Invented by Kenneth Liam KIEMELE, John Benjamin Hesketh, Evan Lewis JONES, James Lewis Nance, LaSean Tee SMITH, Microsoft Technology Licensing LLC
Machine learning is a subset of artificial intelligence that enables computers to learn and make predictions or decisions without being explicitly programmed. It relies on large amounts of data to train models and make accurate predictions. However, the quality and relevance of the data used for training greatly impact the performance of machine learning models.
Localized machine learning training refers to the process of training models using data that is specific to a particular region or market. This approach recognizes that data collected from one region may not be representative or relevant to another region. For example, a machine learning model trained on data from the United States may not perform as well when applied to a different country with different cultural, economic, or social factors.
Automated localized machine learning training addresses this challenge by providing tools and platforms that enable businesses to automatically collect, process, and train models using localized data. These platforms leverage advanced techniques such as natural language processing, image recognition, and sentiment analysis to extract relevant information from localized data sources.
One of the key drivers of the market for automated localized machine learning training is the increasing demand for personalized customer experiences. Businesses are striving to tailor their products and services to meet the specific needs and preferences of customers in different regions. By training machine learning models on localized data, companies can gain insights into regional trends, preferences, and behaviors, allowing them to deliver more personalized and targeted experiences.
Another factor driving the market is the need for regulatory compliance. Many countries have stringent data protection laws that restrict the transfer of personal data across borders. Automated localized machine learning training enables businesses to comply with these regulations by training models using data that remains within the boundaries of a specific region or country.
Furthermore, the market for automated localized machine learning training is fueled by the increasing availability of localized data sources. With the proliferation of smartphones, social media, and other digital platforms, vast amounts of localized data are being generated every day. This data can be harnessed to train machine learning models and uncover valuable insights that can drive business growth.
Several companies are already capitalizing on this market opportunity by offering automated localized machine learning training solutions. These companies provide platforms that enable businesses to easily collect, process, and train models using localized data. They offer a range of features such as data extraction, data cleaning, model training, and performance evaluation, making it easier for businesses to leverage localized data for their machine learning initiatives.
In conclusion, the market for automated localized machine learning training is experiencing significant growth as businesses recognize the importance of leveraging localized data to improve their machine learning models. This market offers numerous opportunities for companies to enhance their predictive analytics capabilities, deliver personalized customer experiences, and comply with regulatory requirements. As the availability of localized data continues to increase, the demand for automated localized machine learning training solutions is expected to rise, driving further innovation in this space.
The Microsoft Technology Licensing LLC invention works as follows
The technique includes applying a machine-learning model to physical sensor data to detect events instances, such as applying a model to the sensor data of a physical sensor to detect the event instance. It also includes determining whether a performance parameter for the use of a model that is not within a desired parameter, getting second sensor information from a physical sensor to the same location, and obtaining third data.
Background for Automated localized Machine Learning Training
Machine Learning (ML) technology has improved the ability to recognize events coming from many different sources. The computing devices’ ability to recognize events has been significantly improved by the implementation of ML. These technologies, which are more often associated with cloud implementations, have also found their way to self-contained sensors, such as low power Internet of Things devices. The devices may include sensors that can capture data from different types of modalities. These devices can also contain ML models to help with the event recognition.
However such devices may be placed in environments or undergo changes in their environment where the effectiveness of an ML model is reduced. It can also be difficult to both identify such situations (especially in situations where the changes are intermittent) and obtain a more effective ML model. To establish more reliable ML Models in these situations and others, it is important to develop an improved ML training process.
A system for generating a ML model from sensor data to detect events is disclosed. The system comprises a physical sensor in a location at first, a second sensor in the same location at second, and an ML component configured to detect events based upon sensor data acquired from the physical sensor in the location at first.
In another implementation, a technique for generating ML models to detect event instances using physical sensor data has been disclosed. At a given location, the method involves operating a device that includes a physical sensor, and an ML component for event detection. The ML component is configured to use a ML model to detect events based on the sensor data from the physical sensor. The method also includes receiving first sensor data from the first physical device at the ML component and applying the 1st ML model at the ML component to detect a 1st event based at least on the first sensor data, and generating corresponding data for the first event instance. The method also includes calculating a performance metric based at least on the application of the ML first model in the location and automatically determining if the performance metric does not fall within an expected parameter. After determining that the performance metric of the first ML model is not within an expected parameter, the method includes obtaining second data obtained from a different physical sensor in the first location, during a period of first time. The second sensor is also different from the sensor of the first sensor. The method also includes a second ML training model that is based at least on the first location-specific data and reconfiguring the ML components to use the second ML instead of the original ML.
This Summary is intended to present a number of concepts that will be further explained in the detailed description. This Summary does not aim to identify the key features or essential elements of the subject matter claimed, nor to limit its scope. The claimed subject matter does not limit itself to solutions that address all or some of the disadvantages mentioned in this disclosure.
In the detailed description that follows, many specific details will be presented as examples to help you understand the teachings. It should be clear that the teachings can be applied without these details. In some cases, well-known methods, procedures or components have been described in a high level, without details, to avoid obscuring the teachings. The following material contains indications of directions, such as “top” or “left.” In the following material, indications of direction such as?top? The terms?right’ or?left’ are used to frame the discussion and not to specify a desired, required, or intended orientation for the articles described.
As noted above, using low-cost sensors to identify events of interest and individual instances of these events is fraught with challenges. Physical sensor data (or ?sensor data?) Physical sensor data (or?sensor data?) can be obtained by using any type of physical sensors that measure the occurrence or degree of physical phenomena, and provide information about such measurements. Low-cost sensors are generally thought to produce less reliable data or of lower quality than high-cost ones. A ‘low-cost sensor’ is used in this description. A ‘low-cost sensor’ or a?economical one? Refers to a sensor that is able to be used with a lower power consumption, generates less heat, has less maintenance requirements, doesn’t require any specific operating conditions, or produces sensor data which requires less processing. The high-cost sensors can be a different type of sensor or the same type as the low cost sensor. The high-cost sensors can have a different data type, or they can be the same data type. In some implementations a single sensor can be operated selectively as a high-cost or low-cost sensor. For example, the sensor could be operated selectively in low fidelity mode or high quality, or more energy-intensive high fidelity mode or high quality.
A’sensor type’ is used in this disclosure. Refers to the modality in which a sensor is designed to work and/or to receive or detect data. Some broad modalities include, but aren’t limited to: audio, light and haptic; flow rate, distance; pressure; motion; chemical, barometric or humidity measurements. There are many different sensor types and modalities within each of these broad modalities. Also, there are a variety of sensor data types that reflect sensor measurements. For example, light includes visible (for instance, RGB), infrared, ultraviolet, and other subsets possible of the electromagnetic spectrum. Audio modality includes all sound frequencies, both audible as well as inaudible. The haptic modality also includes vibration, pressure, contact or touch data.
For the purposes of this disclosure “device” can include one or more separate hardware units at a single location. One or more hardware units may be located at one location, each powered separately. A sensor device, for example, could be implemented as two separate units. One unit would include a low cost physical sensor, along with a wireless or wired communication unit, and battery. The second unit is configured to receive sensor data from the other unit and to apply a machine-learning model to that data. These embodiments can be used to further exploit the benefits of using a low cost sensor. When a sensor is in a separate device, the power requirements are low enough that it can be powered for a long time by a battery. This may make installation and use easier. A machine can be used to describe a device.
As noted above, consumers are generally interested in reducing the cost of initial purchase and/or operation of the sensor they choose. These low-cost sensors, however, may not deliver the desired results. In some cases, an individual may want to collect or capture data on specific targets at a particular location. Low-cost sensors might not be sophisticated enough or have a high resolution to detect target information accurately. As noted above, the use and/or purchase of a high cost sensor may have several disadvantages. The retailer might need to install the sensor in an area that has increased ventilation, to prevent overheating. It may also be too large for the retail space, or obstruct a part of the storefront.
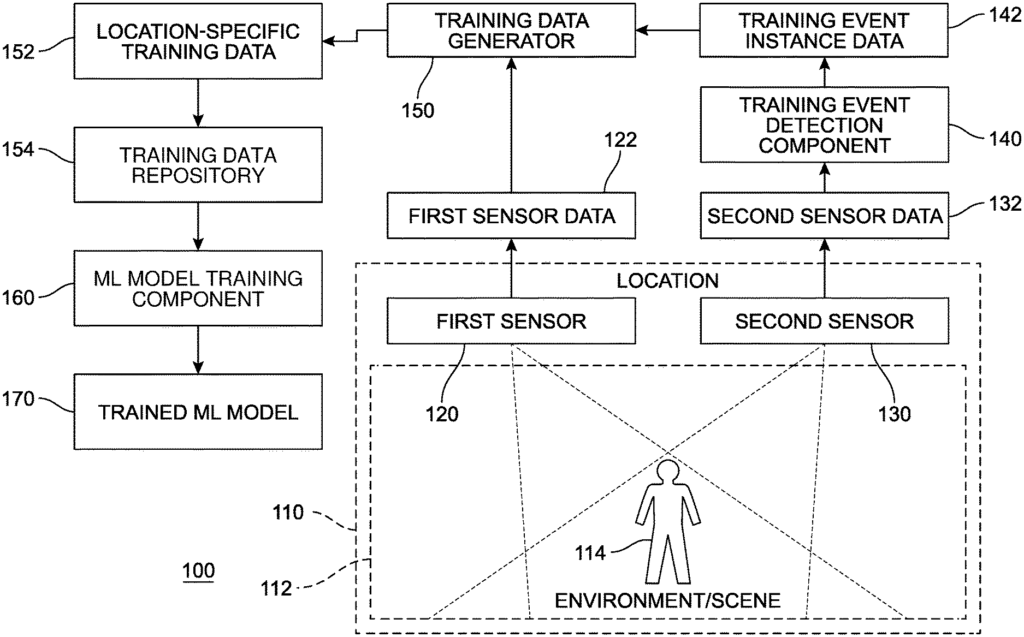
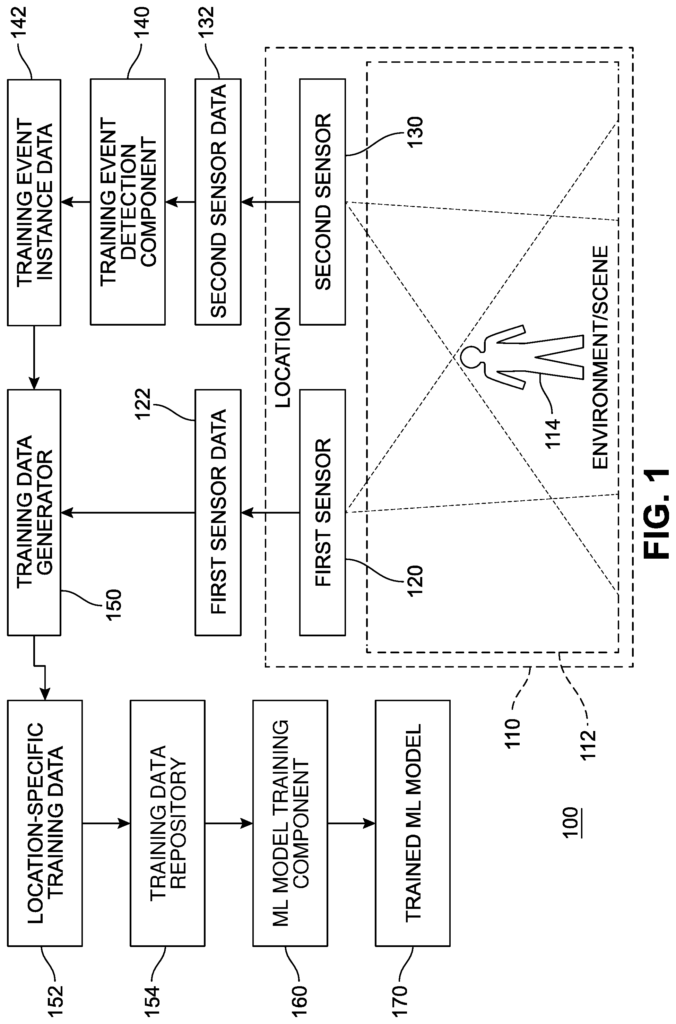
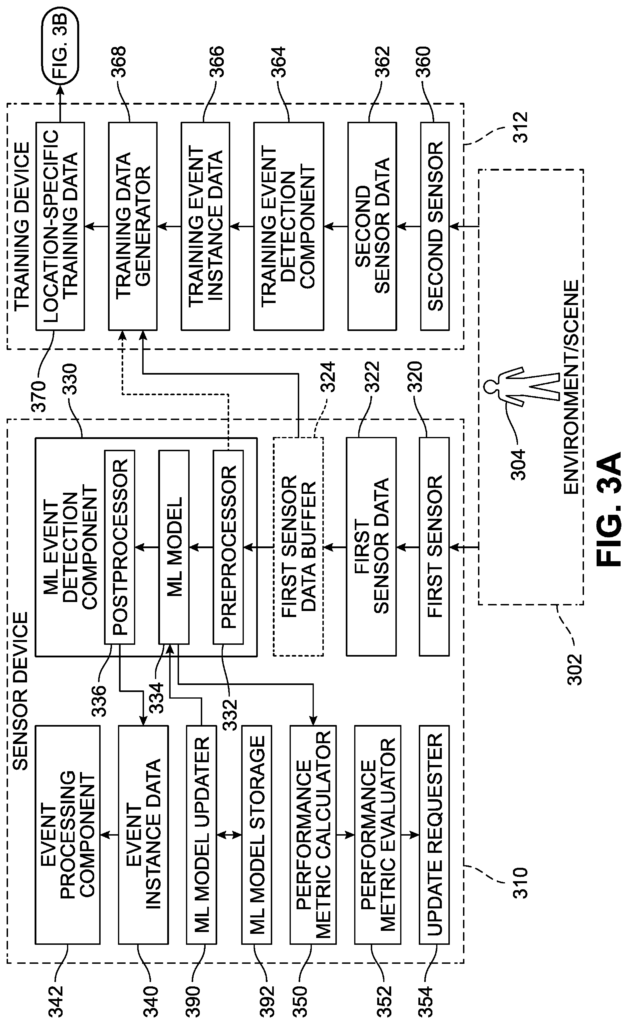
FIG. The FIG. 1 shows an example of a system 100 that generates a machine-learning (ML) model for detecting events using a type of sensor data 122 obtained from a physical sensor 120, with the help of a physical sensor 130 to generate location-specific data 152. The resulting trained ML models 170 can be used to detect events based on sensor information obtained from the first sensor 120, without using the second sensor 130.
The first physical sensors 120 are positioned at a location 110, arranged to measure an environment 112. Based on the measurements performed, they generate first sensor data 122. Scene 112 is another name for the environment 112. In certain measurements made by the first physical sensors 120, the subject 114 in the environment 112 can affect and be recorded on corresponding portions of first sensor data 122. The first sensor 120 can be configured to collect new samples according to a predetermined sampling rate. The second physical sensors 130 and 140 are also located in the location 110. They are arranged to measure the environment 112. Based on these measurements, they generate second sensor data 132. In certain measurements made by the first physical sensors 120, the subject 114 in the environment 112 can affect the first sensor data and be recorded. In various examples, either the first physical sens 120 or second physical sensors 130 can be an IR or RGB camera, a mic array, or another type of sensor that detects physical phenomena. In some implementations the first and second physical sensors 120 and 130 are different sensor types to support different modalities. For example, in one implementation, the first sensor 120 is a microphone, and the second sensor 130 an imaging camera for detecting visual events.
In some cases, although not in all examples necessary, it may be preferred that the measurements made by the first sensor 120 be synchronized to those of the second sensor 130. This synchronization could, for example, result in a first sensor data including a group or sample captured at or near the time of, or during, the capture of the corresponding group or sample of the second data 132.
A component for detecting training events 140″ (which can also be called a “training event detection module?”) The second sensor data is received, the events of interest are detected, and the training event instance data (142) corresponding to those events detected. In some cases, the component 140 for training event detection may also perform labeling on the detected event instances. Data corresponding to the resulting labels can be included in training event instance data. In some cases, the training component 140 may also generate confidence values that are associated with the detection or event instances, labels, categories and/or labels. Data corresponding to one or more confidence values can be included in training event data 142. The training event detection component may, in some cases, detect multiple simultaneous event instances within the second sensor data. This can result in multiple items of the training event instance data.
Multiple items of training event instance data can be generated when multiple samples of second sensor data are collected over time and reflect the occurrence of an incident that the component 140 for training event detection is configured to detect. If, for example, the second physical camera 130 generates the second sensor data as a sequence of images and the training events detection component 140 detects the presence of human faces, it may be possible to identify a different training event instance and produce one or more items of training instance data for each frame that includes a face.
The training data generator (which can be called a “training data generation module”) generates location-specific training data 152 by automatically selecting and labeling portions of the first sensor data 122 that correspond to respective items of training event instance data 142 identified by the Training Event Detection Component 140. The training data generator 150 generates location-specific data 152, by automatically selecting and labeling portions of first sensor data that correspond to respective items in training event instance data 142, identified by the component for detecting training events 140 (which are then identified based upon corresponding portions of second sensor data 132). Due to the latency of analyzing second sensor data to produce corresponding training data instance data 142 in some implementations the first sensor data may be buffered. The data can then be selectively retrieved based on the time when the measurements were taken by the second physical sensors 130. In some cases, the training event instance data may identify an area of interest, such as a region in the second sensor data 132, and only select a portion from the sensor data that corresponds to this region. The location-specific data 152 can be reduced in size by excluding portions of the sensor data 122 which have no or little effect on the training. This also reduces the storage space, bandwidth and computation required to handle the location-specific data 152. The location-specific data 152 can include metadata such as the time and date captured, the hardware details (such a make, model and/or resolution) and/or operational parameters (such a sample rate, exposure, or quality setting). The metadata can be used to automatically select appropriate training data portions for an ML training session.
In some implementations the training data generator may use various criteria to choose event instances that will generate location-specific data 152. A similarity between the first sensor 122 of a current instance and the first sensor 122 of a previous instance may be one such criteria. To determine whether the first sensor data for the current instance of the event is too similar to the previous first sensor, one can use techniques like fingerprinting, hashing or local feature analysis. A second such criterion is whether the training event instance data (142) indicates a low value of confidence (such as below an threshold confidence value), in which case such event instances can be excluded.
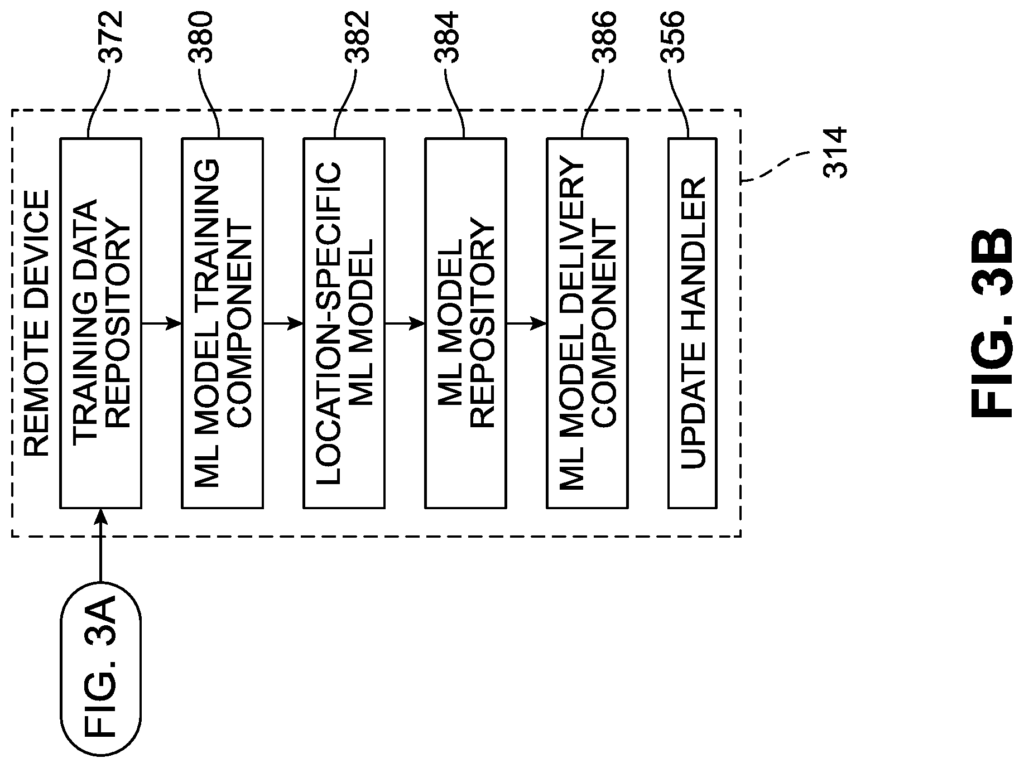
In some implementations the location-specific data 152 or selected portions of it are incorporated into a training data repository (which can be called a “training data storage module”). In some implementations the location-specific data 152 can be sent to a remote server (not shown in FIG.). The first configuration is configured to collect and maintain cross-location data 154, as well as location-specific data 152 from different locations. A more generalized ML model may be created by collecting data from different locations. In some implementations various criteria can be used to selectively incorporate items of location-specific data 152 into the training data repository or remove training data items. “Age and/or the number of training data objects that are similar or related in the repository of training data 154 can affect the retention or incorporation of training data in the repository of training data 154.
In some implementations, training data from the remote system 154 or a portion of it may be used locally in conjunction with location-specific data 152 generated locally to create the ML model 170-. These implementations can be used to maintain the privacy of events that occur at the location 110 while using data from other locations in order to improve the robustness and generalization of the ML Model 170.
A ML model component training 160 (which can be referred as an ‘ML model module? The ML model training component 160 (which may also be referred to as an?ML model training module?) is configured to create a trained ML from location-specific data 152 or training data items obtained through the training data repository. In some implementations the training can be done remotely from the location 100. For example, on a cloud computing platform that offers substantial resources for training. In some implementations the training can be done locally or in a private network. This is helpful for maintaining the privacy of the events that occur at the location. In some implementations the ML component 160 can be configured to generate different ML models based on the same or similar data. Different ML algorithms, including but not limited, to decision trees, random decisions forests, neural networks (for instance, convolutional networks), support vectors machines, and regression (for instance, support vector regressions, Bayesian linear models, or Gaussian processes regressions) may be trained. Another example is to vary the size or complexity of models between different ML algorithms. For instance, you can change the maximum depth of decision trees or increase or decrease the number of hidden layers of a convolutional network. For example, different approaches to training different ML model may be used. These include, but are not limited, the selection of training, test, and validation sets of data, weighting and/or ordering of data items in training, or number of iterations. The selection of one or more trained ML models can be based on factors like accuracy, computation efficiency and/or energy efficiency. In some implementations a single trained ML 170 model may be produced.
The U.S. Patent Application Publication Numbers 2013,0346346, entitled “Semi Supervised Random Decision Forests in Machine Learning”, was published on December 26, 2013. “Various ML algorithms and techniques for training ML models are discussed in U.S. Patent Application Publication Numbers 2013/0346346 (published on Dec. 26, 2013 and entitled “Semi-Supervised Random Decision Forests for Machine Learning?”), 2014/0122381 (“Decision Tree Training In Machine Learning?”), published on May 1, 2014. 2014/0172753, published on June 19, 2014. Resource Allocation for Machine Learning (published on Jun. Published on Sep. 3, 2015. Titled ‘Depth Sensing using an Infrared camera? 2015/0248765, (published on Sep.3, 2015 and entitled “Depth Sensing using an RGB Camera?” 2017/0132496, published on May 11, 2017, and entitled “Hardware-Efficient Convolutional Deep Neural Networks” 2017/0206431, published on July. Object Detection in Images? Published on August 17, 2017, 2017/0236286 is entitled “Determining depth from structured light using trained classifiers?” The following publications are incorporated by reference herein in their entirety: 2017/0236286 (published on Aug. 17, 2017 and entitled “Determining Depth from Structured Light Using Trained Classifiers? “These publications are hereby incorporated in their entirety by reference.
Click here to view the patent on Google Patents.
Leave a Reply