Invented by Maria Zuluaga, David Renaudie, Rodrigo Acuna Agost, Amadeus SAS
One of the key drivers of this market is the increasing availability of big data. With the proliferation of digital devices and the internet, businesses now have access to vast amounts of data that can be used to gain valuable insights and make informed decisions. Unsupervised and semi-supervised machine learning models are particularly well-suited for analyzing this unstructured and unlabeled data, as they can automatically identify hidden patterns and relationships.
Another factor driving the market is the need for more efficient and accurate decision-making processes. Traditional rule-based systems and manual analysis methods are often time-consuming, prone to human error, and limited in their ability to handle complex and dynamic data. Unsupervised and semi-supervised machine learning models offer a more automated and scalable approach, enabling businesses to quickly process and analyze large datasets, identify trends, and make data-driven decisions.
Furthermore, the market for these systems and methods is also fueled by the increasing demand for anomaly detection and fraud prevention. Unsupervised machine learning models can identify abnormal patterns or behaviors in data, making them invaluable in detecting fraudulent activities in financial transactions, cybersecurity threats, or even identifying potential health risks in medical data. By deploying these models, businesses can proactively mitigate risks and prevent potential losses.
However, despite the numerous benefits, there are challenges associated with evaluating and deploying unsupervised or semi-supervised machine learning models. One of the main challenges is the interpretability of these models. Unlike supervised models where the relationship between inputs and outputs is explicitly defined, unsupervised models often lack clear explanations for their predictions. This can make it difficult for businesses to trust and understand the decisions made by these models, especially in sensitive domains such as healthcare or finance.
Additionally, the lack of labeled data for training these models can pose a challenge. While unsupervised and semi-supervised models do not require labeled datasets, having some labeled data can help improve their accuracy and performance. Acquiring labeled data can be expensive and time-consuming, especially in domains where expert knowledge is required.
To address these challenges, companies are investing in research and development to enhance the evaluation and deployment of unsupervised or semi-supervised machine learning models. They are exploring techniques to improve interpretability, such as developing algorithms that can explain the reasoning behind the model’s predictions. Additionally, efforts are being made to develop methods for generating synthetic labeled data to augment the training process.
In conclusion, the market for system and method for evaluating and deploying unsupervised or semi-supervised machine learning models is witnessing significant growth. The ability of these models to analyze large amounts of unstructured data, make predictions, and detect anomalies is driving their adoption across various industries. However, challenges related to interpretability and the availability of labeled data need to be addressed to fully leverage the potential of these advanced technologies. As businesses continue to invest in research and development, we can expect further advancements in this field, leading to more accurate and efficient decision-making processes.
The Amadeus SAS invention works as follows
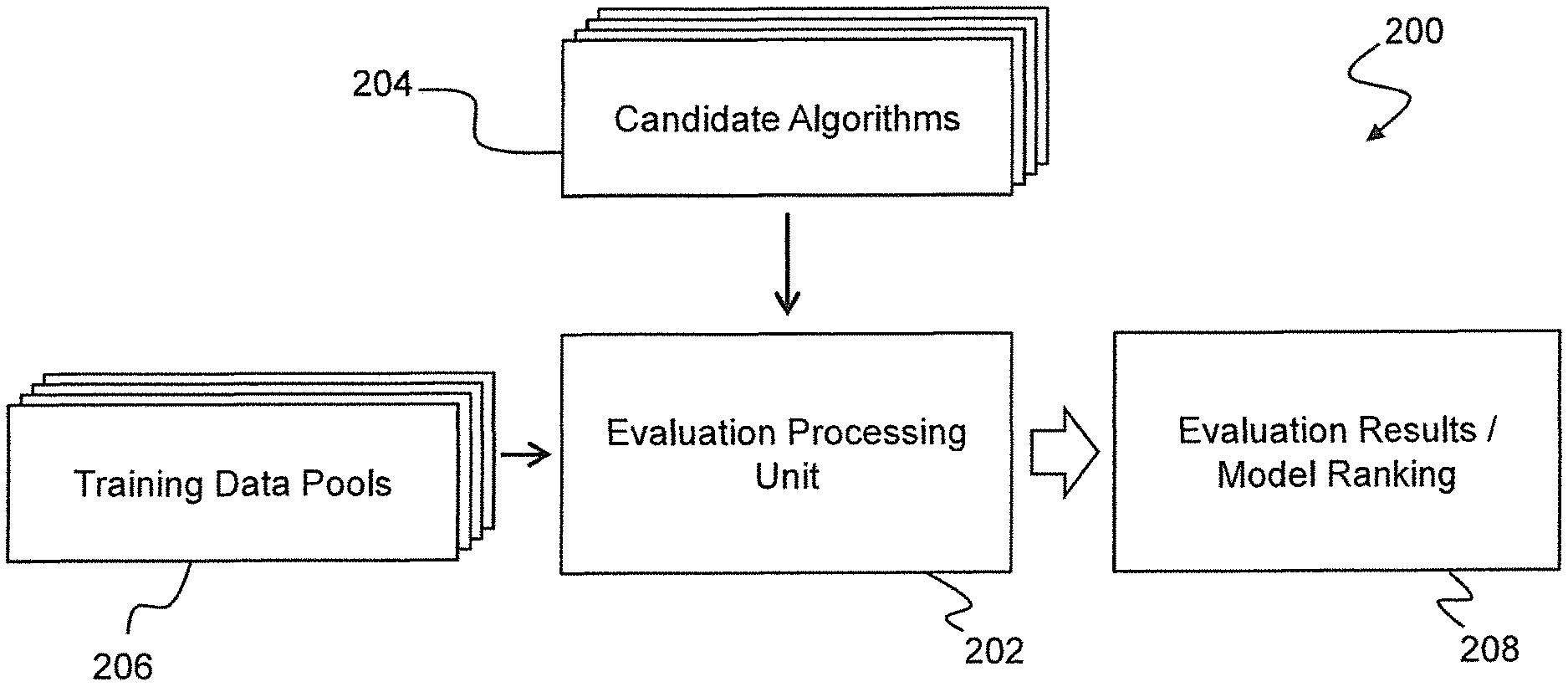
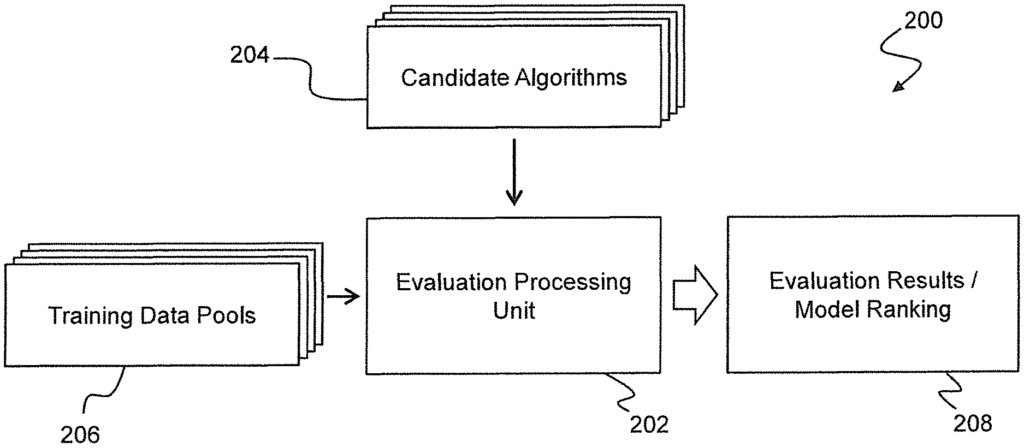
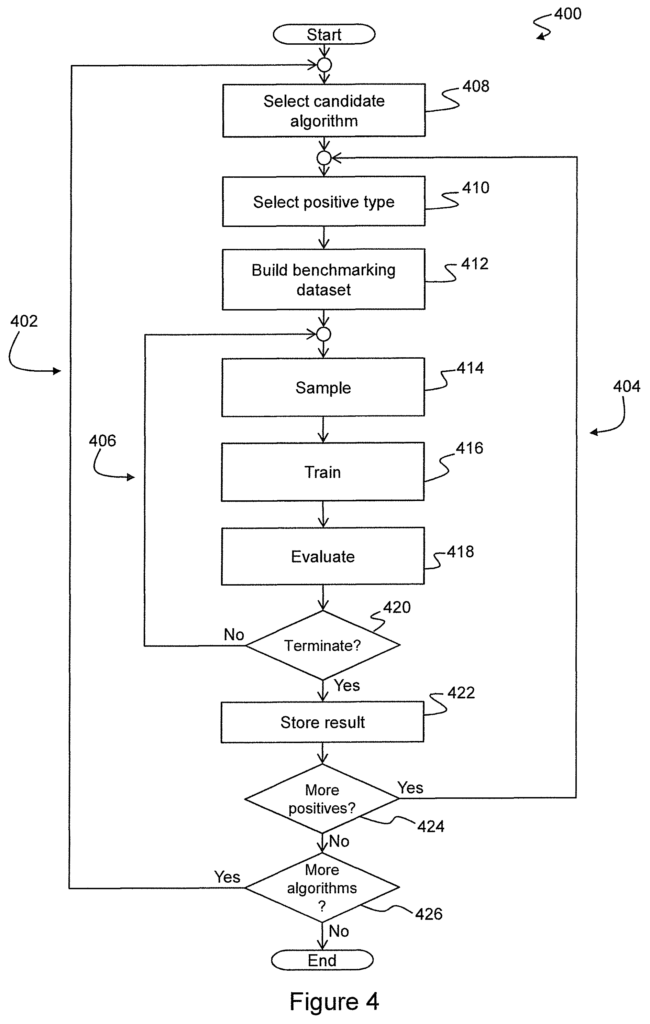
Methods for evaluating and deploying Machine Learning models for anomaly Detection of a Monitored System and Related Systems.” Candidates machine learning algorithms for anomaly detection are configured. A benchmarking dataset is used to create training and cross validation sets for each candidate machine learning algorithm and type of anomalous behavior. A machine-learning algorithm is then trained and validated by using each of the cross-validation and training sets. The performance metric used for this process is the average precision. The mean precision is computed by averaging these performance metrics. The ranking values are computed for the machine learning algorithms that are candidates, and the machine learning algorithms selected based on the ranking values. The machine learning model selected is then deployed to a system monitoring system, which executes it to detect anomalies in the monitored system.
Background for System and Method for Evaluating and Deploying Unsupervised or Semi-Supervised Machine Learning Models
Anomaly” is the term used to describe the detection of new or unusual patterns, also known as outliers, that do not match expected behavior. Anomaly detection is also known as outlier detection or change detection in various contexts. Anomaly detection algorithms are used for intrusion detection, fraud detection, and novelty detection. Fraud detection (e.g. “Identifying suspicious patterns in transaction data or credit card data.
Recent advances in machine-learning algorithms and technologies has resulted in a more widespread deployment of machine-learning models for anomaly identification. To ensure they are accurate and effective at detecting anomalous behavior in the systems they monitor, it is crucial that these models are configured and evaluated critically. It is therefore necessary to develop systems and methods for evaluating machine learning models for anomaly detection.
Many machine learning systems are classified as either “supervised” or “unsupervised”. Unsupervised or supervised. A supervised system uses a labeled dataset to train an machine learning model that can distinguish between different classes of data. ?normal? Data samples labelled ‘negative’, or abnormal/anomalous samples labelled ‘positive’. It is advantageous to keep portions of the labeled dataset for the purpose of optimising the machine-learning model (cross validation) and evaluating the performance of a model trained (testing). Unsupervised systems are those in which there is no suitable labelled dataset and that must distinguish between classes of data without prior training. Semi-supervised systems fall between these two categories. Semi-supervised systems combine unlabelled samples with a smaller number of labelled samples to train a machine learning algorithm.
Machine learning systems can face particular challenges when it comes to anomaly detection. Outlier events are rare by definition. In a production environment, it may not be possible to define or identify ‘normal’. In a production environment, it may be impossible to identify or define?normal? In advance, you can predict the behaviour of one or more classes of?anomalous? In these cases, there are no large datasets that can be used for supervised learning and model evaluation. The problem is how to compare and evaluate the performance of unsupervised and semi-supervised algorithms for anomaly detection, which are based on limited human-labeled data and may include several types of anomalies.
It is desirable to develop new and improved methods, systems, and tools for evaluating, comparing, and deploying machine learning models in anomaly detection.
In one aspect, embodiments provide a method for evaluating and deploying machines learning models to detect anomalies in a monitored system. The method comprises providing a plurality machine learning algorithms configured to detect anomalies in the monitored system. It also includes providing training data, which include a pool negative data samples that represent normal activity on the monitored system as well as one or more smaller data pools. Each pool of samples of positive data represents a different type of anomalous behavior of the monitored system. A benchmarking dataset for each type of anomalous behavior is created. This includes a number of samples taken from the negative sample pool and a number of samples taken from the positive sample pool that corresponds to the type of abnormal activity. The first number is significantly larger than the second. The average precision is used as a performance measure for each of the multiple training and validation sets. Each cross-validation sample consists of a mixture of positive and negative data samples. A ranking value for each candidate machine-learning algorithm is calculated based on at least the average precision values computed by the algorithm candidate for each type anomalous activity. The method also includes selecting from among the candidate machine-learning algorithms, a model that is based on the ranking values. A machine learning algorithm based on this selected algorithm is then deployed to a monitoring device. The monitoring system then executes the machine learning model deployed to detect anomalies in the monitored system.
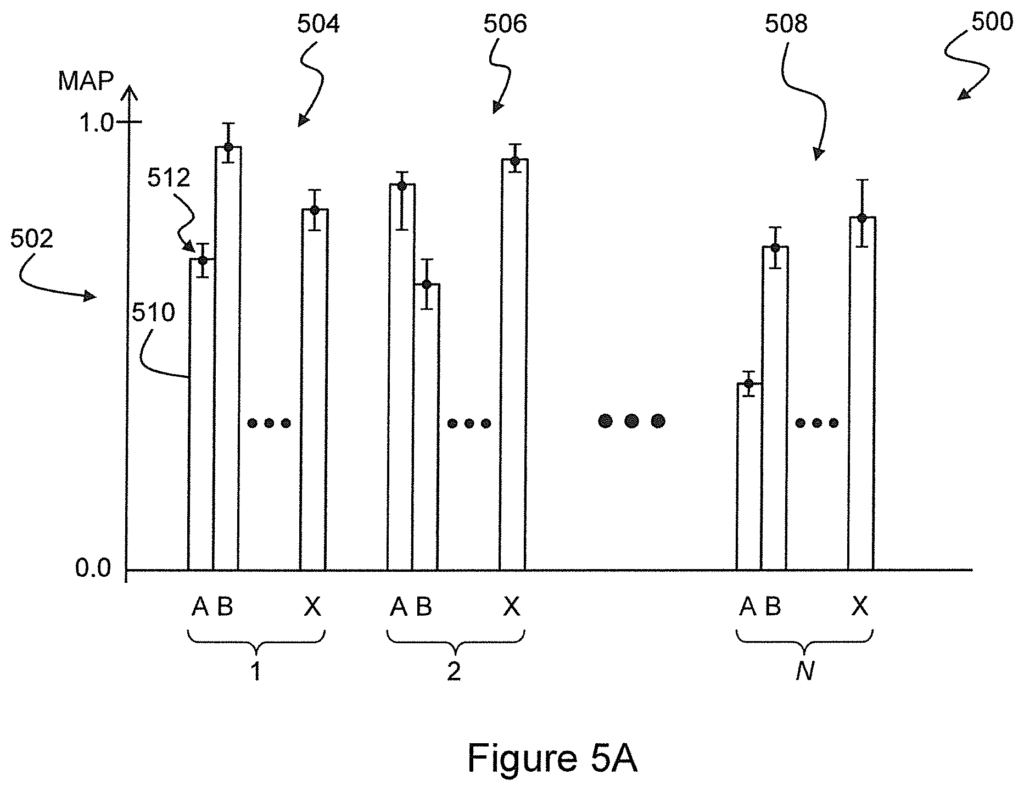
It is advantageous that embodiments of the present invention can evaluate the performance and accuracy of machine-learning algorithms for detecting anomalies. By using mean average precision to evaluate performance and creating benchmarking datasets that are suitable for each type anomaly, the invention is able provide a fair assessment even when there are few data samples. By constructing multiple cross-validation and training sets from each benchmarking data set, and by performing multiple validations to compute the mean standard precision metric, this variability is reduced. This provides stability between evaluation runs.
The ratio of negative samples to positive samples should be fixed for all benchmarking datasets. The benchmarking datasets can be compared fairly by maintaining a constant ratio between negative and positive samples, even if the number of samples available for each type of anomaly is different.
The ranking values should be computed using a rank-aggregation algorithm that uses a Spearman?s footrule measure and a selection of importance values to represent the relative importance of different types of anomalous activities. This approach is advantageous because it allows the performance of machine learning algorithms to uniquely be compared and ranked for all anomaly types. A model can then be selected that has the best overall performance, while taking into consideration that different types may have different ranges of average precision. Performance on some types of anomaly is more model-dependent than other types, and that different types may be of different significance.
In another aspect of the invention, embodiments provide an anomaly detector system configured to work in accordance with this method. A computing system for evaluating machine-learning models for anomaly identification of a monitored device is also provided. The computer system includes at least one memory accessible by processor, as well as at least one data storage accessible by processor. It contains a plurality candidate machine learning algorithms configured to detect anomalies in the monitored system, along with training data that includes a pool negative data samples, which represent normal activity for the monitored system, and one or several smaller pools of data samples. Each pool of samples of positive data represents a different type of anomalous behavior of the monitored system. The memory device contains program instructions that, when executed by a processor, cause the computer system to generate, for each type anomalous activity, a benchmarking dataset consisting of a first number samples drawn out of the pool negative samples and a second amount of samples taken from the pool positive samples. The first number is significantly larger than the second. The program body instructs the computing system, for each combination, to draw a plurality training and a cross-validation dataset from the benchmarking data corresponding with type of anomalous activities, train a model of machine-learning based on the algorithm, using the training set, and validate the model of machine-learning using the cross validation set, using average precision as a performance metric, and calculate a mean value of average precision for the candidate algorithm across all the average precision performance metrics obtained by using each of the plurality Each cross-validation and training set contains a mixture of positive and negative data samples. The program body instructs the computer to calculate a ranking value for each machine learning candidate algorithm based on the average precision values for each type anomalous activity computed by the machine learning candidate algorithm.
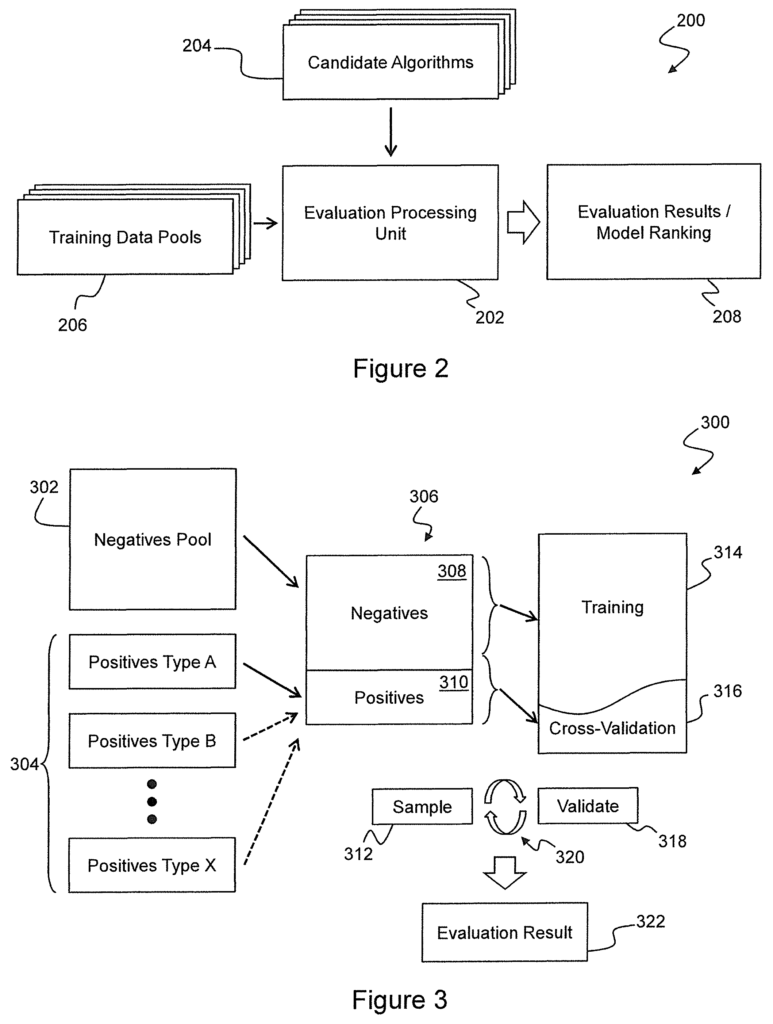
In a further aspect, the invention provides an computer program product that comprises a tangible computer readable medium with instructions thereon. When executed by a CPU, these instructions implement a method which includes accessing a plurality machine learning algorithms (204) configured to detect anomalies in a monitored system, and accessing the training data (206), including a collection of negative data samples (302), representing the normal activity of the system monitored, and one or several smaller collections of positive data samples (304. Each pool of samples of positive data represents a different type of anomalous behavior of the monitored system. A benchmarking dataset (306) is created (412) for each type of abnormal activity. The benchmarking dataset comprises a number of negative data samples and a number of positive data samples that correspond to the type of activity. The method comprises drawing (414) a plurality training and a cross-validation dataset (314, 316) from the benchmarking data corresponding to the type of abnormal activity. Each training set contains only negative data samples and each cross validation set includes a mixture of negative and positive samples. For each of the plurality training and a cross-validation, the method comprises training (416), a machine-learning algorithm based on a selected candidate machine-learning algorithm, using the training data set and validating (418), using the cross validation set. The method includes calculating (608) for each candidate machine-learning algorithm a ranking value that is based on at least the average precision values calculated for the candidate algorithm for each type anomalous activity.
The following description of different embodiments will reveal to those skilled in the relevant art, additional aspects, benefits, and features. The invention is not restricted to the described embodiments.
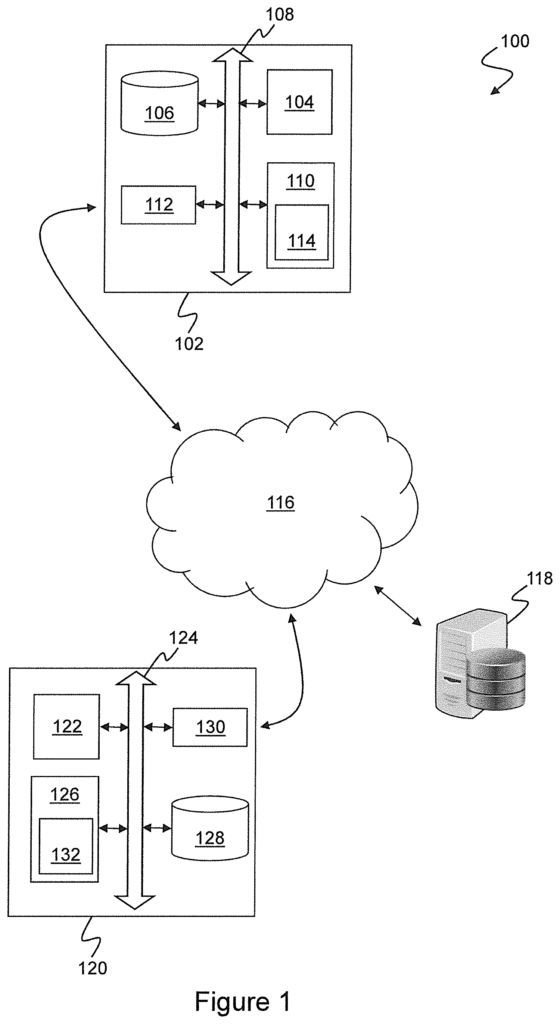
FIG. Block diagram 1 illustrates an example networked system, 100, including an evaluation system, 102. This system is configured to implement, according to an embodiment of the invention, a method for evaluating and deploying unsupervised or semisupervised machine learning models. The evaluation system may be a computer system with a conventional architecture. The evaluation system 102 as shown in the illustration includes a processor. The processor 104 can be operated in conjunction with a nonvolatile storage device/memory 106. As shown, the processor 104 is operably associated with a non-volatile memory/storage device 106 via one or multiple data/address buses 108. Non-volatile storage may be a disk drive and/or solid-state memory such as flash memory, SSD, ROM or other solid-state memory. The processor 104 also interfaces to volatile storage 110 such as RAM which contains transient data and program instructions relating to operation of evaluation system 102.
In a conventional configuration the storage device 106 contains known data and program content that is relevant to the normal functioning of the evaluation system. The storage device 106, for example, may include operating system data and programs, as well executable applications software required to perform the functions of the evaluation 102. The storage device 106 contains also program instructions that, when executed by processor 104, cause evaluation system 102 perform operations related to an embodiment the present invention. These are described more in detail below and with reference FIGS. In particular, FIGS. 2 to 6. “In operation, data and instructions stored on the storage device are transferred to the volatile memory 110 on demand.
The processor 104 can also be operated in a traditional manner with a communication interface 112. The communications interface 112 allows access to a wide area data communication network such as the Internet 116.
When used, the volatile memory 110 contains a body 114 of corresponding program instructions that have been transferred from the storage device and are configured to perform operations and processing embodying the features of the invention. The program instructions 114 are a contribution to the technology, developed and configured to implement a particular embodiment of the present invention. This is in addition to routine and conventional activities within the field of machine learning, which will be described further below. “2 to 6.
The following is a list of terms that should be taken to refer to various possible implementations, including devices, systems, and apparatus, which combine hardware and software. It includes both single-processor systems and multiprocessor systems. This includes portable devices, desktop computer, and different types of server system, as well as cooperating hardware platforms and software platforms, which may be located in the same place or distributed. Physical processors can include general-purpose CPUs, digital signals processors (DSPs), graphics processing units(GPUs), or other hardware devices that are suitable for the efficient execution of programs and algorithms. Computing systems can include general-purpose hardware platforms or conventional computer architectures. Software may include open-source and/or commercially-available operating system software in combination with various application and service programs. Computing or processing platforms can also be custom-built hardware and/or based on software architectures. Cloud computing platforms can be used to increase scalability and allow physical hardware resources that are allocated dynamically based on service demand. All of these variations are within the scope and spirit of the invention. However, to make the description easier, exemplary embodiments will be described with reference to widely available consumer products such as desktop or laptop computers, common operating systems, smartphones, tablets, etc.
In particular, “processing unit” is used in this specification to refer to any suitable combination of hardware and software configured to perform a specific defined task. For example, accessing and processing offline or online data, executing training steps of a machine learning model (or evaluation steps), or executing anomaly-detection steps for a machine learning model. In this specification, the term “processing unit” is used to describe any combination of hardware with software that can perform a specific defined task. Examples include accessing and processing online or offline data, performing training steps for a model of machine learning, performing evaluation steps for a model of machine learning, or executing anomaly detection steps in a model of machine learning. This processing unit can be a code module that executes at a specific location on a particular processing device or it could include cooperating code modules that execute in different locations and/or multiple processing devices. In some embodiments, the evaluation of machine-learning algorithms can be done entirely by code running on a single system 102. However, in other embodiments, the processing can be distributed across multiple evaluation systems.
Software components, e.g. The program instructions 114 that embody the features of the invention can be created using any programming language or development environment. Combinations of languages and environments are also possible, as is well known to software engineers. Software suitable for machine learning algorithms can be developed, for example, using the C language, Java, C++, Go, Python, R, or other suitable languages. Various languages can be used to implement network and/or web services, including the ones already mentioned and others like JavaScript, HTML PHP, ASP JSP Ruby Perl and so on. The examples provided here are not meant to be restrictive, and any suitable languages or development systems can be used, depending on the system requirements. These descriptions, block diagrams and flowcharts are presented as examples to help those who have knowledge of software engineering, machine learning and other related fields to better understand the nature and scope of this invention. They can then implement one or more embodiments by implementing suitable software code in accordance with the disclosure using suitable languages, frameworks and libraries.
Continued discussion of FIG. The networked system includes a monitored 118. The monitored system 118 can be a database, transaction processing system or information system. It could also be an industrial system or security system. The monitored system 118 can take on a variety of different forms, including centralised and decentralized architectures. The monitoring that embodiments of the invention address is described in a number of ways (e.g. While a variety of terms are used for the type of monitoring to which embodiments of the present invention are directed (e.g. The term “anomaly detection” is used consistently, with the understanding of other terminology being common in the art.
The relevant characteristic of the monitored system is that it generates data (e.g. On-line or offline, the data can be stored or analysed in order to identify events, items or observations that may not follow expected patterns or behaviours. These anomalous patterns and behaviours can be a result of a variety of factors, depending on the nature or the system. “Erroneous or inconsistent database records, fraudulent transactions, attempted or real attacks or security breaches, system errors or performance degradation or imminent or actual equipment failures
Click here to view the patent on Google Patents.
Leave a Reply