Invented by Kevin Andrew PERKINS, Yahoo Assets LLC
Machine learning ensembles, which combine multiple models to make predictions, have gained popularity due to their ability to improve accuracy and robustness. However, building an effective ensemble requires careful selection and configuration of hyperparameters for each individual model within the ensemble. This process can be time-consuming and challenging, especially when dealing with a large number of hyperparameters and models.
To address this challenge, various systems and methods have emerged in the market to automate and streamline the hyperparameter optimization process. These tools leverage advanced algorithms and techniques to efficiently search the hyperparameter space and identify the optimal configuration for each model in the ensemble.
One popular approach is the use of Bayesian optimization, which uses probabilistic models to model the relationship between hyperparameters and model performance. Bayesian optimization algorithms intelligently explore the hyperparameter space by iteratively selecting new configurations based on the information gained from previous evaluations. This approach has been proven to be highly efficient and effective in finding near-optimal solutions.
Another approach gaining traction is the use of genetic algorithms, inspired by the process of natural selection. Genetic algorithms employ a population of candidate solutions and iteratively evolve them through selection, crossover, and mutation operations. This evolutionary process mimics the survival of the fittest, gradually improving the ensemble’s performance by selecting the best hyperparameter configurations.
Furthermore, there are also systems that leverage machine learning techniques themselves to optimize hyperparameters. These systems use historical data from previous experiments to build predictive models that estimate the performance of different hyperparameter configurations. By leveraging these models, they can efficiently explore the hyperparameter space and identify promising configurations to evaluate.
The market for systems and methods for hyperparameter optimization is diverse, with both open-source and commercial offerings available. Some popular open-source tools include Optuna, Hyperopt, and scikit-optimize, which provide flexible and customizable frameworks for hyperparameter optimization. On the other hand, commercial solutions like Google Cloud AutoML, H2O.ai, and SigOpt offer more advanced features, such as distributed optimization, automated feature engineering, and integration with popular machine learning platforms.
As the demand for machine learning ensembles continues to grow, the market for hyperparameter optimization systems and methods is expected to expand further. Businesses across various industries, including finance, healthcare, and e-commerce, are increasingly relying on machine learning to gain insights from their data and make informed decisions. To stay competitive, organizations need efficient and effective methods for optimizing their machine learning models, and hyperparameter optimization is a crucial component of this process.
In conclusion, the market for systems and methods for hyperparameter optimization for improved machine learning ensembles is witnessing significant growth. With the increasing complexity and scale of machine learning models, the demand for automated and efficient hyperparameter optimization tools is on the rise. As businesses and researchers strive to build accurate and robust machine learning ensembles, these tools play a crucial role in achieving optimal performance and driving innovation in the field.
The Yahoo Assets LLC invention works as follows
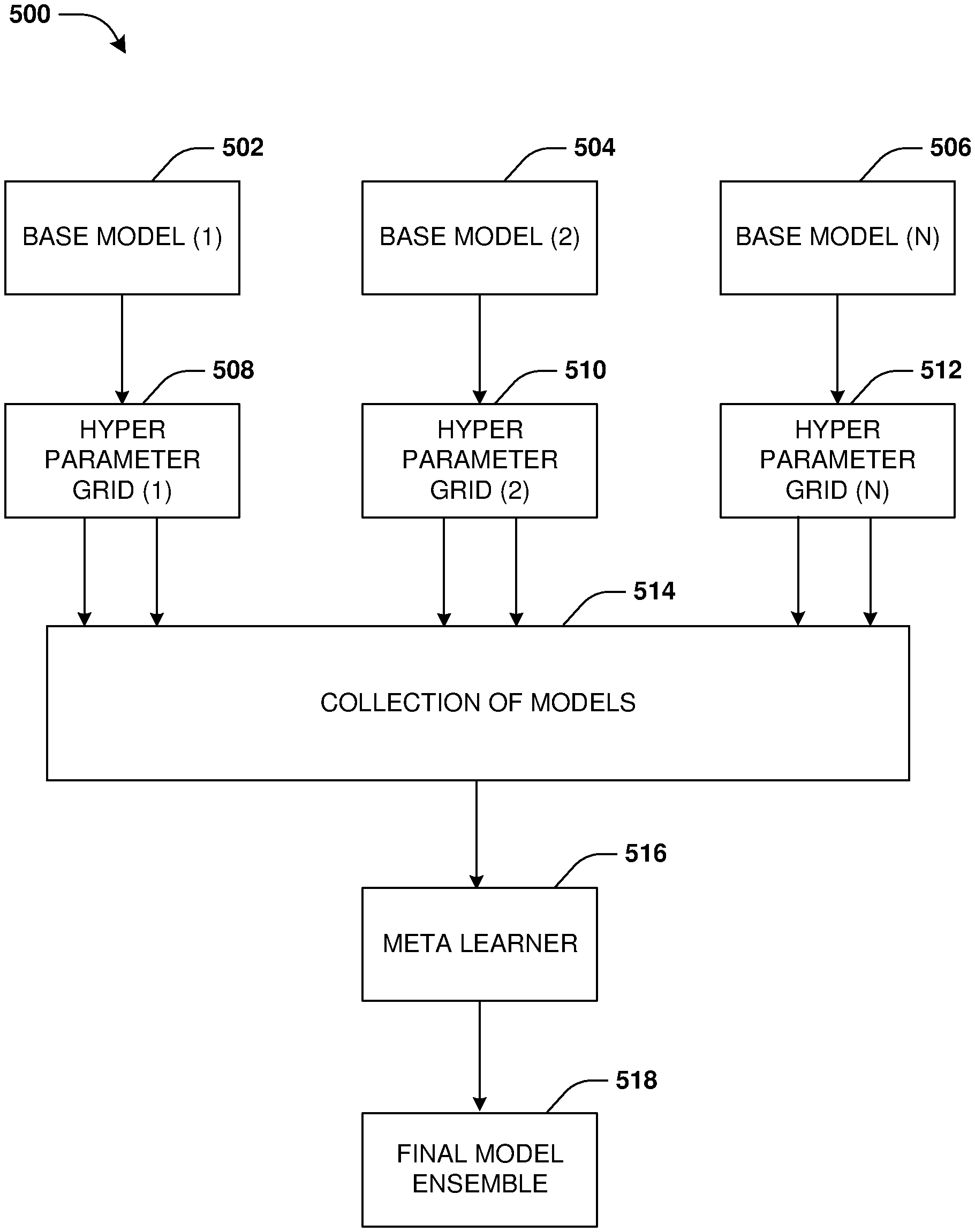
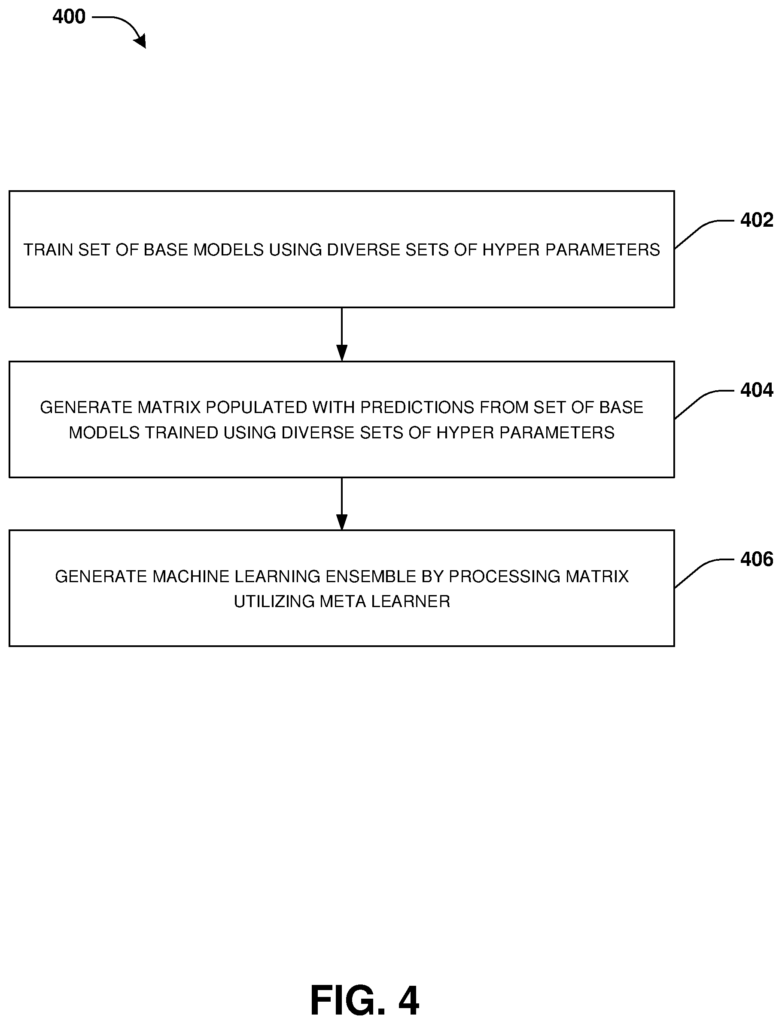
One or more computing systems, methods, or devices for hyper parameter optimization are provided for machine learning ensemble creation.” As an example, different hyper parameter sets (e.g. hyper parameters of different values) can be used to train various base models. The set of base model predictions are populated into a matrix. The matrix is processed using a meta-learner to generate a machine learning ensemble.
Background for Systems and Methods for Hyper Parameter Optimization for Improved Machine Learning Ensembles
Machine Learning can be used to perform different types of tasks. Machine learning is used in a variety of ways, including image recognition, video detection, text recognition and generating recommendations. It can also be used to detect fraud, secure data, perform online searches, or process natural language. A machine learning algorithm is created using a set of data samples that are labeled. For example, the model can be trained by labeling photos as “photo of a vehicle”. A machine learning model is trained using a training data set of labeled data samples, such as where the machine learning model is trained with photos labeled as?photo of a car? After training, a machine learning model will be able to process photos and predict if they depict a car. There are many types of machine-learning models. These include decision trees, support Vector Machines, k nearest neighbors, random forest, linear regression and logistic regression.
A machine learning ensemble can improve the quality of machine learning. The machine learning ensemble is a collection multiple machine learning models. The predictions made by the machine-learning models can be used to make one superior prediction. It takes a lot of time and computing resources to train an ensemble machine learning model because each machine learning model has to be trained individually.
According to the present disclosure, a computing device or method for hyper parameter optimization is provided for machine learning ensembles. A training data set can be used to train one or more base model (e.g. labeled data). Hyper parameters are used to control the behavior of base models (e.g. controlling a machine-learning model). Examples include a maximum depth hyper parameter, or a minimum split samples hyper parameter. A base model is an machine learning model which will be trained with specific values of hyper parameters. Different hyper parameters can be used to train one or more base model, for example where hyper parameters have different values. In a training example, a hyper parameter with a value of 1 is used to train the first base model. In an example of training, a second value for the hyperparameter, which is different from the first value, is used to teach a second model. The first and second base models may be different machine learning models, or they can both be the same model with different hyper parameter values.
A matrix is created based on the predictions made by base models trained with different sets of hyperparameters (e.g. values for hyperparameters). The matrix can be generated by base models that are processing validation data sets without labels and not yet processed. The matrix consists of rows that represent sample data points from the validation data set, and columns that present base models (e.g. base models trained with various hyper parameter values). The matrix contains entries that represent predictions made by base models using the validation data set.
A meta-learner (e.g. a machine learning algorithm such as a model of logistic regression) is configured to handle the matrix to create the machine learning ensemble. Meta learner weights hyper parameter sets based on the accuracy of predictions. The feature selection can be used to reduce the number of entries in the matrix. For example, to remove hyperparameters with low weights, or whose accuracy is below a threshold. The meta learner then generates the machine-learning ensemble based on one or more base models that have accuracies higher than the accuracy threshold, or a selected number of base models with the highest accuracies.
DESCRIPTION DU DRAWINGS
The drawings illustrate a few embodiments that supplement the description. These embodiments should not be interpreted as limiting, for example by limiting the appended claims.
FIG. “FIG.
FIG. “FIG.
FIG. “FIG.
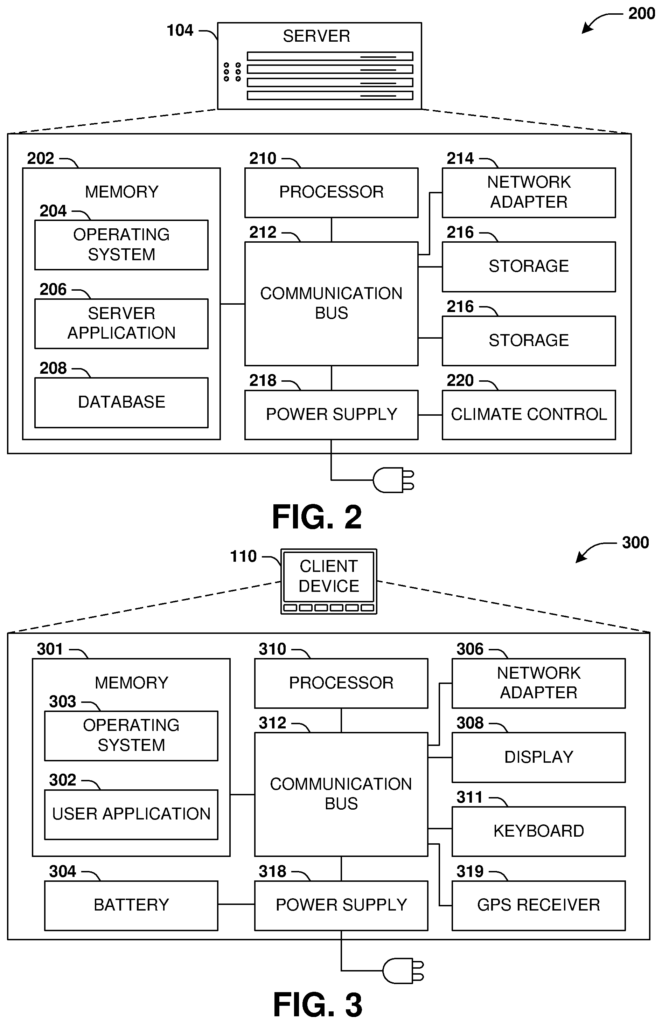
FIG. “FIG.
FIG. “FIG.
FIG. “FIG.
The subject matter will be described in greater detail hereafter, with reference to the accompanying illustrations, which are a part of this document and show, as an illustration, specific examples embodiments. This description does not aim to be a detailed or extensive discussion of concepts that are already known. Details that would be known to people of ordinary skill may have been omitted or handled in a summary manner.
The following subject matter can be embodied as a variety different forms such as devices, methods, components and/or systems. This subject matter does not intend to be limited to the example embodiments presented herein. Example embodiments are merely provided as examples. These embodiments can, for instance, be in the form of software, hardware, firmware, or any combination thereof.
1. Computing Scenario
The following is a discussion on some computing scenarios where the disclosed subject matter can be used and/or implemented.
1.1. Networking
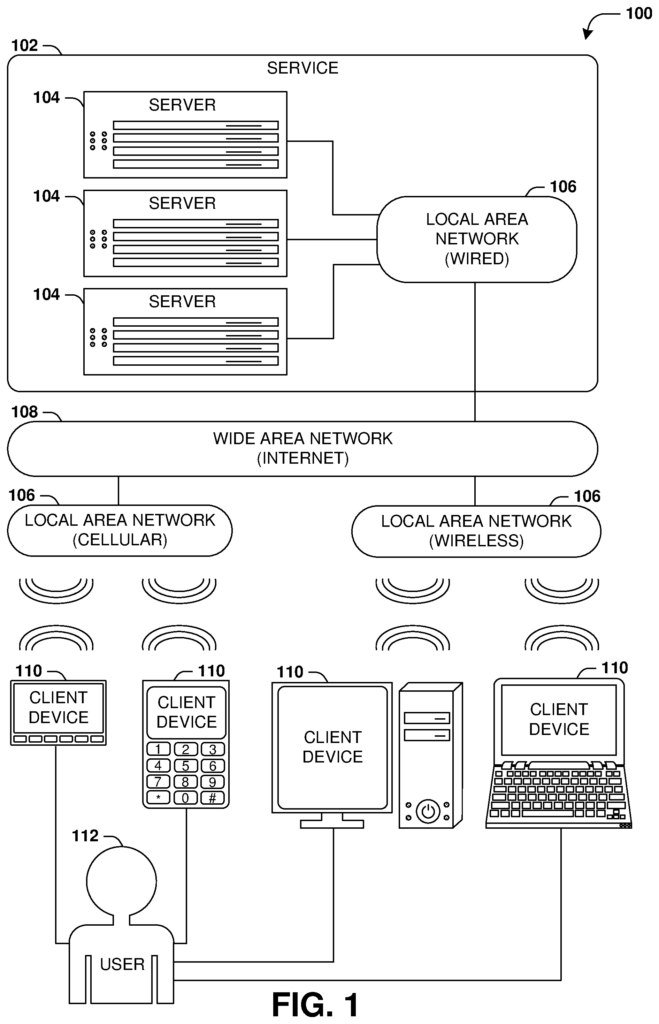
FIG. The interaction diagram 1 illustrates a scenario 100 that shows a service being provided 102 by a group of servers 104 via various types networks to a group of client devices 110. The servers 104 or client devices 110 are capable of receiving, processing and/or storing a variety of signals.
The servers of the service 102 can be internal connected via a Local Area Network 106, such as a cabled network, where the network adapters are connected to the servers via cables (e.g. coaxial or fiber optic cabling) and connected in different topologies (e.g. buses, token rings and/or meshes). Servers 104 can be connected directly or via other networking devices such as routers and switches. The servers 104 can use a variety physical networking protocols, such as Ethernet or Fiber Channel, and/or logic networking protocols, such as variants of the Internet Protocol (IP), Transmission Control Protocol (TCP) and/or User Datagram Protocols (UDP). Local area networks 106 can include analog telephone lines such as twisted wire pairs, coaxial cables, digital subscriber lines (DSLs), ISDNs, satellite links, wireless links or any other communication channels or links that are known in the art. Local area network 106 can be organized in accordance with one or more network architectural types, including server/client, mesh, peer-topeer and/or other architectures. It may also include a variety roles, including administrative servers and authentication servers.
Local area networks 106 can also be divided into sub-networks that may use different architectures, or may comply or be compatible with different protocols, or may even interoperate.” A variety of local networks 106 can be interconnected. For example, a router could provide a connection between two otherwise independent local networks 106.
![]()
Click here to view the patent on Google Patents.
Leave a Reply