Invented by Bin Qin, Farooq Azam, Denis Malov, SAP SE
Parallel development and deployment of machine learning models refer to the process of building and deploying multiple models simultaneously. This approach allows businesses to experiment with different algorithms, architectures, and hyperparameters to find the most optimal solution. It also enables faster model training and deployment, reducing the time and resources required to bring AI solutions to market.
One of the key drivers behind the market growth is the increasing availability of data. With the proliferation of digital technologies, businesses have access to vast amounts of data that can be used to train machine learning models. Parallel development and deployment allow organizations to leverage this data effectively and build robust models that can provide valuable insights and predictions.
Another factor contributing to the market growth is the advancements in cloud computing and distributed computing technologies. Cloud platforms provide the necessary infrastructure and resources to train and deploy machine learning models at scale. Parallel processing capabilities enable businesses to distribute the workload across multiple machines or nodes, significantly reducing the training time and improving efficiency.
The market for parallel development and deployment of machine learning models is also driven by the need for real-time decision-making. In industries such as finance, healthcare, and e-commerce, businesses require models that can process and analyze data in real-time to make accurate predictions and recommendations. Parallel development and deployment enable organizations to build and deploy models that can handle large volumes of data and provide real-time insights.
Furthermore, the market growth is fueled by the increasing adoption of AI across various sectors. From healthcare to manufacturing, businesses are recognizing the potential of AI in improving efficiency, reducing costs, and enhancing customer experiences. Parallel development and deployment of machine learning models enable organizations to harness the power of AI and unlock its full potential.
However, the market for parallel development and deployment of machine learning models also faces challenges. One of the main challenges is the complexity of managing multiple models simultaneously. Organizations need to have robust infrastructure, skilled data scientists, and efficient processes in place to handle the parallel development and deployment of models effectively.
Moreover, ensuring the quality and accuracy of the models is crucial. With parallel development, there is a risk of overlooking potential issues or biases in the models. Organizations need to implement rigorous testing and validation processes to ensure that the models are reliable and unbiased.
In conclusion, the market for parallel development and deployment of machine learning models is experiencing significant growth due to the increasing demand for AI solutions, advancements in cloud computing, and the need for real-time decision-making. While there are challenges to overcome, businesses that can effectively leverage parallel development and deployment can gain a competitive advantage by building robust models and delivering valuable insights and predictions.
The SAP SE invention works as follows
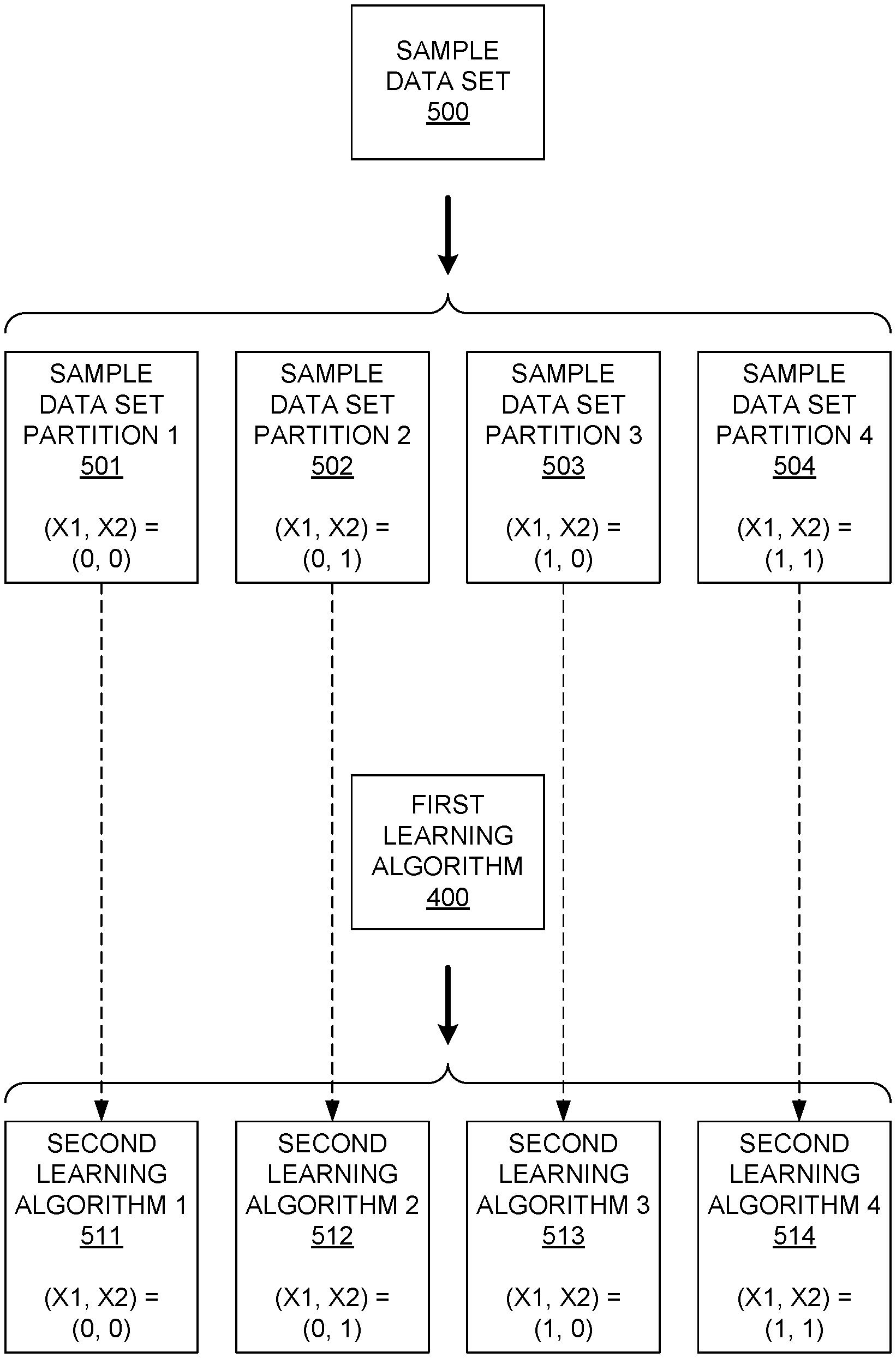
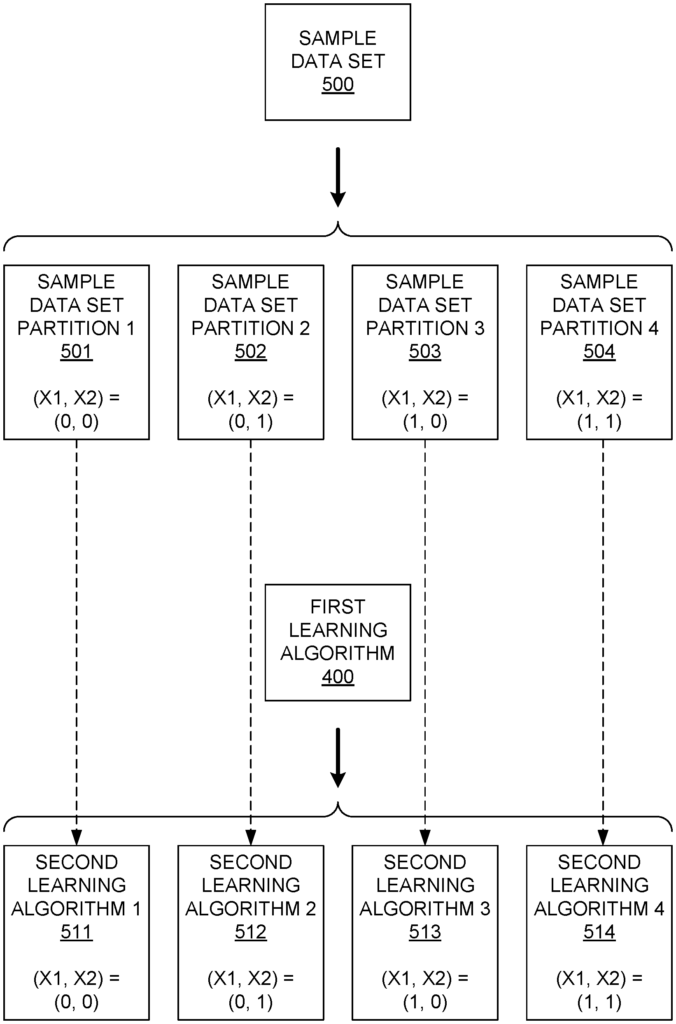
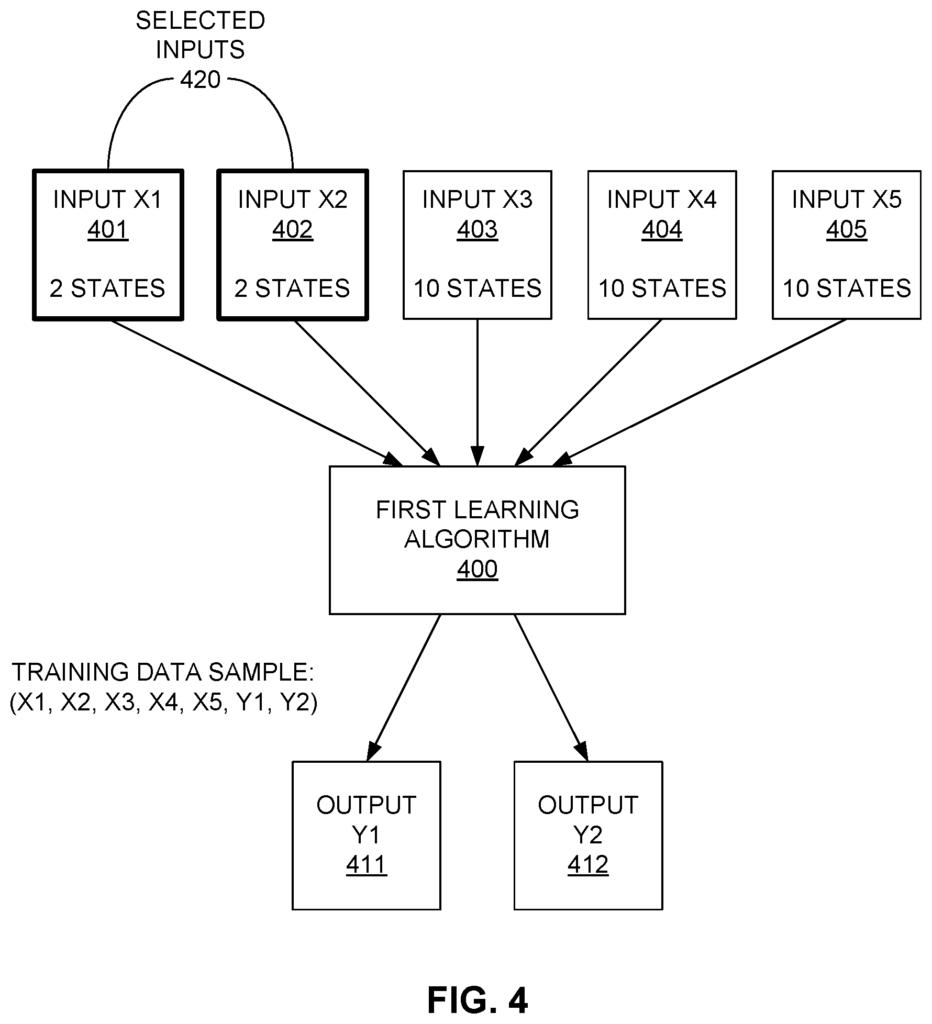
Examples of systems and methods for developing a model are shown. In one example, the sample data set is used to train a learning algorithm. The number of input states in the sample data set are determined. The sample data set is divided into partitions based on the number of states that are combined for each subset of inputs. Each partition is assigned a second learning algorithm, which receives all the inputs. Each second learning algorithm is assigned to a particular processor and trained with the samples from the partition that corresponds to the algorithm. The decision logic generates a set of rules to direct a plurality operational data units to be input to a second learning algorithm based on the states of selected inputs for each operational data unit.
Background for Parallel development and deployment of machine learning models
Machine learning models can be used to extract descriptive or predictive data from large input datasets. Machine learning models can be used for a variety of purposes, including data mining, pattern identification, spam? “Identification, audio transcription and more.
Generally, machine learning models can be classified as either supervised or unsupervised. The supervised learning model or algorithm is initially trained with a sample or training data set. Each sample contains one or multiple input values, and one or several output values caused by or produced by those input values. These data samples are often referred to as “labeled”. Data samples are referred to as such because the output values and input values are explicitly associated. After the supervised algorithm is trained using the sample data set and the operational data is provided, the algorithm is trained to produce the output value of each unit. The types of supervised models include artificial neural networks (ANNs), Bayesian network, and symbolic machine-learning algorithms.
In unsupervised learning models the training data are ‘unlabeled’. The training data is not tagged with a label or a value. All observed values in the training data samples can be assumed to be caused by hidden or “latent” variables. Variables or values can be provided to an unsupervised learning algorithm as observed values. Nevertheless, input and output values or variables can be given to an algorithm for unsupervised learning as observed values in order to establish a relationship between inputs and outcomes, even if the algorithm does not consider the inputs to produce or cause the outputs. Unsupervised learning models can be used to find hidden features or structures in operational data or cluster similar data instances. Unsupervised learning models can include ANNs, cluster analysis algorithms and outlier detection algorithms.
Hybrid methods, such as semisupervised learning algorithms or models, can use both labeled data and unlabeled for training. In these models, a large amount of unlabeled and a small amount of labeled information is often used during the training phase.
The size of both the training data and operational data units used in typical machine learning algorithms has increased significantly. This has led to a significant increase in processing times for developing and deploying models that use these large data sets.
BRIEF DESCRIPTION DES DRAWINGS
The accompanying figures illustrate the present disclosure by way of illustration and not limitation, and they include:
FIG. “FIG.
FIG. “FIG.
FIG. “FIG.
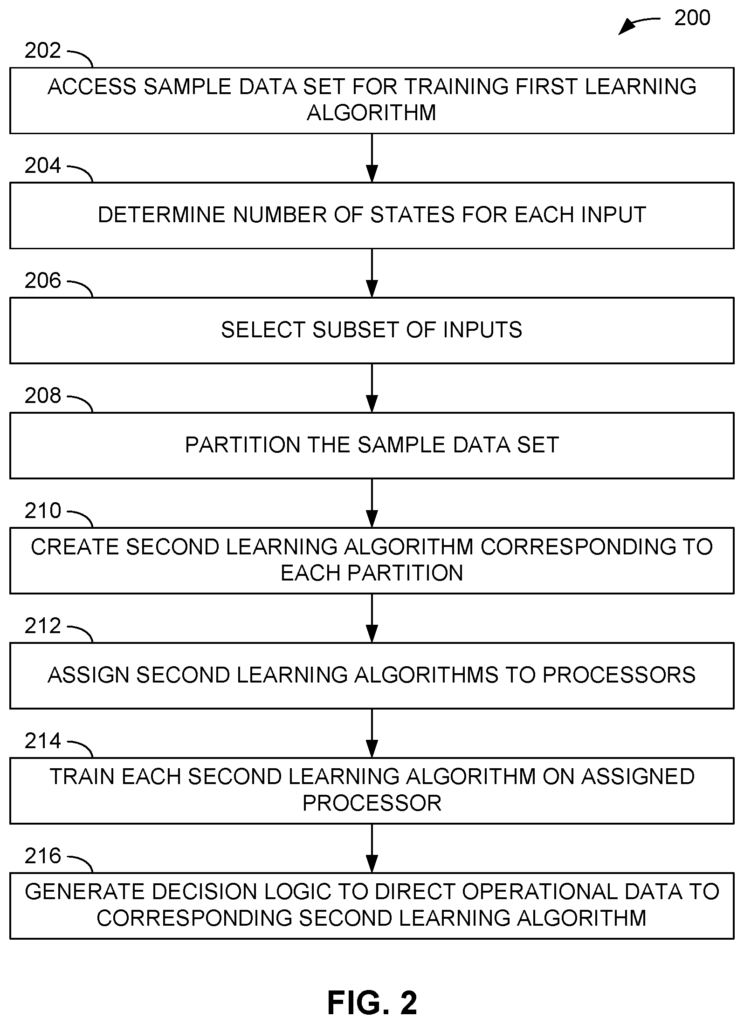
FIG. “FIG.
FIG. “FIG. 4;
FIG. “FIG.6 is a block-diagram representing an example of decision logic that directs each operational data unit towards a second learning algorithm corresponding to it;
FIG. “FIG.
FIG. “FIG. 8 is a flow chart of an example of a method of selecting inputs so that the number second learning algorithms is equal or greater than a number processors.
FIG. “FIG. 9 shows a flow chart of an example of a method to select a specific input by comparing it with another input that has the same number states but a more uniform distribution of values;
FIG. “FIG.10 is a flow chart of an example of how to determine the number of neurons hidden in at least one second network, based on the number of neurons hidden in a neural network that serves as a learning algorithm.
FIGS. “FIGS.
FIG. “FIG.
The following description includes examples of illustrative methods, systems, techniques, instructions sequences, and computer program products which illustrate illustrative implementations. To provide a better understanding of the various embodiments, many specific details will be provided in the following description. To those who are skilled in the field, it will be obvious that embodiments of inventive subject matter can be practiced even without these specifics. “In general, well-known instructions, protocols, structures and techniques are not shown in detail.
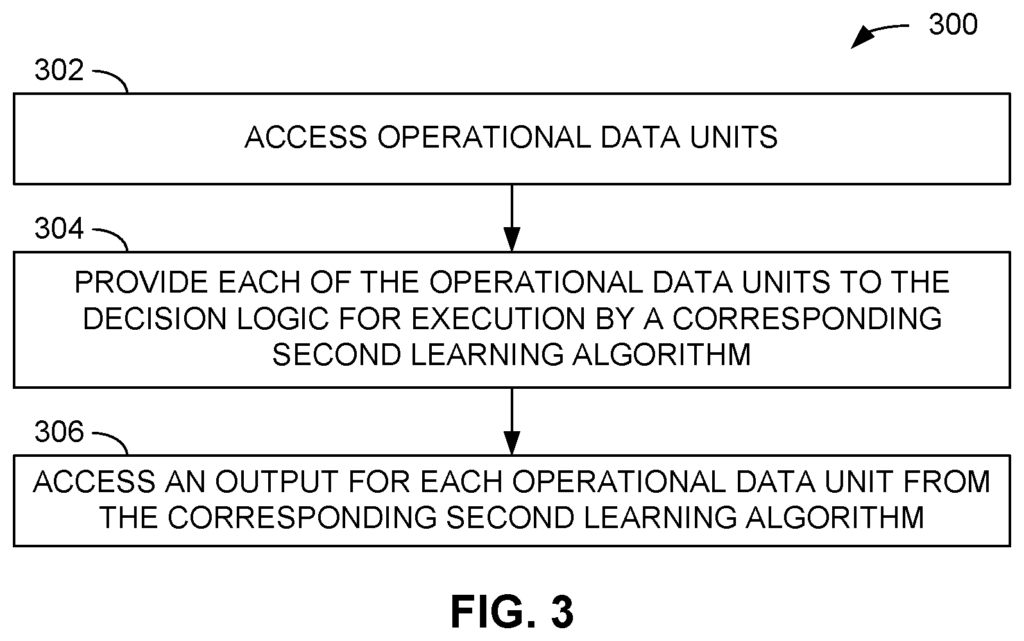
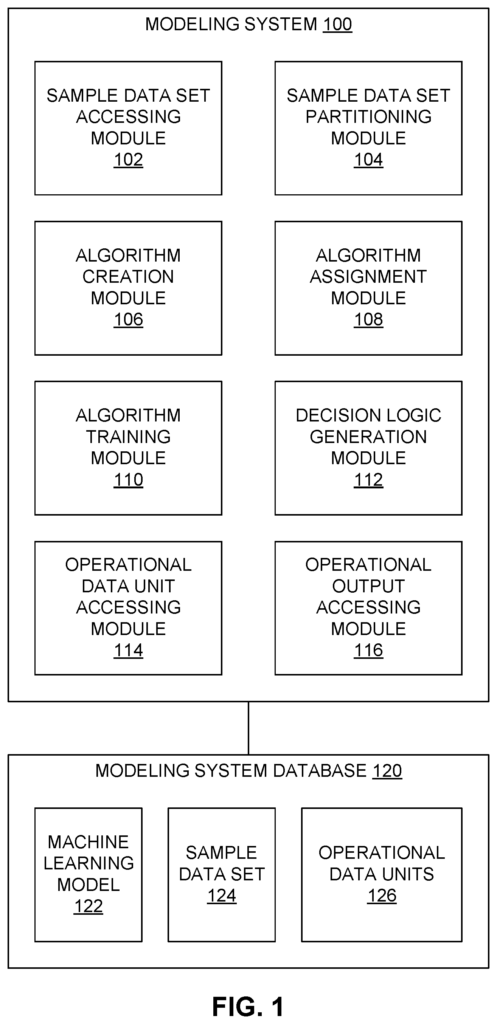
FIG. Block diagram 1 shows an example of a modeling system 100 that is configured to create and deploy a machine-learning model or algorithm across multiple processors. The modeling system 100 in this example includes a sample dataset accessing and partitioning module, an algorithms creation module, an algorithms assignment module, an algorithms training module, a decision-logic generation module, a module for generating logic, a module for generating decision logic, a module to generate operational data units, a module that accesses operational data units, and a module to access operational outputs. The modules 102-116 can be implemented in either hardware or a combination of software and hardware. The modeling system 100 may include other modules such as a user interface or communication interface. A power supply and similar components are also possible, but they have not been depicted here to simplify the discussion. The modules 102-116 shown in FIG. “1 may be combined into larger modules, subdivided to multiple modules or modified in any other way.
Click here to view the patent on Google Patents.
Leave a Reply