices. It is difficult to not see the analogies between the list and how the visual system and brain work. It is an academic field that is well-studied and deals with the question of how “optimized” we are. The eye-retina, optic nerve-cortex system serves an array of cognitive needs very efficiently. This aspect of technology is about how similar efficient and broadly enabling components can be built into mobile phones, mobile device connections, and network services with the goal to serve the applications shown in FIG. This includes applications like FIG. 2, and any new ones that may appear as technology continues to evolve.
Perhaps, the most important difference between mobile devices networks and human analogy revolves around the concept of the marketplace. Where buyers continue to buy more and better products, as long as the businesses are able to make a profit. Any technology that aims to serve applications listed in FIG. It is a given that hundreds, if not thousands, of businesses will work on the details of commercial offerings with the hope of making money in some way. It is true that a few giants will dominate the mobile industry’s main cash flow lines, but it is also true that niche players will continue to develop niche applications and services. This disclosure explains how a market for visual processing services could develop where business interests from across the spectrum can benefit. FIG. FIG.
FIG. The introduction to the technology is a 4 sprint towards the abstract. We find an abstracted information bit derived from a batch of photons which impinged upon some electronic image sensor. A universe of consumers awaits this lowly bit. FIG. 4A introduces the intuitively known concept that individual bits of visual data are not worth much unless they’re grouped together in terms of both space and time. Modern video compression standards like MPEG? This core concept is well exploited in modern video compression standards such as MPEG?
The ?visual? Certain processing can remove the visual character of bits (take, for example, vector strings that represent eigenface data). We sometimes refer to ‘keyvector data’. (or ?keyvector strings?) To refer to raw sensor/stimulus information (e.g. pixel data), as well as processed information and derivatives. A keyvector can be a container that contains such information (e.g. a data structure like a packet). The type of data (e.g. JPEG image, eigenface) can be identified by a tag or another data. Alternatively, the data type could be evident in the context or data. Keyvector data may include one or more operations or instructions?either explicitly detailed or implied. For certain keyvector types, an operation can be implied by default (e.g. for JPEG data, it could be “store the image”). For eigenface, it may be “match this eigenface? template?”. “Or an implied operation could be dependent on context.
FIGS. The key player of this disclosure is also introduced in 4A and 4B: the packaged pixel packet with address labels, which contains keyvector data. Keyvector data can be a patch or collection of patches or a series of patches/collections. Pixel packets can be smaller than a kilobyte or much larger. It could be a small patch of pixels from a large image or a Photosynth of Notre Dame Cathedral.
When pushed around a network, however, it may be broken into smaller portions?as transport layer constraints in a network may require.) It may, however, be divided into smaller pieces when it is actually sent around a LAN, depending on the transport layer constraints of a LAN.
Click here to view the patent on Google Patents.
Leave a Reply