Invented by Marisa Affonso Vasconcelos, Carlos Henrique Cardonha, International Business Machines Corp
Bias in machine learning models can have significant consequences, particularly in areas such as hiring, lending, and criminal justice. If a model is trained on biased data, it can lead to discriminatory outcomes, reinforcing existing social inequalities. For example, if a hiring algorithm is trained on historical data that reflects gender or racial biases, it may inadvertently perpetuate those biases by favoring certain candidates over others.
To address this issue, organizations are turning to audit machine learning models that can evaluate the fairness and bias in existing algorithms. These models use various techniques to identify and quantify bias, such as measuring disparate impact, which assesses whether different groups are treated differently by the algorithm. They also analyze the data used to train the model to identify any inherent biases present in the dataset.
The market for audit machine learning models against bias is driven by both regulatory requirements and ethical considerations. In recent years, there has been a growing focus on algorithmic transparency and accountability. Regulatory bodies are increasingly demanding that organizations demonstrate fairness and transparency in their decision-making processes. Failure to comply with these regulations can result in legal and reputational consequences.
Moreover, organizations are recognizing the ethical imperative of addressing bias in machine learning models. They understand that biased algorithms can perpetuate discrimination and harm individuals and communities. By investing in audit machine learning models, organizations can ensure that their algorithms are fair, transparent, and accountable.
The market for audit machine learning models against bias is diverse, with various players offering different solutions. Some companies specialize in developing proprietary algorithms that can identify and mitigate bias in machine learning models. These models are often customizable to suit the specific needs of different organizations and can be integrated into existing systems seamlessly.
Other players in the market focus on providing consulting services to organizations, helping them identify and address bias in their algorithms. These consulting firms often have expertise in both machine learning and ethics, allowing them to provide comprehensive solutions to their clients.
As the market for audit machine learning models against bias continues to grow, it is expected that there will be increased collaboration between organizations, regulators, and researchers. This collaboration is essential to develop standardized frameworks and best practices for auditing machine learning models. It will also facilitate knowledge sharing and the development of more sophisticated and accurate audit models.
In conclusion, the market for audit machine learning models against bias is expanding rapidly as organizations recognize the importance of fair and unbiased decision-making. By investing in these models, organizations can ensure that their algorithms do not perpetuate discrimination and harm. As regulatory requirements and ethical considerations continue to evolve, the demand for audit machine learning models is only expected to increase, driving innovation and collaboration in this emerging field.
The International Business Machines Corp invention works as follows
A method and a system for mitigating biased in a decision making system are provided.” One or more machine-learning models are identified as having bias. The presence of bias is determined for each machine learning model. Based on the presence of bias identified for each model, one or more options are selected to mitigate the system bias at a post-processing stage. Based on the presence of bias identified in the outputs of the models, one or more options are determined to mitigate system bias at a post-processing phase. The combination of options includes (i) processing options for the processing stage and (ii), post-processing options for the postprocessing stage.
Background for Audit Machine Learning Models against Bias
Technical Field
The present disclosure relates generally to artificial intelligence and, more specifically, to evaluating machine-learning models for bias.
Description of Related Art
In recent years, machine-learning models have been used in a growing number of fields, including recommendation engines, predictive models for autonomous self-driving vehicles, etc. These models can be used to make different inferences. For example, they are used to determine the likelihood of someone being a criminal. They also use them for assessing credit scores, assessing health, and determining employability. Most machine learning models are not fully interpretable because they act as black-box algorithms, whose behavior is unpredictable. Even in the absence intent, the automated decisions generated by machine learning models may lead to an unfairness where outcomes can be disproportionately beneficial or harmful for different groups of people who share one or more attributes. The trained classification systems are therefore subject to bias.
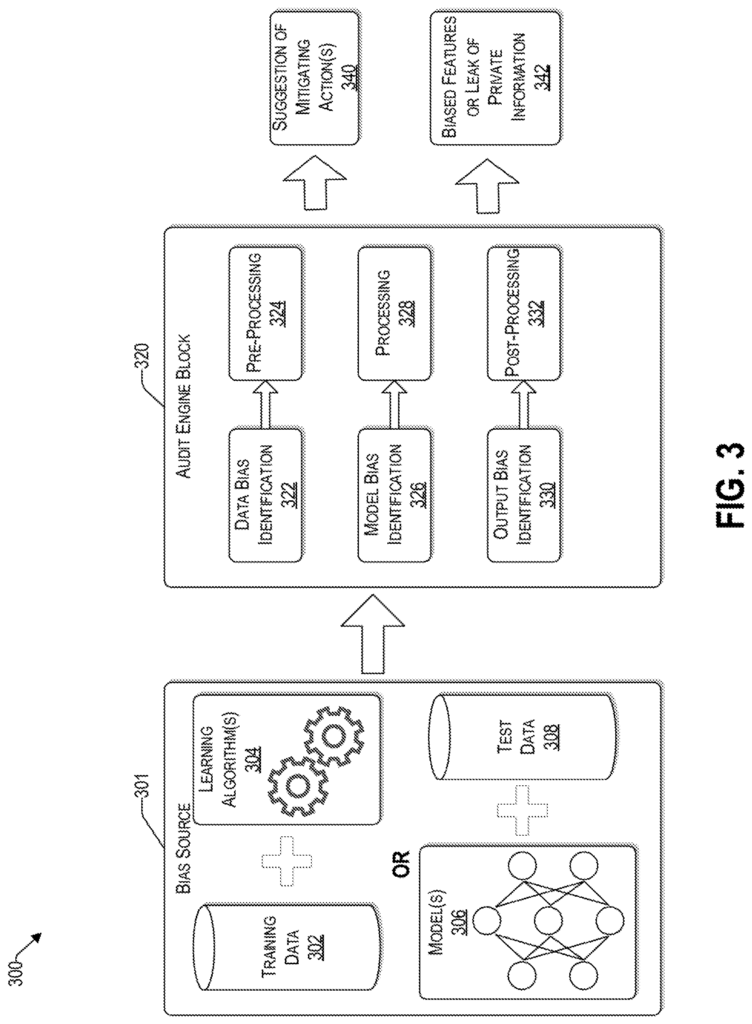
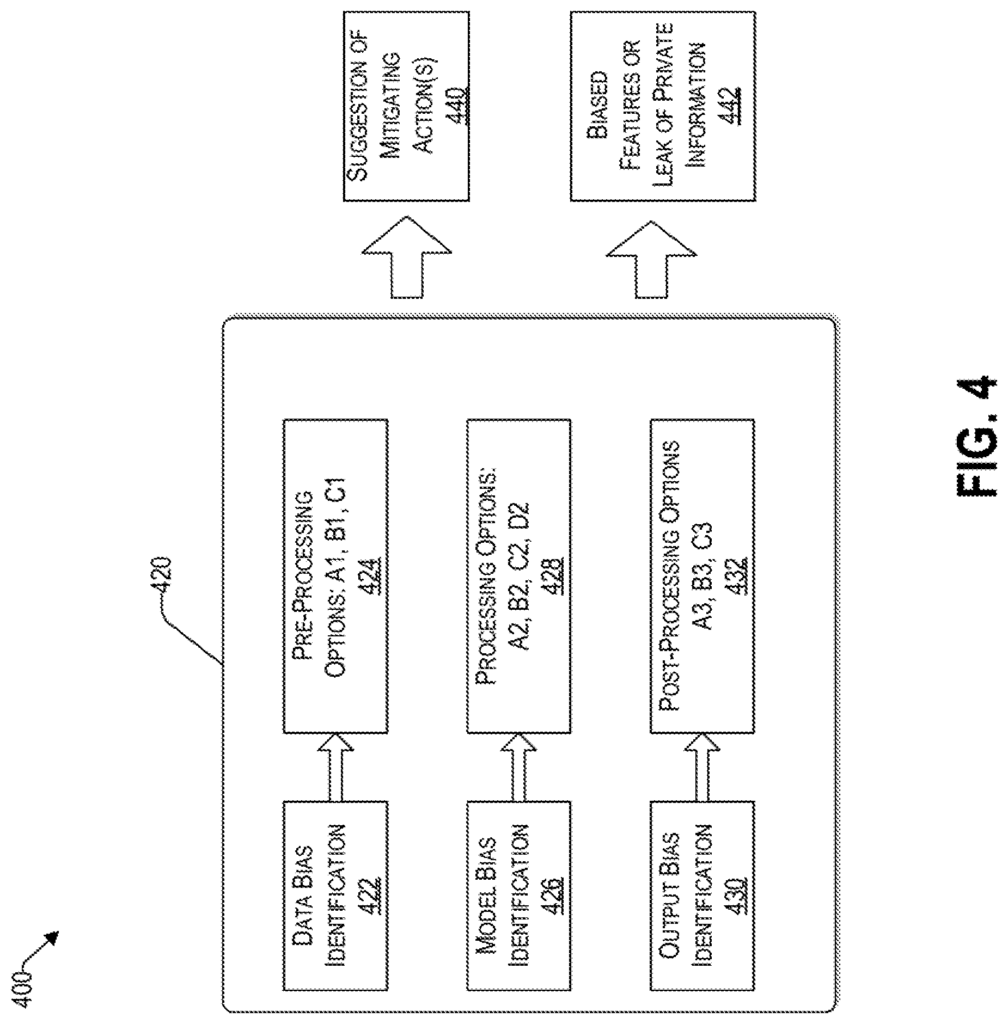
According to different exemplary embodiments of the invention, a computing system, a nontransitory computer-readable storage medium and a method for mitigating bias in a decisions-making system are provided. The presence of bias is detected in one or more of the machine learning models. The presence of bias is determined for each of the aforementioned machine learning models. Based on the presence of bias identified for each of the machine learning models during the processing stage, one or more options are determined to mitigate the system bias. Based on the presence of bias identified in the outputs of the machine learning models, one or more options are determined to mitigate system bias at a post-processing phase. The combination of options includes (i) a processing option selected from one or multiple options to reduce the system bias in the processing phase, (ii), a post-processing solution selected from one or several options to reduce the system bias in the postprocessing phase. The combination of options includes a threshold bias limitation to the system bias, and a total cost of bias mitigation of the decision-making systems.
In one embodiment, bias is detected in the training data for a decision-making system.
In one embodiment, the models are based on training data.
In one embodiment, the presence of bias is determined in the training data and one or more options are selected to mitigate the bias.
In one embodiment, the combination includes at least one option to reduce the bias of the system during the preprocessing phase.
In one embodiment, a total bias mitigation threshold is determined by (i) the computing resources, (ii), the time, (iii), the energy, or (iv), the monetary cost of the options.
In one embodiment, each stage of processing and post-processing has a different kind of bias mitigation costs.
In one embodiment, a factor of equalization is applied to each type of cost in the processing phase to get a cost universal for the options of the stage. The equalization factor of the postprocessing stage is used to determine the universal cost for each option. The decision-making system’s total bias mitigation cost threshold is based on the total universal cost of both the chosen processing option of the processing stage and the chosen post-processing options of the post-processing stages.
In one embodiment, one of more sensitive attributes that are used in the system for decision-making is identified and reported either as (i) a biased feature or (ii), a leakage of private information.
The following detailed description, in conjunction with the accompanying illustrations, will reveal these and other features.
Overview
In the detailed description that follows, many specific details will be presented as examples to help you understand the teachings. It should be clear that the teachings can be applied without these details. Other times, well-known components, methods, or circuitry has been described in a high-level manner, without much detail, to avoid obscuring the current teachings.
The present disclosure relates generally to artificial intelligence and, more specifically, to evaluating biased classification systems (also referred to as decision-making system herein) that have been trained. Machine learning models are used in many fields today for decision-making. Even though decision-making systems that use machine learning models are not designed to create a disparate treatment or impact, which is sometimes collectively called bias, they can still produce unfair results. These machine learning models, for example, may inherit any bias and discrimination that is present in the data they are trained on.
An automated system that makes decisions is treated unfairly if it bases its decisions at least partly on sensitive attributes. It also has a disparate impact when its outcomes affect people in disproportionately negative or positive ways, based on their sensitive attributes (e.g. gender, race, ethnicity and nationality, disability status, age etc.). A machine-learning model may correlate race with financial credit scores in a scenario, when such correlation is not appropriate (i.e. the credit scoring system shouldn’t be aware of the element race). Direct or indirect discrimination is possible. Direct discrimination is when decisions are based on sensitive characteristics. Direct discrimination occurs when decisions based on sensitive attributes are strongly correlated to non-sensitive ones.
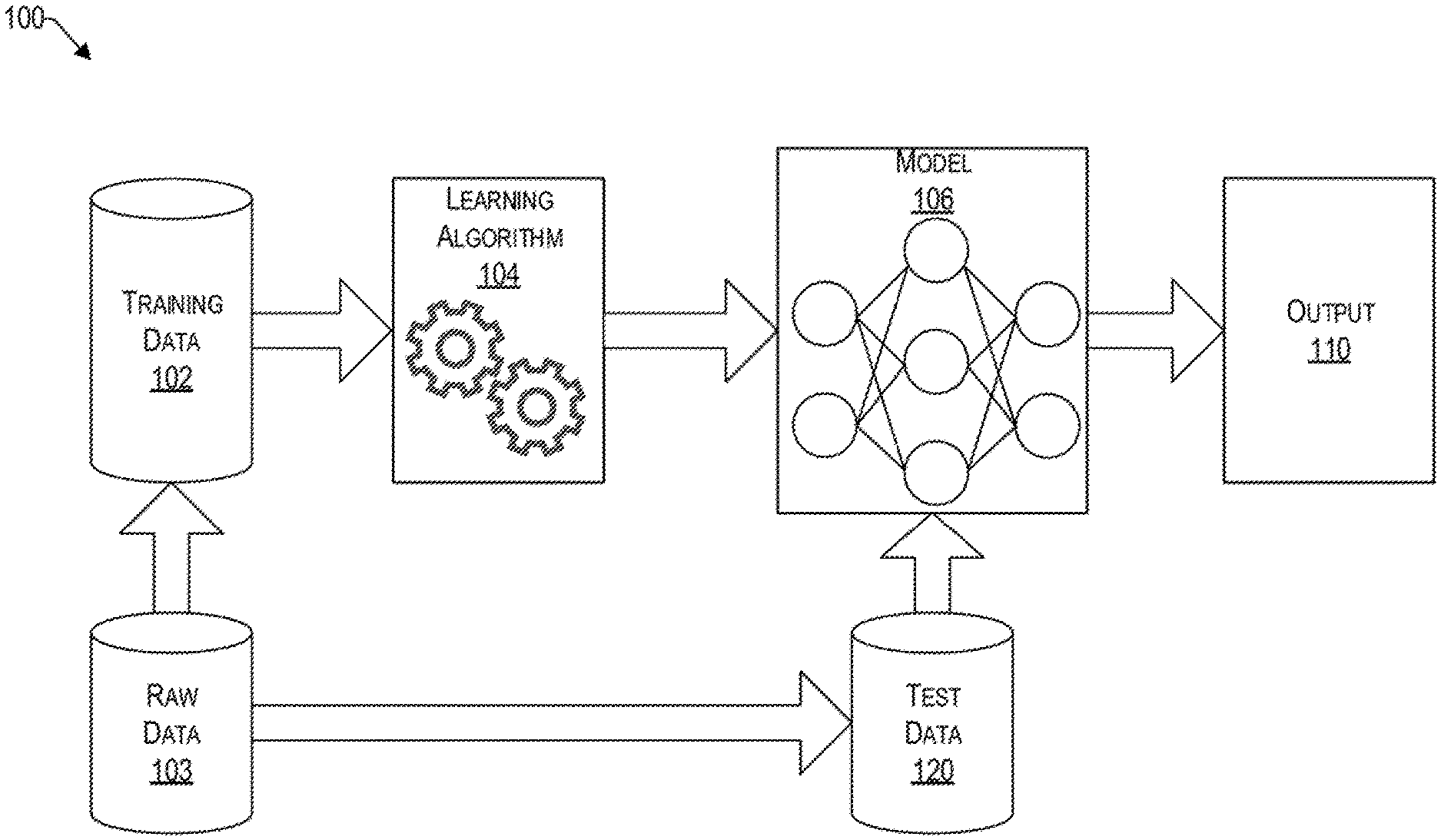
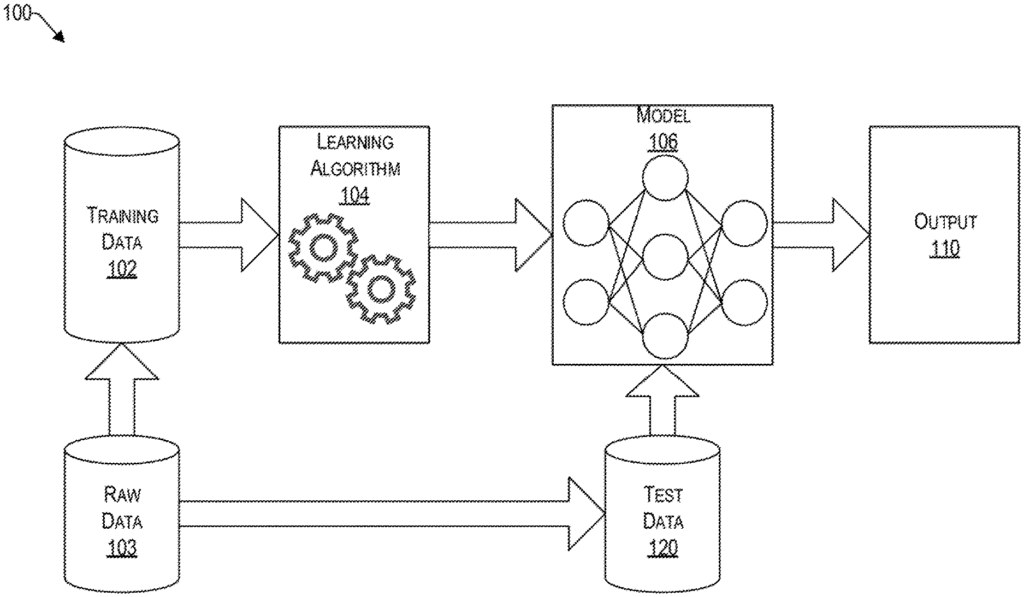
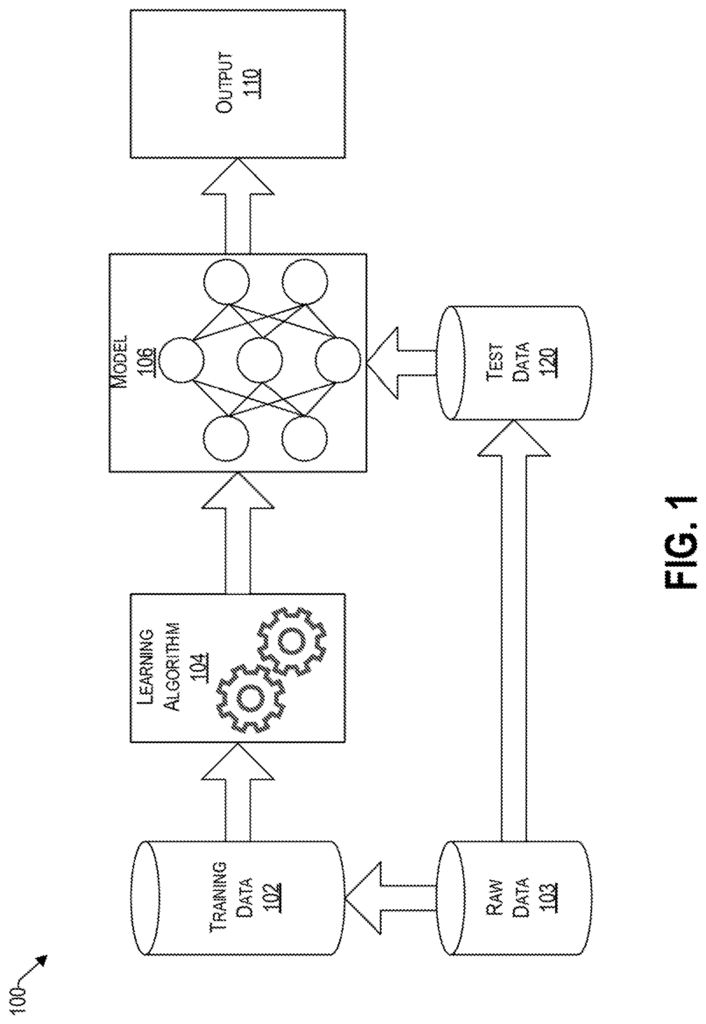
FIG. The FIG. 1 shows various components of a system 100 that uses machine learning for classification and/or decision-making, in accordance with an example embodiment. The machine learning system is configured to use algorithms that can make predictions and/or learn from a corpus 102 of training data provided, based upon raw data 103. These learning algorithms 104 work by creating a model 106 based on stored inputs and baselines, in order to make data driven predictions or decisions rather than strictly static criteria.
The machine learning described herein can be either supervised or non-supervised. In supervised learning the algorithm can be taught using example threshold condition training data 102. In other words, the data used for training acts as a guide to the algorithm. The training data 102 is not used in unsupervised learning to label what is acceptable. Instead, it provides historical data that the algorithm 104 can use to determine its own structure from the data 102 and create a model. The model 106 can then be used to generate an output 110, such as Yes or No (scale 1 to N), etc. To later classify the test data 120 presented to model 106.
The system 100 is affected by algorithmic discrimination from three sources: the input 110, the learning algorithm 104 (which may be corrected in the processing stage), and the training data 102. This is why algorithmic discrimination prevention is a matter of modifying these three sources and perhaps others to make sure that the model 106 makes decisions without bias.
Click here to view the patent on Google Patents.
Leave a Reply