Invented by Jun H. Ahn, Waqas ASHRAF, Anup Kumar, Brahmaiah Vallabhaneni, Commvault Systems Inc
Opportunistic execution refers to the ability to perform these secondary copy operations during periods of low system utilization or idle resources. Traditionally, these operations were scheduled during off-peak hours to minimize the impact on primary production systems. However, this approach often resulted in wasted resources and increased costs.
With the advent of advanced technologies and the rise of cloud computing, opportunistic execution has become a viable and cost-effective solution. By leveraging idle resources and optimizing system utilization, organizations can perform secondary copy operations without disrupting primary production systems. This approach not only reduces costs but also enhances data protection and recovery capabilities.
One of the key drivers behind the market growth for opportunistic execution is the increasing demand for data availability and business continuity. In today’s digital age, organizations heavily rely on their data for day-to-day operations and decision-making. Any disruption or loss of data can have severe consequences, including financial losses, reputational damage, and legal implications.
Opportunistic execution offers a proactive approach to data management, ensuring that secondary copy operations are performed in real-time or near-real-time. This minimizes the risk of data loss and enables organizations to quickly recover from any unforeseen events, such as hardware failures, natural disasters, or cyber-attacks.
Furthermore, the market for opportunistic execution is fueled by the growing adoption of cloud-based storage and computing solutions. Cloud platforms provide scalable and flexible infrastructure, making it easier for organizations to leverage idle resources for secondary copy operations. Additionally, cloud providers often offer built-in data management services, further simplifying the implementation of opportunistic execution strategies.
Another factor contributing to the market growth is the increasing complexity of IT environments. As organizations embrace hybrid and multi-cloud architectures, managing data across different platforms and locations becomes more challenging. Opportunistic execution provides a unified and automated approach to data management, regardless of the underlying infrastructure.
The market for opportunistic execution is highly competitive, with numerous vendors offering a wide range of solutions. These solutions vary in terms of features, scalability, and integration capabilities. Some vendors specialize in specific secondary copy operations, such as backup or replication, while others provide comprehensive data management platforms.
Organizations looking to adopt opportunistic execution should carefully evaluate their requirements and select a solution that aligns with their business needs. Factors to consider include scalability, performance, data security, ease of integration, and vendor reputation. Additionally, organizations should assess the total cost of ownership, including licensing fees, maintenance, and support costs.
In conclusion, the market for opportunistic execution of secondary copy operations is experiencing significant growth due to the increasing demand for data availability and business continuity. This approach allows organizations to perform data replication, backup, and recovery during periods of low system utilization, minimizing costs and enhancing data protection. With the rise of cloud computing and the complexity of IT environments, opportunistic execution has become a crucial component of modern data management strategies.
The Commvault Systems Inc invention works as follows
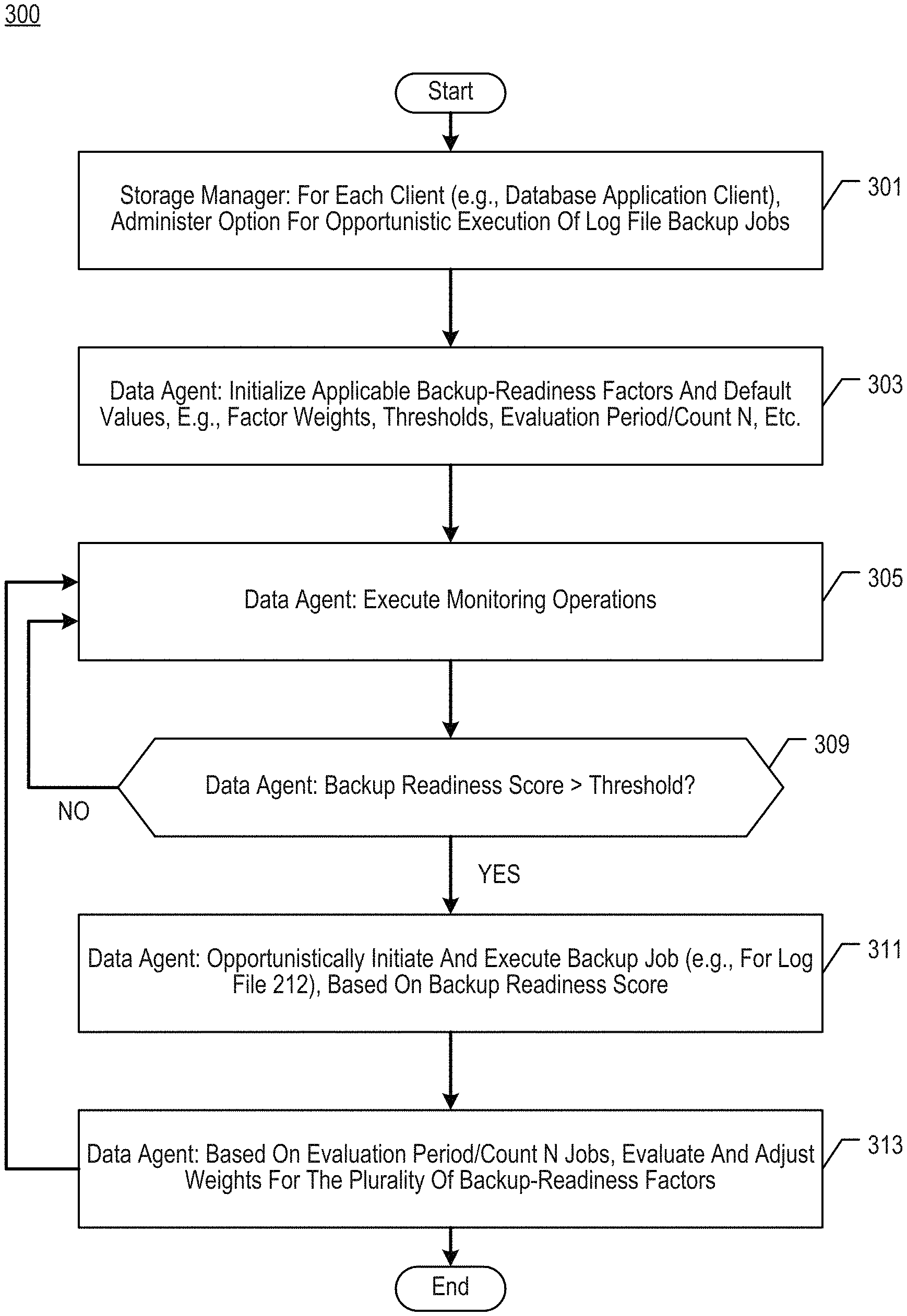
The opportunistic illustrative approach, rather than relying upon pre-defined scheduling for secondary copy operations like backup jobs initiates secondary copies based on changing operating conditions in a Storage Management System. The adaptive backup readiness score depends on several operational factors that affect backup-readiness. A graphical enhanced data agent that is associated with a target database application or other executable component may monitor operational factors, and then determine the backup-readiness score using weights assigned to each operational factor. The enhanced data agent can evaluate recent backup jobs in order to determine the operational factors which contributed most to the score. The enhanced data agent can adjust the weights of the monitored operational variables based on the most relevant analysis. This will allow the backup readiness score to be more responsive and suitable to current operational conditions.
Background for Opportunistic Execution of Secondary Copy Operations
Businesses around the world recognize the value of data, and are looking for cost-effective solutions to safeguard the information on their networks. They also want to minimize the impact on productivity. Information protection is a part of the routine processes that are performed in an organization. As part of its daily, weekly or monthly maintenance, a company may back up important computing systems, such as databases and file servers. The company can protect the computing systems of each employee, including those in an accounting department or marketing department.
The management of transaction log files is a problem that can arise with storage management systems designed to protect database applications. Database applications populate these files in a near-real time manner, as they execute database transactions. The transaction log file can be one or multiple files (collectively called a ‘log file?’). The information is captured for a database so that, in the event of a catastrophic failure, transactions can be replayed. So, for instance, each transaction (e.g. add, delete, or change database records) can be recorded in a log. Some database applications consolidate all transactions into a single transaction log; others create a separate file for every transaction. The log file can be stored on the same device as the database or another device. The log file does not form part of the database, and can be stored separately. The log file should be backed up on a regular basis, regardless of its format or location. It is also considered good practice to keep the size of log files between backups to a reasonable level, so that if the database ever needs to be restored only a small number transactions will need to be rerun from the log. If the log file is too large, it would take too long to restore a database.
It is a good idea to backup transaction logs frequently, so that the downtime required for restoration operations will be minimal. According to the characteristics of the application, the traditional method is to schedule backups for log files, such as every hour, quarter-hour etc. A high-volume, business-critical application might require more frequent backups of log files than a low-volume counterpart. After the log file is backed up, it’s common to truncate the production log, which contains at least some data from the database.
However a regularly scheduled back-up job could collide with an overloaded system, and take precious resources away that would have been better used to run the production environment. A less busy time may be preferred. A regularly scheduled backup may also be unnecessary if a database application’s target has only generated a few transactions since its previous backup. A database application, for example, may be busy delivering search results and reports, but may have very few transactions to record in the log. In this case, a log backup job could waste precious processing resources, as well as use up storage space that would be better used elsewhere.
The present inventors developed an opportunistic solution to this type of problem in an example storage management system. The illustrative approach, which is based on an opportunistic approach, does not rely on a pre-defined schedule for secondary copy operations, such as backups. Instead, it initiates secondary copies based on the changing operational conditions of the storage management system as indicated by an adaptive backup readiness. To achieve this, a number of operational factors for backup-readiness are used. A graphical enhanced data agent that is linked to the target database application can monitor operational factors, and calculate the backup readiness score using weights assigned for each operational factor. Some backup readiness score thresholds may be used to trigger the creation of a log file back up job. Backup jobs are then initiated based on backup readiness scores rather than a schedule.
Examples for backup-readiness operations factors that can be monitored by an enhanced data agent include, without limitation, any or all of the following: (i), a measurement of how much storage space is occupied by a log file;(iii), a measurement of how much storage space has been occupied since a previous backup job began; (iv), a count of database applications executed since a prior backup job started; (v), a time measure since the preceding job was begun; (vi) (vii) (viiiiiiiiiiiiiiiiiiiiiiiiiiiiiii (i (i (i (i (i (i (i (i (i (i (i (i (i (i (ii (i (i (i (i (i (i (i (i (ii (vii) (viii (vii) (viiiiiiiiiiiiii Additionally, release- and vendor-specific operational indicators may also be used. The backup readiness score in a storage management system may be based upon a combination of these operational factors. Each factor has its own weight parameter.
The backup readiness score can be adjusted. The enhanced data agent can evaluate log file backups to determine the operational factors most relevant to the backup score. The enhanced data agent can adjust the weights of the operational factors monitored based on the most relevant analysis.
As an example, a backup-readiness operation factor may be most relevant in a certain evaluation cycle if it is the one that exceeds its threshold the most (relatively to other operational factors included in the backup readiness score). If a particular operational factor is repeatedly over the threshold, it may indicate that this condition requires more attention in the future. For example, the score for backup readiness may need to be re-weighted to make backup jobs more likely. A factor that is frequently over its threshold will be given more weight so that the triggering of backups more closely matches that factor’s behavior. The backup readiness score can be used to trigger backup jobs as conditions in the storage system change (as shown by the operational factor). The illustrative agent can initiate backups based on a set of operational factors monitored and their adaptive weights. This is more in line with the changing conditions of the system than the regular scheduled approach.
The invention is not restricted to an enhanced data agent that performs the monitoring, evaluating and adjusting and/or initiating. An enhanced storage manager or media agent can perform all or some of these operations. The invention is also not limited to database apps; any executable components, such as a filesystem, an operating systems, a virtual machines, or any other applications, can benefit from the opportunistic method described herein. The invention is also not limited to log files. Any type of data structure, such as directories or databases, can benefit from opportunistic copy operations. The invention is also not limited to backup operations; any secondary copy operation can be executed opportunistically, including making archive copies or making reference copies. It may also include taking snapshots and/or performing lifecycle management and hierarchical management.
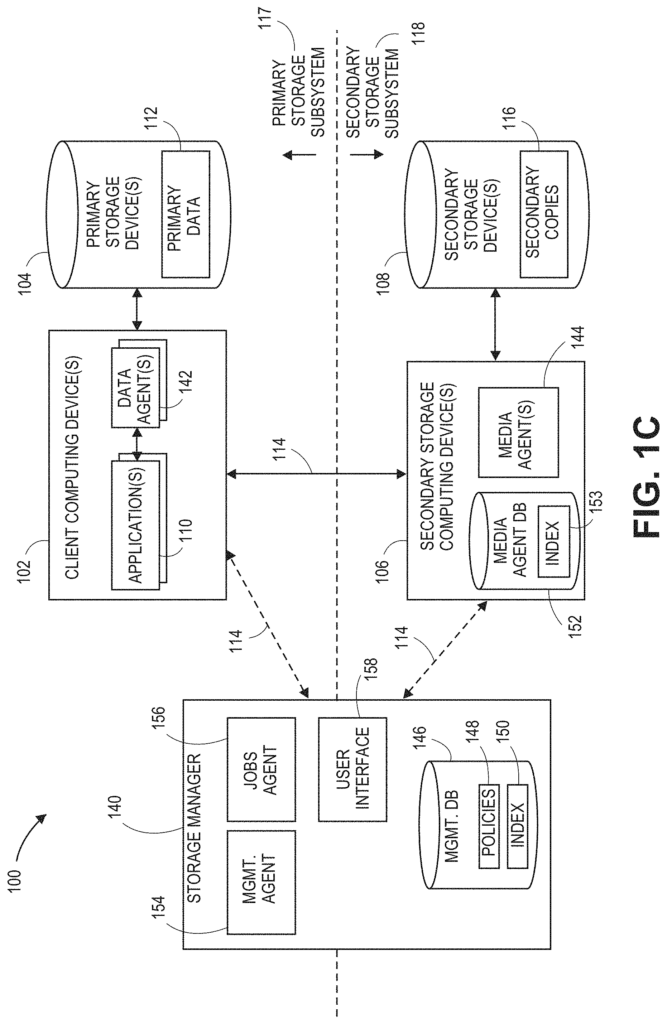
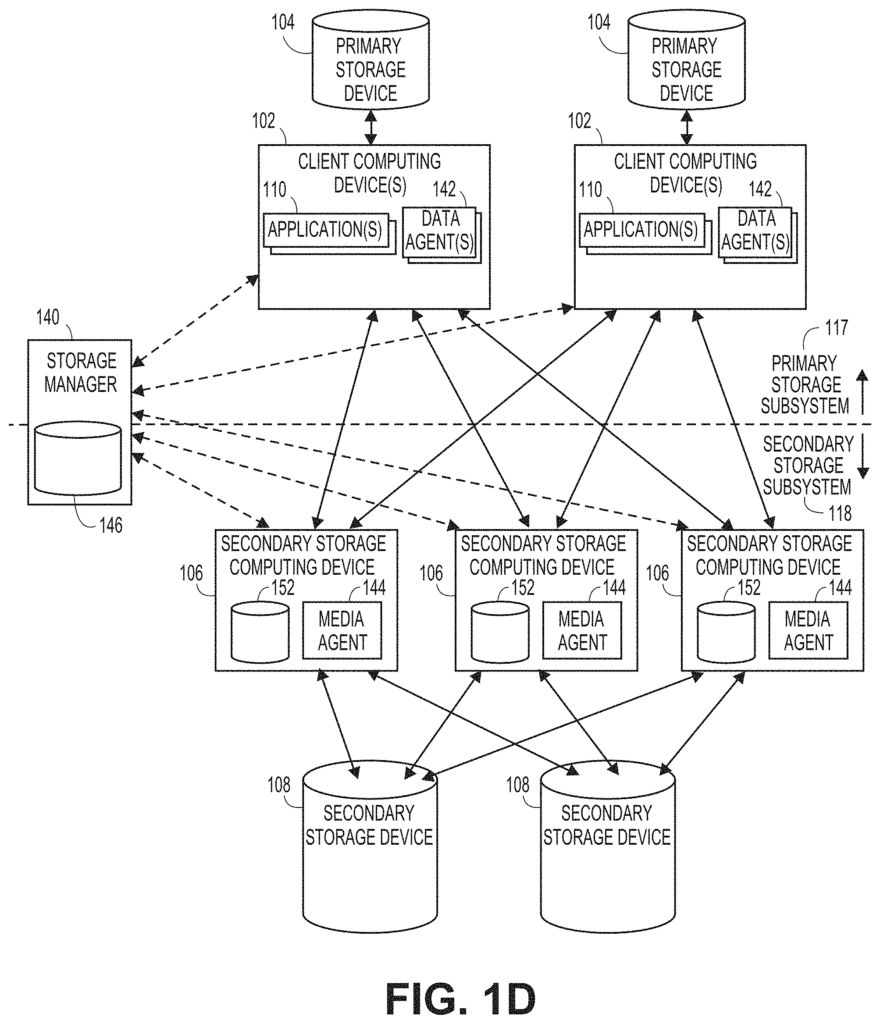
Systems and Methods are disclosed for the opportunistic performance of secondary copy operations. In this document, examples of these systems and methods will be described in greater detail with reference to FIGS. 2-6. Components or functionality that allows for the opportunistic performance of secondary copy operations can be configured into and/or integrated into information management system such as those shown in FIGS. 1A-1H.
Information Management System Overview
Organizations simply cannot afford to lose critical data. This is because of the growing importance of protecting and leveraging data. Protecting and managing data is becoming more difficult due to runaway data growth and other modern realities. It is imperative to have user-friendly, efficient and powerful solutions for managing and protecting data.
Depending on the organization’s size, there may be many data production sources that fall under the control of thousands, hundreds or even thousands of employees. Individual employees used to be responsible for protecting and managing their data in the past. In other cases, a patchwork of software and hardware point solutions was used. These solutions were often offered by different vendors, and sometimes had little or no interoperability.
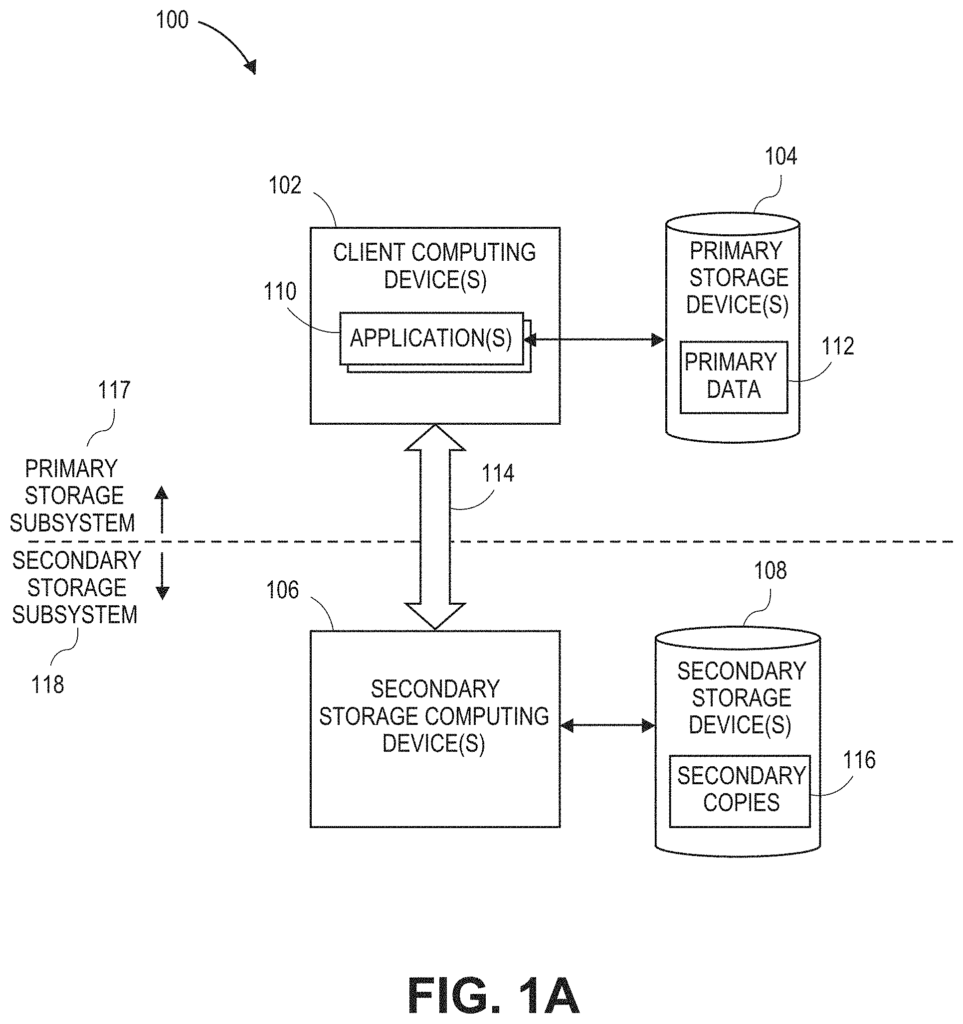
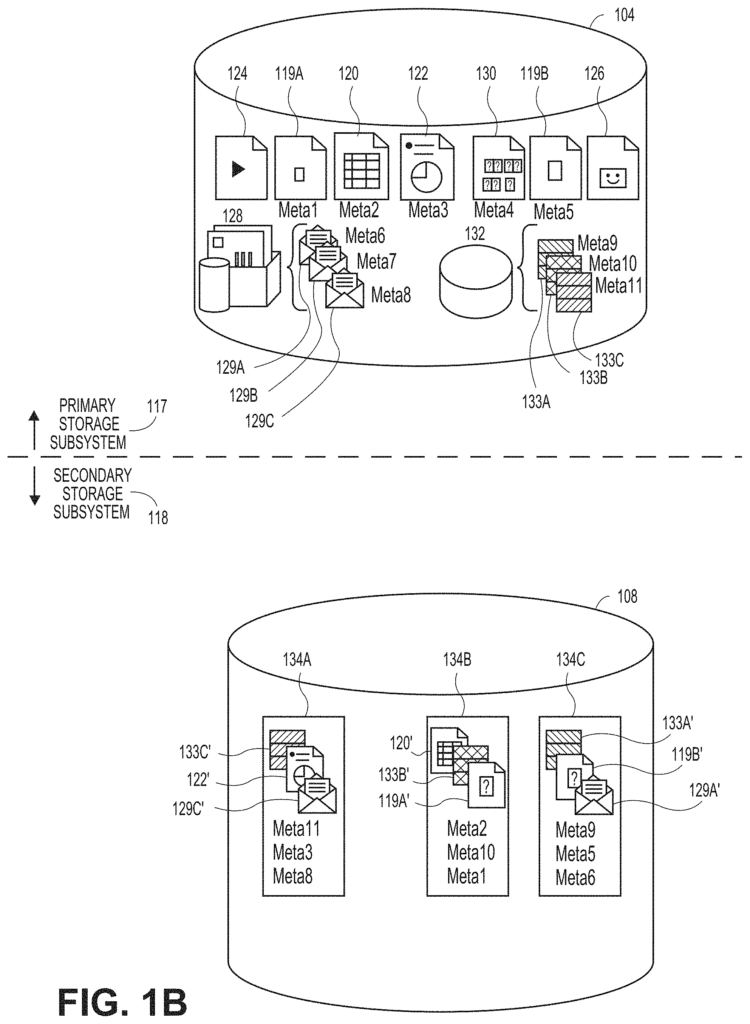
CERTAIN embodiments described herein offer systems and methods capable to address these and other shortcomings in prior approaches by implementing unified information management across the organization. FIG. FIG. 1A illustrates one such information management systems 100. It generally includes combinations hardware and software that are used to manage and protect data and metadata generated by various computing devices within information management system 100. An organization using the information management system 100 could be a company, other business entity, educational institution, household or governmental agency.
Generally, the systems described herein may be compatible and/or provide some of the functionality of one or more U.S patents or patent application publications assigned by CommVault Systems, Inc., each which is hereby incorporated into its entirety by reference herein.
The information management software 100 can contain a wide range of computing devices. As an example, the information management software 100 could include one or more client computing device 102 and secondary storage computing device 106, as we will discuss in more detail.
Computer devices may include without limitation one or more of the following: personal computers, workstations, desktop computers or other types generally fixed computing systems like mainframe computers or minicomputers. Other computing devices include portable or mobile computing devices like laptops, tablets computers, personal information assistants, mobile phones (such a smartphones), and other mobile/portable computing devices like embedded computers, set top boxes or vehicle-mounted devices. Servers can be included in computing devices, including mail servers, file server, database servers and web servers.
In certain cases, a computing device may include virtualized and/or Cloud computing resources. A third-party cloud service provider may provide one or more virtual machines to an organization. In some cases, computing devices may include one or more virtual machines running on a physical host computing device (or “host machine?”). The organization may use one or more virtual machines to run its database server and another virtual machine as a mail server. One example is that the organization might use one virtual machine to run its database server and another as a mail server. Both virtual machines are running on the same host computer.
A virtual machine is an operating system and associated resources that is hosted on a host computer or host machine. Hypervisor is typically software and is also known as a virtual monitor, virtual machine manager or?VMM? The hypervisor acts as a bridge between the virtual machine’s hardware and its host machine. ESX Server, by VMware, Inc., of Palo Alto, Calif., is an example of hypervisor used for virtualization. Other examples include Microsoft Virtual Server, Microsoft Windows Server Hyper-V, and Sun xVM, both by Oracle America Inc., Santa Clara, Calif. In some embodiments, hypervisors may be hardware or firmware.
The hypervisor gives each virtual operating system virtual resources such as a processor, virtual memory, and virtual network devices. Each virtual machine can have one or more virtual drives. The data of virtual drives is stored by the hypervisor in files on the filesystem of the physical host machine. These files are called virtual machine disk images (in the instance of Microsoft virtual servers) and virtual machine disk files (in case of VMware virtual server). VMware’s ESX server provides the Virtual Machine File System, (VMFS), for storage of virtual machine files. Virtual machines read and write data to their virtual disks in the same manner as physical machines.
U.S. Pat. 102,297 describes “Examples for information management techniques in cloud computing environments.” No. No. 8,285,681 is incorporated herein. U.S. Pat. explains some techniques for managing information in virtualized computing environments. No. No. 8.307,177, also included by reference herein
Click here to view the patent on Google Patents.
Leave a Reply