Invented by Daniel Sung-Joon Park, Quoc Le, William Chan, Ekin Dogus Cubuk, Barret Zoph, Yu Zhang, Chung-Cheng Chiu, Google LLC
One of the key areas where augmentation and machine learning of audiographic images are making a significant impact is in the entertainment industry. Augmented reality (AR) and virtual reality (VR) technologies are becoming increasingly popular, allowing users to experience movies, games, and other forms of entertainment in a whole new way. By augmenting audio and visual elements, these technologies can transport users to virtual worlds, enhancing their overall experience.
For example, imagine watching a movie in VR where the audio is spatially enhanced, giving you the feeling of being right in the middle of the action. Machine learning algorithms can analyze the audio and video data to identify key elements and enhance them, creating a more immersive and realistic experience. This technology has the potential to revolutionize the way we consume entertainment, making it more engaging and interactive.
Another area where augmentation and machine learning of audiographic images are making waves is in the field of education. Traditional learning methods often rely on static images and text, which can be limiting for some learners. However, by augmenting these images with audio and interactive elements, educators can create a more engaging and dynamic learning experience.
For instance, imagine studying anatomy using augmented reality. Instead of looking at static images in a textbook, students can use AR technology to explore 3D models of the human body. By adding audio explanations and interactive quizzes, students can learn in a more immersive and interactive way, improving their understanding and retention of the subject matter.
The market for augmentation and machine learning of audiographic images is not limited to entertainment and education. It has applications in various industries, including healthcare, marketing, and design. In healthcare, for example, surgeons can use augmented reality to overlay medical images onto a patient’s body during surgery, providing real-time guidance and improving precision. In marketing, companies can use augmented reality to create interactive and personalized advertisements, enhancing customer engagement. In design, architects can use augmented reality to visualize their designs in real-world environments, helping them make more informed decisions.
As the demand for immersive and interactive experiences continues to grow, so does the market for augmentation and machine learning of audiographic images. Companies specializing in these technologies are constantly innovating and developing new applications to meet the needs of various industries. Additionally, advancements in hardware, such as more powerful smartphones and VR headsets, are making these technologies more accessible to a wider audience.
In conclusion, the market for augmentation and machine learning of audiographic images is expanding rapidly, transforming the way we consume entertainment, learn, and interact with various industries. The combination of augmentation and machine learning has the potential to create immersive and interactive experiences that were previously unimaginable. As technology continues to advance, we can expect to see even more innovative applications and advancements in this field.
The Google LLC invention works as follows
In general, the present disclosure is directed at systems and methods which generate augmented data for machine-learned model via application of one augmentation technique to audiographic images visually representing audio signals. The present disclosure, in particular, provides novel augmentation operations that can be performed directly on the audiographic image, instead of the raw audio data, to generate augmented data for improved model performance. The audiographic images may include or be one or more filter banks or spectrograms.
Background for Augmentation and machine learning of audiographic images
Deep learning and machine learning techniques have been applied successfully to ASR (automatic speech recognition) as well as other audio signal processing problems, such as those involving human speech. In this area, the research has mainly focused on designing better network structures, such as improved neural networks and models that span end-to-end. These models are prone to overfitting and require a large amount of training data.
Data augmentation is a widely accepted method for generating additional training data to be used by various machine-learning systems. Data augmentation techniques exist in audio processing that perform data augmentation on the raw audio data which encodes the audio signals. One existing technique involves adding noise to the signal. However, augmentation methods that use raw audio data suffer from a variety of disadvantages. One is their computational slowness and difficulty in implementation. Another example of a drawback is that certain techniques (such as adding noise to the audio data) require additional data sources. These and other reasons are why existing raw audio augmentation methods are usually performed offline in advance of model training activities.
Aspects, and benefits of embodiments of this disclosure will be described in part.
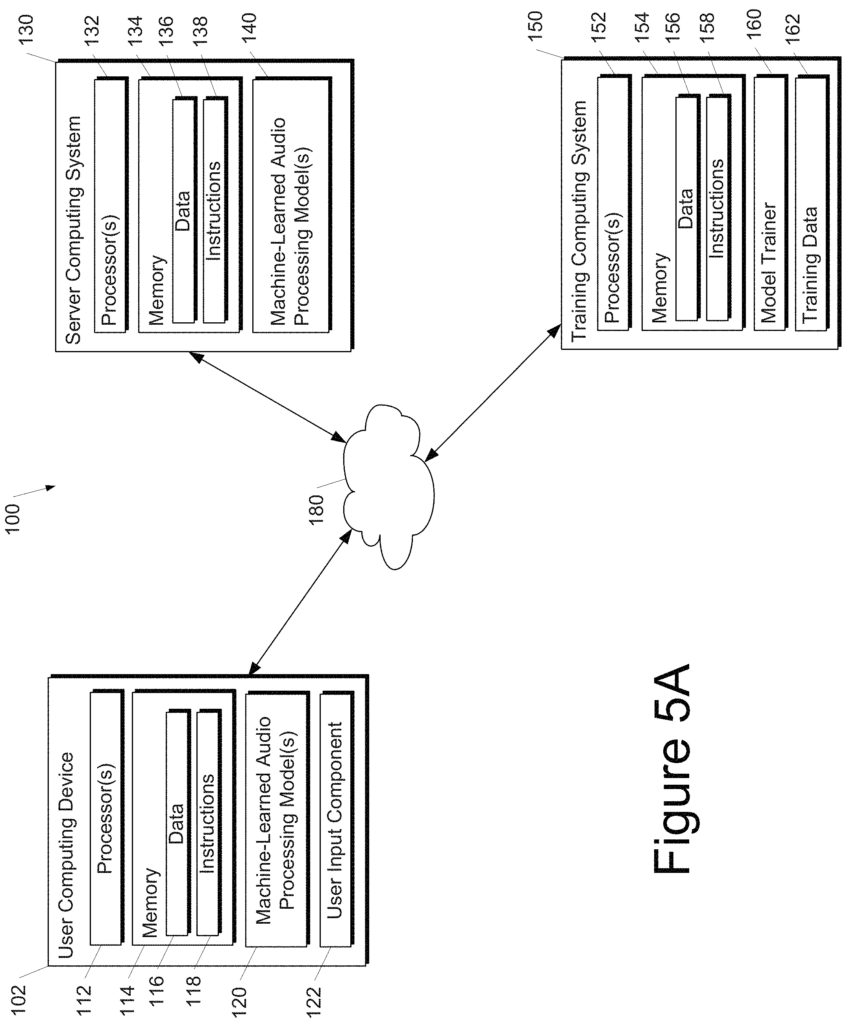
One example of the present disclosure is a computer-implemented technique to generate enhanced training data. One or more computing devices are used to obtain one or multiple audiographic images which visually represent one audio signal or several audio signals. The method involves performing one or multiple augmentation operations by one or several computing devices on each of the audiographic images in order to produce one or many augmented images. The method involves incorporating, by one or multiple computing devices, one or more augmented image into a machine learned audio processing model. The method involves receiving, by one or multiple computing devices, the one- or more predictions generated by the machine learned audio processing model on the basis of the one- or more augmented pictures. The method involves evaluating an objective function by one or multiple computing devices that scores the predictions generated by the machine-learned model. The method involves modifying the values of one or multiple parameters of the machine-learned model of audio processing based on an objective function by one or more computing devices.
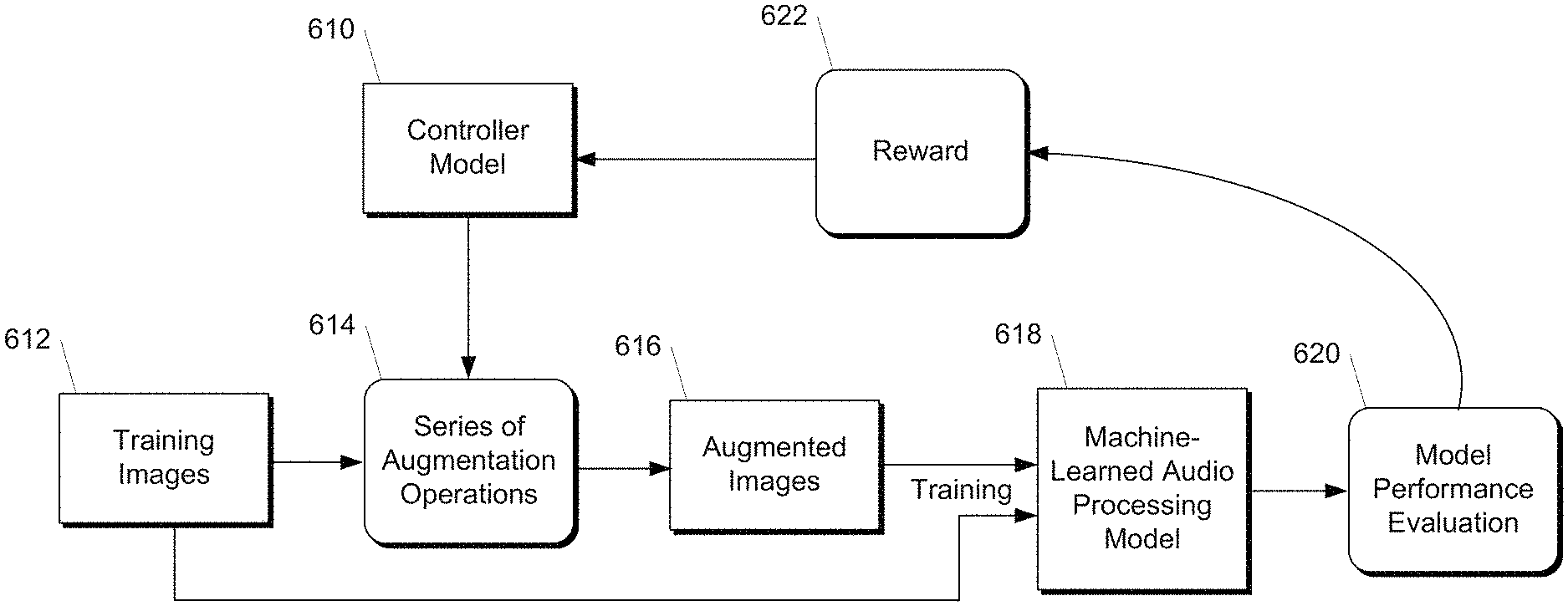
Another aspect of the disclosure is directed at a computing system.” The computing system comprises one or multiple processors, a controller model, and one or several non-transitory computers-readable media which collectively store instructions, which, when executed by one or many processors, cause it to perform operations. The operations include gaining access to a training dataset, which comprises a plurality training images. Each training image is an audiographic image visually representing an audio signal. For each iteration, the operations include: selecting by the controller model a series one or two augmentation operations, performing the series one or two augmentations on each one or several training images in order to generate one of more augmented pictures, and training an audio processing machine model at least partially based on the augmented images. After training the machine learned audio processing model, the operations include evaluating the performance characteristics of the model.
Another aspect of the present disclosure is directed to various systems and apparatuses, nontransitory computer-readable mediums, user interfaces, electronic devices, and other systems.
These and other features, aspects and benefits of different embodiments of this disclosure will be better understood if you refer to the following description. These accompanying drawings are included in and form a part this specification and illustrate examples of the present disclosure. They also serve to explain related principles.
Overview
In general, the present disclosure is directed at systems and methods which generate augmented data for machine-learned model via application of one augmentation technique to audiographic images visually representing audio signals. The present disclosure, in particular, provides novel augmentation operations that can be performed directly on the audiographic image, instead of the raw audio data, to generate augmented data for improved model performance. Audiographic images may include or be spectrograms, filter bank sequences or other types of audiographic data. The present disclosure includes systems and methods that can be used by any machine-learning system that predicts an audio signal from an input, which at least partially includes an audiographic picture that visually represents that audio signal. The augmentation techniques described in this document can be used to enhance neural networks (e.g. end-to-end network) that are configured to perform automatic recognition of audio signals using their audiographic images.
The augmentation operations described in this document are easier to perform and less costly computationally when they operate on audiographic images, as image processing is simpler than waveform processing. Moreover, it is not necessary to use additional data sources (e.g. sources of noise). The augmentation operations described in this document can be performed online at the time of training the model. This reduces the amount of preprocessing required to train the model. The augmentation techniques described herein also enable the learning of machine-learned state-of-the art models that outperform models trained on augmented data generated by augmentation of the audio waveform.
The following paragraphs will discuss in detail the example embodiments of this disclosure.
Example Augmentation process and machine-learned models
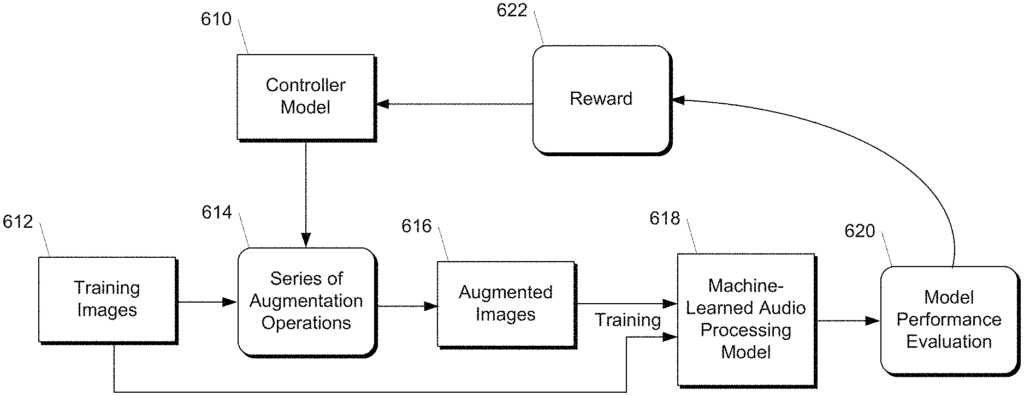
FIG. The block diagram 1 shows an example of a machine-learned audio model 16 in accordance with example embodiments. FIG. “Figure 1 illustrates an example of a scheme whereby the machine-learned model 16 for audio processing is trained by using augmented training data.
More precisely, a computer system can obtain audiographic images 10 which are visually descriptive of the audio signals. Audio signals can be included in a dataset of training audio signals for training an audio processing model 16. Audio signals include speech, musical instruments and other sounds.
As an example, audiographic images 10 could be filter bank sequences or spectrograms. Sonographs, voicegraphs, voiceprints, voicegrams and/or other visual representations for audio are all possible. In some implementations the audiographic images 10 may include multiple images that are “stacked” together, concatenated or otherwise combined. The multiple images can be stacked, concatenated or combined in other ways, depending on whether they correspond to different parts of the audio signal. In some implementations the audiographic images 10 may include a horizontal and vertical axis that are correlated to frequency. In some implementations the values of pixels in the audiographic images (e.g. color or brightness) can represent or correspond to an intensity or volume for the audio signal.
The audio signals can be included in the training dataset (e.g. raw audio signal data), and the computing system will generate the audiographic image 10 by using one or more transformations or processing techniques. The computing system could, for example, apply one or multiple frequency-based filters on the audio signals in order to produce the audiographic images. The training dataset may also include audiographic images 10, and the computing system will simply be able to access them from the memory-stored training dataset.
In certain implementations, the data set can be designed to support supervised learning. Each audio signal or audiographic image can be labeled with ground truth information that gives a “correct” prediction. In other implementations, the training dataset can be designed for unsupervised learning and each audio signal or corresponding image 10 can be unlabeled or weakly labeled. The training dataset may be designed to allow unsupervised learning, and the audio signals or audiographic images 10 can either be unlabeled (or weakly labelled) or unlabeled.
According to one aspect of the disclosure, the computing device can perform one- or more augmentation operations (12) on the audiographic images 10, to generate one- or more augmented pictures 14. The augmented images can be used to help the machine-learned model of audio processing 16 learn useful features that are resistant to time deformations, partial loss in frequency information and/or small segments of speech. In this way, augmented data can be created that can be used to improve machine-learned processing model 16. The machine-learned model 16 may be trained using a combination of augmented images 14, and the original audiographic image 10. The audiographic images 10 may include ground truth labels. This label can be applied to any augmented images 14 that are generated from the audiographic image 10.
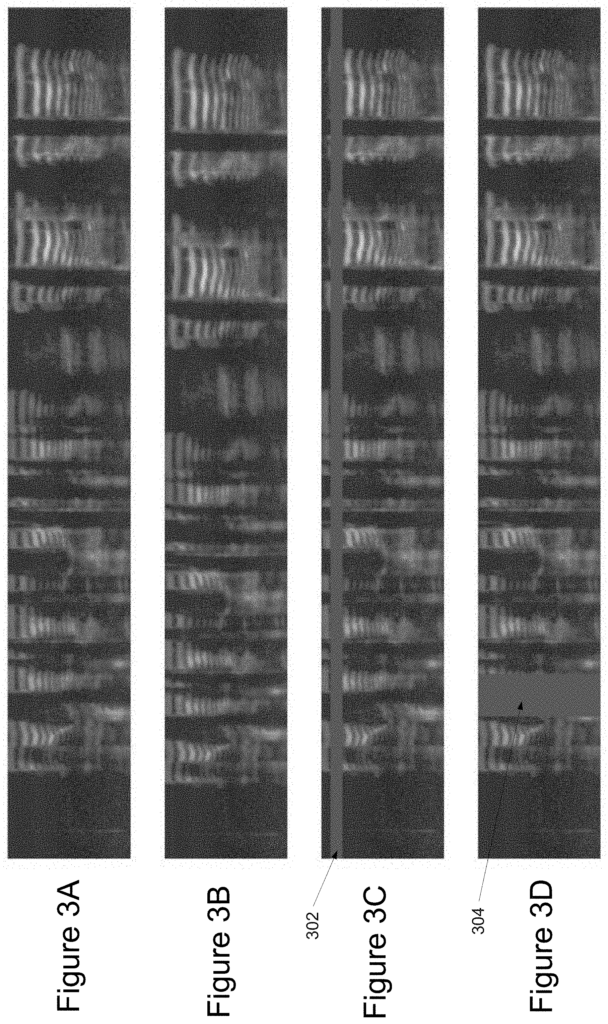
As an example of augmentation operation, one or more of the augmentation operations 12 may include a time-warping operation. The time warping operation may include, for example, warping the image content of an audiographic image along a time axis (e.g. a horizontal one). In some implementations performing the time-warping operation can include fixing the spatial dimensions of audiographic image 10, and warping the content of the image to shift the point within the content a distance on the axis representing time (e.g. such that all pixels in the audiographic are modified to accommodate such shifting).
In some implementations, time warping can be performed via the sparse_image_warp function of tensorsflow. As an example, if you have an audiographic 10 image with a horizontal time scale that represents? A vertical frequency axis and time steps are used to warp a point along a horizontal line that passes through the middle of the image (W,?-W). The point can be a user-selected, randomly selected, or learned point. Distance w may be user-specified, randomly selected, or learned. In some implementations, for example, the distance W can be selected from a uniform distribution ranging from 0 up to a timewarp parameter W. This parameter W can either be a value that is user-specified, randomly chosen, or learned.
Another example of the one or multiple augmentation operations 12 is a frequency masking. The frequency masking operation may include, for example, changing the pixel values of image content that is associated with a subset or frequencies represented by at least one audiographic picture. For example, a certain subset can include frequencies ranging from a first to a second that is separated by a distance. The distance can be either a value that is specified by the user, randomly selected, or learned. In some implementations the distance can range from zero up to a frequency parameter or attribute. The frequency mask parameter may be user-specified, randomly selected, or learned.
Click here to view the patent on Google Patents.
Leave a Reply