Invented by Jim C. Chou, Alexandros Tourapis, Apple Inc
Machine learning video processing systems utilize algorithms and models to automatically extract meaningful information from video data. These systems can perform a wide range of tasks, including object detection and tracking, facial recognition, scene understanding, and video summarization. By leveraging machine learning techniques, these systems can process videos at a much faster rate and with higher accuracy compared to traditional methods.
One of the key drivers of the market for machine learning video processing systems is the rapid growth of video content across various platforms. With the rise of social media, streaming services, and online advertising, the demand for video content has skyrocketed. This has created a need for efficient and scalable video processing solutions that can handle the massive amounts of data generated daily.
Another factor contributing to the market growth is the increasing adoption of artificial intelligence (AI) in various industries. Machine learning video processing systems are being used in sectors such as security and surveillance, healthcare, automotive, entertainment, and retail. For example, in the security and surveillance industry, these systems can analyze video footage in real-time to detect suspicious activities or identify individuals of interest. In healthcare, machine learning video processing can aid in the analysis of medical imaging data, enabling faster and more accurate diagnosis.
The market for machine learning video processing systems is also benefiting from advancements in hardware technology. The availability of powerful GPUs (graphics processing units) and specialized chips designed for AI and machine learning tasks has significantly improved the performance and efficiency of these systems. This has made it easier for businesses to adopt and integrate machine learning video processing solutions into their existing infrastructure.
However, despite the promising growth prospects, the market for machine learning video processing systems still faces some challenges. One of the major challenges is the need for large amounts of labeled training data. Machine learning algorithms require extensive training on labeled data to achieve high accuracy. Acquiring and annotating such data can be time-consuming and expensive, especially for niche applications or industries with specific requirements.
Additionally, ensuring the privacy and security of video data remains a concern. As machine learning video processing systems become more prevalent, there is a need to address issues related to data protection, consent, and compliance with regulations such as the General Data Protection Regulation (GDPR).
In conclusion, the market for machine learning video processing systems, methods, and techniques is witnessing rapid growth driven by the increasing demand for video content and the adoption of AI across various industries. With advancements in hardware technology and the ability to process videos at scale, these systems are poised to revolutionize the way we analyze and interpret video data. However, challenges related to data availability and privacy need to be addressed to fully unlock the potential of machine learning video processing in the market.
The Apple Inc invention works as follows
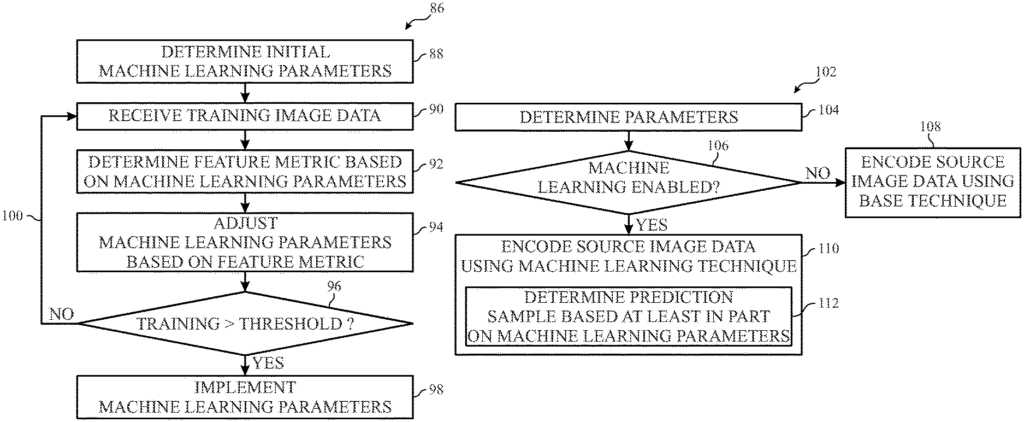
System and method of improving video encoding or video decoding.” A video encoding pipe includes a main pipeline that generates encoded image data by compressing source image data associated with an image frame. The processing of the source data is based, at least in part, on encoding parameter values. The video encoding pipe includes a machine-learning block that is communicatively connected to the main encoding block. This machine-learning block analyzes the content of an image frame based on processing the source data using machine learning parameters.
Background for Machine learning video processing systems, methods and techniques
The present disclosure relates generally to video processing, and more specifically to processing image data (e.g. encoding decoding, analysing and/or filtering), based at least partially on machine learning techniques.
This section is designed to introduce the reader with various aspects of art which may be related to the various aspects of present techniques that are described or claimed below. This discussion should help the reader to better understand the different aspects of this disclosure. It is important to understand that these statements should not be interpreted as an admission of prior art.
To present visual representations, an electronic device can use an electronic display that displays one or more frames (e.g. image data) in accordance with the image data. Image data can be stored on an electronic device or received from another device. The image data is then encoded to reduce the size (e.g. number of bits), and thus the resources used (e.g. transmission bandwidth, and/or addresses in memory) for transmitting and/or storing image data. The electronic device can decode encoded data to display an image and then instruct the display to adjust the luminance of the display pixels according the decoded data.
In some cases, image data can be encoded using at least part prediction techniques. Image data that corresponds to a block (or portion) of an image may be encoded using a sample of prediction, which is a prediction for at least this portion. The prediction sample can be calculated based on the image data of the same frame using intra-prediction techniques, since image frames are often changed gradually. As successive image frames often look similar, the sample can be calculated based on data from an image frame that is directly preceding or following, for example using inter-prediction techniques.
In either case, the prediction samples can be determined by encoding parameters that, for example indicate if an inter-prediction technique or intra-prediction technique is to be used. Changing the encoding parameter may lead to different prediction samples, and thus different encoded image data. In some cases, changing the encoding parameter may impact encoding (e.g. size of encoded image data or encoding throughput), as well as decoding (e.g. decoding throughput) and video quality when decoded images are used to display an object.
Below is a summary of some embodiments described herein. These aspects are presented to give the reader a quick summary of certain embodiments, and are not meant to limit the scope. This disclosure can include a wide range of aspects, some of which may not be described below.
The present disclosure relates generally to improving video encoding or video decoding. For example, it aims to improve encoding efficiency and/or decoding efficiency and/or perceived quality when decoded images are used to display an object (e.g. an image frame) on a display. Image data can be compressed (e.g. encoded) to reduce the size. This will help reduce resource usage. “For example, the video encoding pipe may encode image data using inter- or intra-prediction techniques.
To predict encode source image, it is possible to determine a sample of prediction (e.g., predictor), that indicates a predicted value for the image data. This can be done by adjusting encoding parameters. A prediction residual that indicates the difference between the sample and source image data can be calculated based on the sample. The prediction residual, along with the encoding parameter implemented to determine it, be transcoded into encoded image data.
In some cases, different encoding parameter implementations may lead to different prediction samples, and thus, different degrees of matching between the source image data, and the predicted samples. In some cases, the degree of matching can affect encoding (e.g. encoded image size, encoding energy consumption, or encoding output), decoding (e.g. decoding power usage, or decoding output), and perceived image quality (e.g. decoding power use, and/or decoding input).
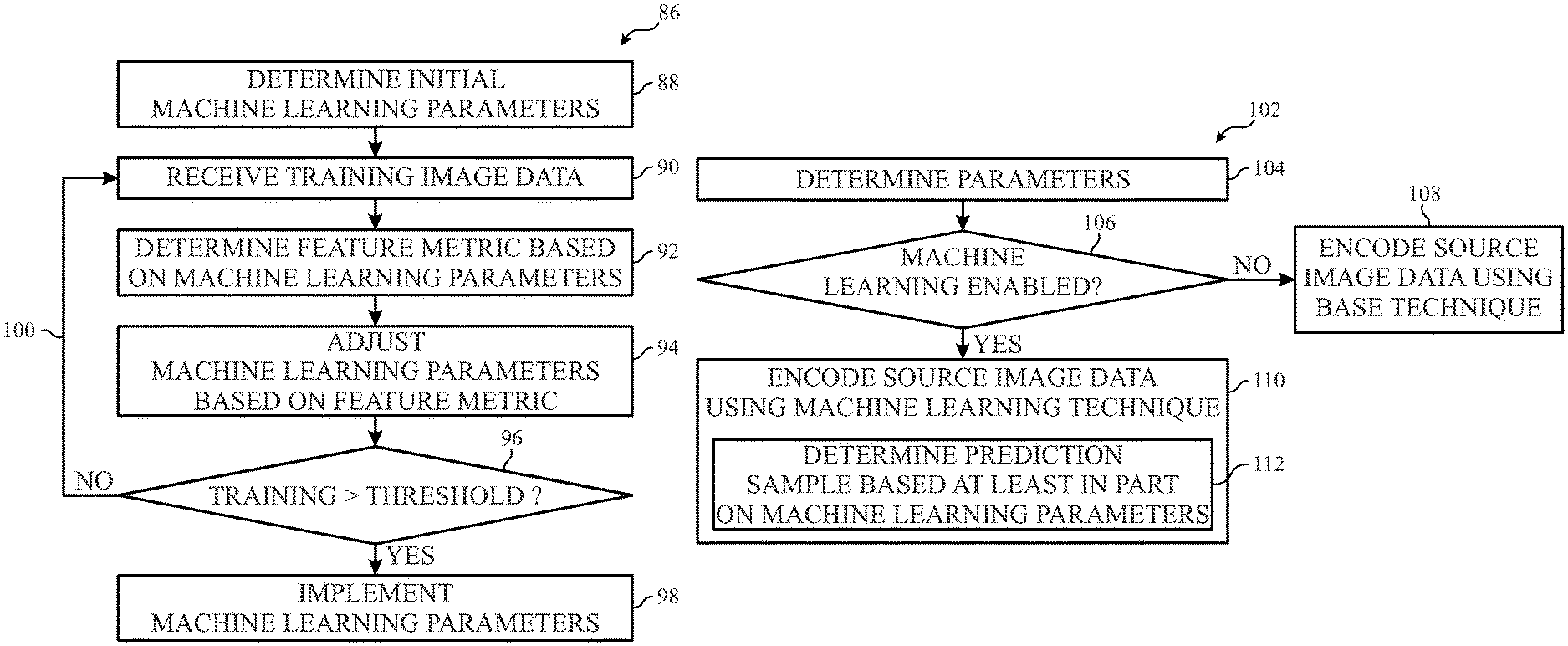
Accordingly, the present disclosure discloses techniques for improving video encoding or video decoding. For example, this can be achieved by increasing the probability that a sample prediction will match the corresponding image data. In some embodiments, machine learning blocks may be implemented in video encoding or video decoding pipelines to utilize machine learning techniques such as convolutional network (CNN). The machine learning block can analyze image data (e.g. source image data or decoded/encoded data) and determine expected characteristics such as texture gradient color sharpness motion and/or edges.
To make it easier to identify the characteristics of an image, machine learning blocks can be trained in order to determine machine-learning parameters. When the machine-learning block uses convolutional neural networks (CNN), the machine-learning parameters can indicate the number of layers in the convolution, the interconnections between the layers and/or the weights (e.g. coefficients) for each layer. The machine learning block can provide a content analysis after training to adjust the encoding and/or decoding parameter.
For example when a predictive technique is to implemented, the video encoder pipeline may determine a sample for a predicted result by down-sampling, e.g. source image data, or prediction residuals, applying a transform and quantization forward, applying inverse quantization with an inverse transform and upscaling. In some embodiments the video encoding pipe may down-scale or up-scale depending on encoding parameter, such as target aspect ratio, filter weighting (e.g. interpolation), and/or filter mode. The video encoding block may adjust the encoding parameter used to determine the predicted sample based on the content analysis provided from the machine learning blocks. This may, at least in certain instances, facilitate improved video processing (e.g. encoding or decoding) by improving the degree of match between the prediction and source image data.
To facilitate further improving video, decoded images data can be filtered at least in part based on filter parameters. This reduces the likelihood of displaying an artifact visible when used to display an image. In some embodiments the filter parameter may be determined using machine learning techniques. For example, a machine-learning block can be used to eliminate the need for manual tuning (e.g. trial and error). The machine learning block allows the filter parameters that are applied to the decoded images to be adjusted adaptively in a manner dependent on the content. This, at least in certain instances, may improve perceived video quality by reducing the likelihood of visual artifacts.
Machine learning techniques can be used to improve the determination of expected video quality. In some embodiments the expected video quality can be determined by a machine-learning block. This could, for instance, be implemented in either a video encoding or decoding pipeline. In some embodiments, a machine learning block can be trained using training image data, and the corresponding video quality. This will make it easier to determine expected video quality. The machine learning block can be trained, for example, by adjusting the machine learning parameters so that the expected video quality based on the feature metric matches actual video quality.
In some embodiments, the encoding parameters or filter parameters can be adjusted adaptively based at least in part, on the expected video. This will improve perceived video quality, when decoded data is used to display an image. By implementing a learning block, encoding and/or filter parameters can be adjusted adaptively to improve encoding and/or coding efficiency. The techniques described herein may improve video processing (e.g. encoding and decoding, analysing and/or filtering), by implementing one or more machine-learning blocks that adaptively adjust the image data processing according to the content.
Below, we will describe one or more embodiments of this disclosure. These embodiments are examples of the techniques disclosed. In an effort to give a concise description, not all features of a real implementation are described in the specification. It should be appreciated that in the development of any such actual implementation, as in any engineering or design project, numerous implementation-specific decisions must be made to achieve the developers’ specific goals, such as compliance with system-related and business-related constraints, which may vary from one implementation to another. It should also be understood that, while a complex development effort may take a long time, for someone with ordinary skills, this could be a simple design, fabrication and manufacturing project.
When introducing the elements of different embodiments of this disclosure, the articles are?a? ?an,? The words?an?,? The terms?the? and?the? are used to indicate that one or more elements are present. The words?including,? ?including,? The words ‘including,? The words?including’ and?having’ are meant to be inclusive, meaning that additional elements may exist in addition to the elements listed. It should also be understood that references referring to “one embodiment” or “an embodiment” are not meant to exclude other elements. or ?an embodiment? The present disclosure is not intended to exclude the existence of other embodiments which also incorporate the recited feature.
To facilitate the visual presentation of information, an electronics display may display an a image (e.g. image frame or picture), based on image data that indicates target characteristics of the image (e.g. luminance). An electronic device can instruct an electronic display to show an image, for example, by sending image data. In some cases, image data can be stored on the electronic device itself, such as in memory. In some cases, image data can be generated by an external device, like a digital camera. The image data can be sent to the electronic device via a communications network or communication bus.
To reduce resource usage, images may be encoded or compressed to reduce their size (e.g. number of bits). This, for instance, can help reduce transmission bandwidth and/or memory usage. In certain embodiments, the video encoding pipe may encode input (source) image data using at least part prediction techniques. Since image frames are often changed gradually, the video encoder pipeline can use intra prediction techniques in order to encode source data using image data from a single image frame. Since successive image frames can be similar, video encoding may use inter prediction techniques.
In some embodiments, a picture may be divided up into one or more groups of coding to facilitate encoding. A ‘coding group’ is used in this document. This is meant to describe an example (e.g. block) of an image encoded as a single unit. It can be a macroblock (e.g. slice), a picture (e.g. Group of Pictures), a macroblock (e.g. picture), a Group of Pictures(GOP), etc. This allows the image to be encoded using successively encoding the source image data that corresponds to each coding groups in the image.
To prediction encode a code group, it is possible to determine a sample of prediction (e.g. predictor), which shows a predicted source image data that corresponds with the coding. The video encoding pipe may, for example, determine a sample of a coding based on the image data in the same image using intra prediction techniques. The video encoding pipe may also determine a coding group prediction sample using inter prediction techniques based on data from different images (e.g. previously encoded).
Click here to view the patent on Google Patents.
Leave a Reply