Invented by Brian T. Lewis, Feng Chen, Jeffrey R. Jackson, Justin E. Gottschlich, Rajkishore Barik, Xiaoming Chen, Prasoonkumar Surti, Mike B. MacPherson, Murali Sundaresan, Intel Corp
One of the key benefits of autonomous machines in cloud computing is the ability to perform error corrections. Errors can occur in any system, and autonomous machines can quickly identify and correct these errors without the need for human intervention. This can save time and money, as well as improve the overall efficiency of the system.
Another benefit of autonomous machines in cloud computing is the ability to make predictions. These machines can analyze large amounts of data and use algorithms to make predictions about future events or trends. This can be particularly useful in industries such as finance and marketing, where accurate predictions can lead to significant profits.
The market for autonomous machines in cloud computing is expected to grow significantly in the coming years. According to a report by MarketsandMarkets, the global market for autonomous machines is expected to reach $12.8 billion by 2023, with a compound annual growth rate of 22.2%. This growth is being driven by the increasing demand for automation in various industries, as well as the advancements in artificial intelligence and machine learning technologies.
One of the key players in the market for autonomous machines in cloud computing is Amazon Web Services (AWS). AWS offers a range of services for autonomous machines, including Amazon SageMaker, which allows developers to build, train, and deploy machine learning models, and Amazon RoboMaker, which provides a development environment for building robotics applications.
Other companies that are active in this market include Microsoft, Google, IBM, and Intel. These companies are investing heavily in research and development to improve the capabilities of autonomous machines in cloud computing and to expand their market share.
In conclusion, the market for autonomous machines in cloud computing, error corrections, and predictions is growing rapidly. These machines offer significant benefits in terms of efficiency, accuracy, and cost savings, and they are being increasingly adopted in various industries. As the technology continues to advance, we can expect to see even more innovative applications of autonomous machines in the future.
The Intel Corp invention works as follows
A mechanism for smart data collection and smart machine management is described. The method described herein includes detecting data sets from multiple sources via one or several networks and combining them with a first computation to be performed at a local device, with a second calculation to be done remotely at a device that is in communication with the device at the local device.
Background for Autonomous machines in cloud, error corrections and predictions
Current parallel graphic data processing” refers to systems and methods that can perform specific operations on graphics data, such as linear interpolation (linear interpolation), tessellation (rasterization), texture mapping, depth test, etc. Graphic processors were traditionally based on fixed-function computational units for processing graphics data. However, recent developments have made portions of the graphics processors programmable. This allows them to perform a greater variety of operations to process vertex and fragment data.
To increase their performance, graphics processors often implement processing techniques like pipelining, which attempt to process as many graphics data in parallel as possible across the various parts of the graphics pipeline. Parallel graphics processors that use single instruction, multiple thread architectures (SIMT), are designed to maximize parallel processing within the graphics pipeline. SIMT architectures are composed of multiple threads that attempt to execute program instructions simultaneously as many times as possible in order to improve processing efficiency. You can find a general overview of hardware and software for SIMT architectures in Shane Cook’s CUDA Programming Chapter 3, pages 37-51 (2013), and/or Nicholas Wilt’s CUDA Handbook: A Comprehensive Guide to GPU Programming Sections 2.6.2 through 3.1.2 (June 2013).
Machine Learning has been successful in solving many types of tasks. Parallel implementations are possible because of the complexity of machine learning algorithms, such as neural networks. Parallel processors, such as general-purpose graphics processing units (GPGPUs), have been a key part in the implementation of deep neural network. The parallel graphics processors that have a single instruction, multiple thread architecture (SIMT), are intended to maximize the number of parallel processing within the graphics pipeline. SIMT architectures are composed of multiple parallel threads that attempt to execute program instructions as quickly as possible. This increases processing efficiency. Parallel machine learning algorithm implementations provide high efficiency and allow for the use of large networks.
Conventional techniques of autonomous driving perform their computations within vehicles. This negatively impacts the system performance and latency, because there is a limited amount power available to any vehicle. In addition, in order to fix error codes using conventional techniques, experts must be familiar with the electrical components, fuels, etc. of specific car models. The conventional route guidance techniques also optimize routes by taking into account the current state of vehicle components and parts, like battery.
Embodiments allow for the combination of in-vehicle engine with cloud-based system to achieve faster and more efficient calculations. Further, embodiments provide automatic decoding and error fixing. Embodiments also provide dynamic optimization of routes, based on the current status or historic knowledge of vehicle components and parts, such as battery health, etc. This document may use terms and acronyms such as ‘convolutional neural networks? ‘, CNN?, ‘neural networks?, NN?, deep neural networks?, DNN?, recurrent neural nets?, RNN? or the like. Further, terms such as ‘autonomous machine’ and?autonomous vehicle? Or simply’machine’,?autonomous car? Or simply “vehicle” or “autonomous agent?” or simply ?agent?, ?autonomous device? “Computing device”, “robot”, and/or similar terms may be used interchangeably throughout this document.
In certain embodiments, a graphics processor unit (GPU), is communicatively coupled with host/processor cores in order to accelerate graphics operations and machine-learning operations. This allows for pattern analysis operations and other general purpose GPU functions. The GPU can be communicatively connected to the host processor/cores via a bus, or another interconnect (e.g. a high-speed interconnect like PCIe or NVLink). Other embodiments may integrate the GPU on the same package/chip as the cores. The GPU can also be communicatively connected to the cores via an internal bus/interconnect (i.e. internal to the package/chip). Regardless of the manner in which the GPU is connected, the processor cores may allocate work to the GPU in the form of sequences of commands/instructions contained in a work descriptor. The GPU then uses dedicated circuitry/logic for efficiently processing these commands/instructions.
In the following description are numerous specific details. But embodiments as described in this document can be implemented without these details. Other times, well-known structures, circuits and techniques are not shown in full detail to avoid obscuring the understanding of the description.
System Overview I
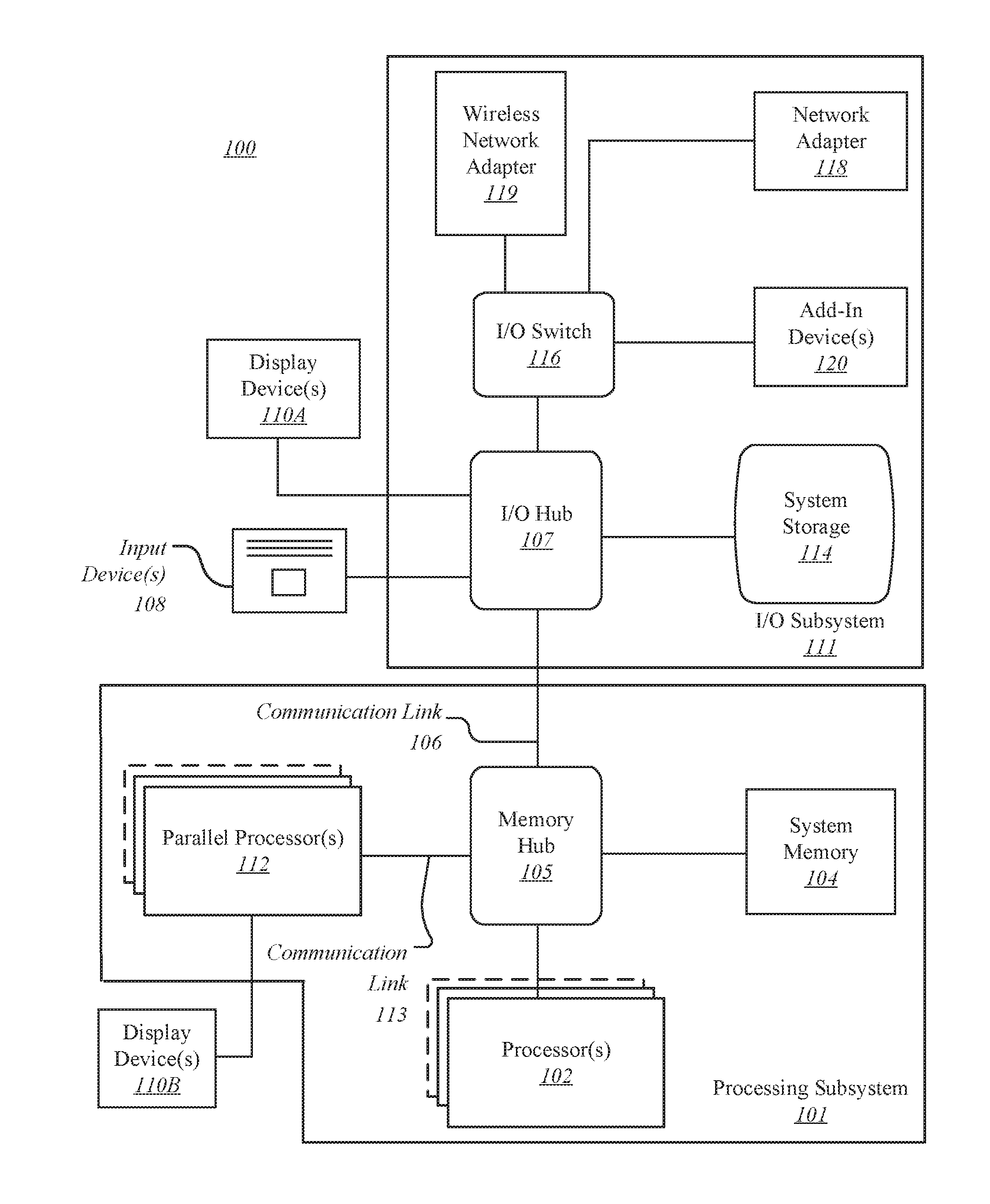
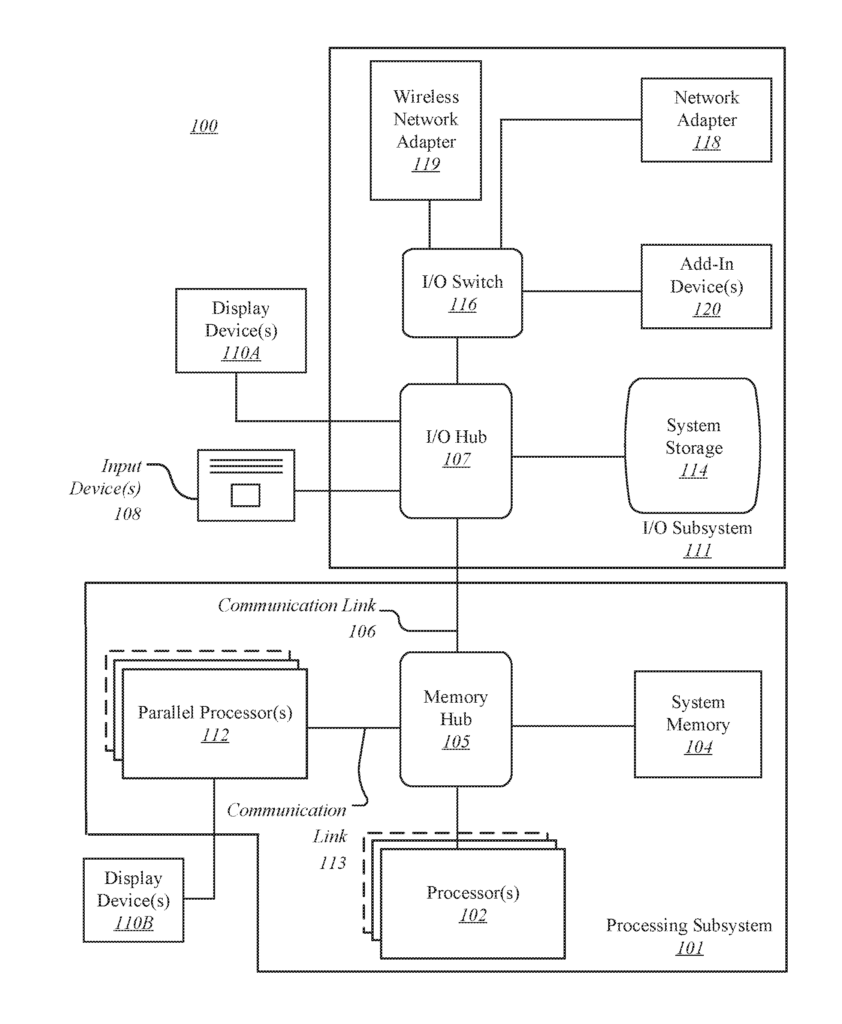
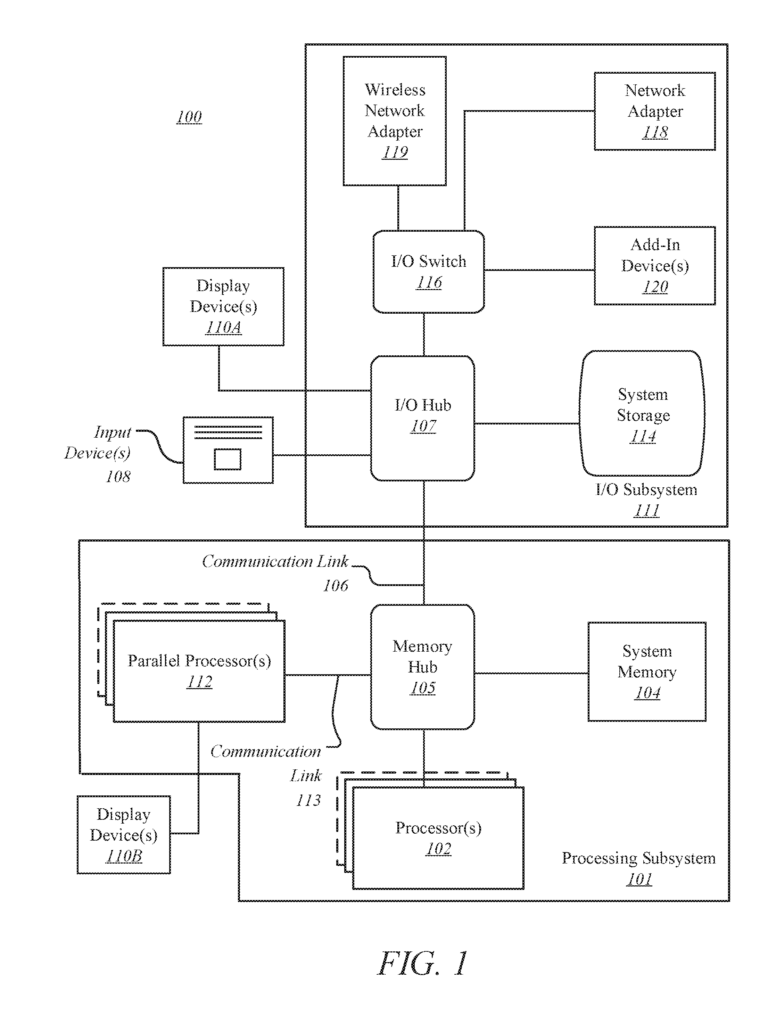
FIG. “FIG. A processing subsystem 101 is included in the computing system 100. It includes one or more processors 102 and a system storage 104. They communicate via an interconnection path, which may include a memory hub (105). The memory hub 105 can be either a separate component of a chipset or integrated into the processor(s) 102. Through a communication link 106, the memory hub 105 can be connected to an I/O system 111. I/O subsystem 111 also includes an I/O hub 107 which can allow the computing system 100 receive input from one or multiple input devices (108). The I/O hub (107) can also enable a display controller to be connected to the processor(s). 102 to provide outputs to the display device(s). 110A. One embodiment of the I/O hub107 and one or more display devices 110A can be combined with an embedded, local, or internal display device.
One embodiment of the processing subsystem 101 comprises one or more parallel processors 112 connected to memory hub 105 via bus or another communication link 113. The communication link 113 can be any of a variety of standards-based communication link protocols or technologies, including PCI Express. It may also be a vendor-specific communications interface or fabric. One embodiment of the parallel processors 112 forms a parallel processing system or vector that is computationally focused. It may include many processing cores or clusters such as multiple integrated core (MIC), processors. One embodiment of the parallel processors 112 forms a graphics processing subsystem that can output pixels one the one or multiple display devices 110A connected via the I/O Hub.107. One or more parallel processors 112 may also include a display controller or display interface (not illustrated) in order to allow direct connection to one of the display devices 110B.
In the I/O subsystem 112, a system storage device 114 can be connected to the I/O hub107 to provide a storage system for computing system 100. An I/O switch (116) can be used as an interface mechanism to allow connections between I/O hub107 and other components. This includes a network adapter/wireless network adapter (118/119), which may be integrated into platform, and many other devices that can added via add-in devices 120. The network adapter (118) can be either an Ethernet adapter, or another wired networking adapter. Wireless network adapter 119 may include one or several of Wi-Fi, Bluetooth or near field communication (NFC) devices or any other network device that includes one, or more, wireless radios.
The computing system 100 may include additional components that are not shown. These could include USB or other ports connections, optical storage drives and video capture devices. The communication paths connecting the components of FIG. 1. may be implemented using any of the suitable protocols, including PCI (Peripheral Complement Interconnect) based protocols (e.g. PCI-Express) or any other bus/point-to-point communication interfaces or protocols(s), like the NV Link high-speed interconnect or interconnect protocols that are known in the art.
In one embodiment, one or more parallel processors (112) incorporate circuitry optimized to graphics and video processing. This circuitry includes, for example video output circuitry and constitutes a graphic processing unit (GPU). Another embodiment uses circuitry that is optimized for general purpose processing. This preserves the underlying computational architecture. Another embodiment allows components of the computing systems 100 to be combined with other elements in a single integrated circuit. One or more parallel processors, 112 memory hub 105 and processor(s) 102 can all be integrated into a single integrated circuit. The components of the computing systems 100 can also be combined into one package to create a system-in-package (SIP) configuration. One embodiment allows at least one portion of the computing system 100 to be integrated into a multichip module (MCM), which can then be interconnected with other multichip modules to create a modular computing platform.
It will be understood that the computing system 100 illustrated herein is only an illustration and that modifications and variations are possible. You can modify the connection topology including the number and arrangement for bridges, processor(s), 102, and parallel processor(s), 112, as needed. In some cases, system memory (104) is directly connected to processor(s), 102 via a bridge. Other devices, however, communicate with system memory (104) via the memory hub and processor(s), 102. Other topologies allow the parallel processor(s), 112, to be connected to either the I/O hub107 or directly one or more of the processor(s), 102 rather than the memory hub105. Other embodiments may include the I/O hub (107) and memory hub (105), which can be combined into one chip. One embodiment may have two or more processor(s), 102 connected via multiple sockets. These processors can be paired with one or more instances the parallel processor(s), 112.
Some components listed herein may not be available in all versions of the computing system 100. You may support as many add-in cards and peripherals as you like, or eliminate certain components. Other architectures might use different terminology for components than those shown in FIG. 1. In some architectures, the memory hub (105) may be called a Northbridge, while the I/O center 107 may be called a Southbridge.
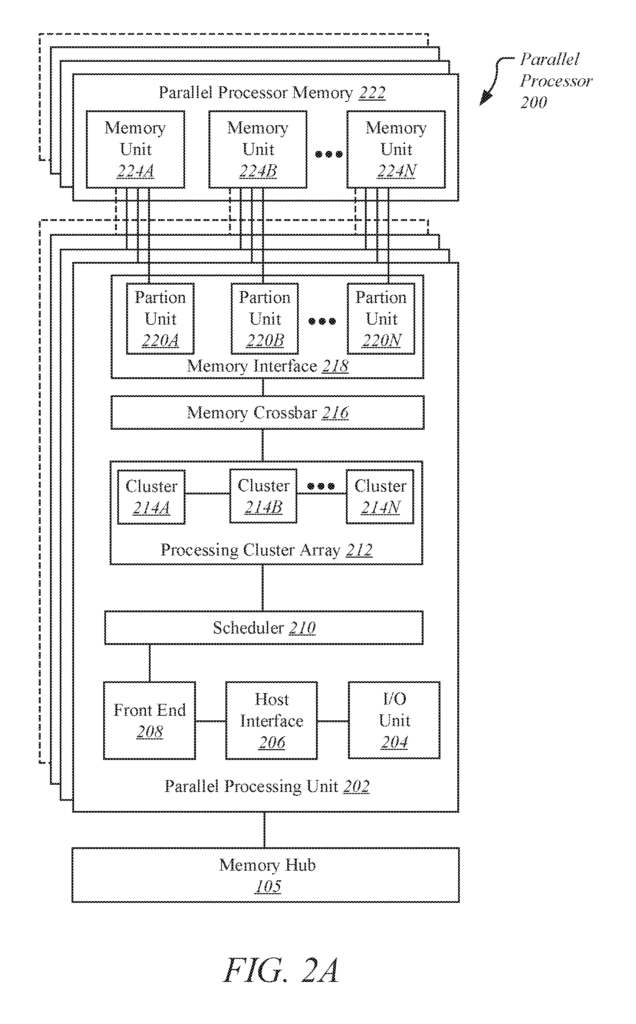
FIG. 2A shows a parallel processor 200 according to an embodiment. One or more integrated circuit devices may be used to implement the various components of the parallel process 200, including programmable processors, field-programmable gate arrays or application-specific integrated circuits (ASICs). The parallel processor 200 illustrated in FIG. 1. According to an embodiment
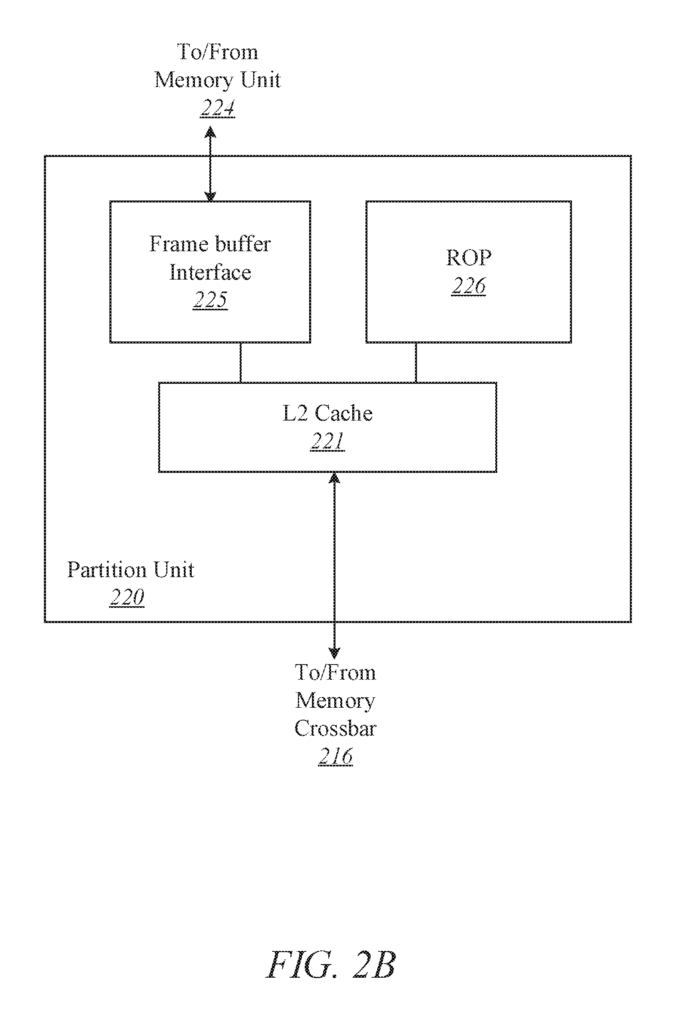
In one embodiment, the parallel process 200 includes a parallel unit 202. A parallel processing unit also includes an I/O 204 which allows communication with other devices, such as other instances of parallel processing unit 200. The I/O 204 can be connected directly to other devices. One embodiment of the I/O device 204 connects to other devices using a switch or hub interface, such memory hub 105. The communication link 113 is formed by the connections between the I/O units 204 and the memory hub 105. The parallel processing unit 200’s I/O unit204 connects to a host interface (206) and a memory crossbar (216). Here, commands are received from the host interface to perform processing operations, while commands to the memory crossbar 226 are directed at performing memory operations.
When the I/O unit 200 sends a command buffer to the host interface, 206, the host interface can direct work operations to the front end 208. One embodiment of the front end 208 is coupled with a scheduler210. This scheduler is used to distribute commands and other work items to a processing array 212. The scheduler 210 in one embodiment ensures that the processing array 212 is correctly configured before tasks are distributed to processing clusters.
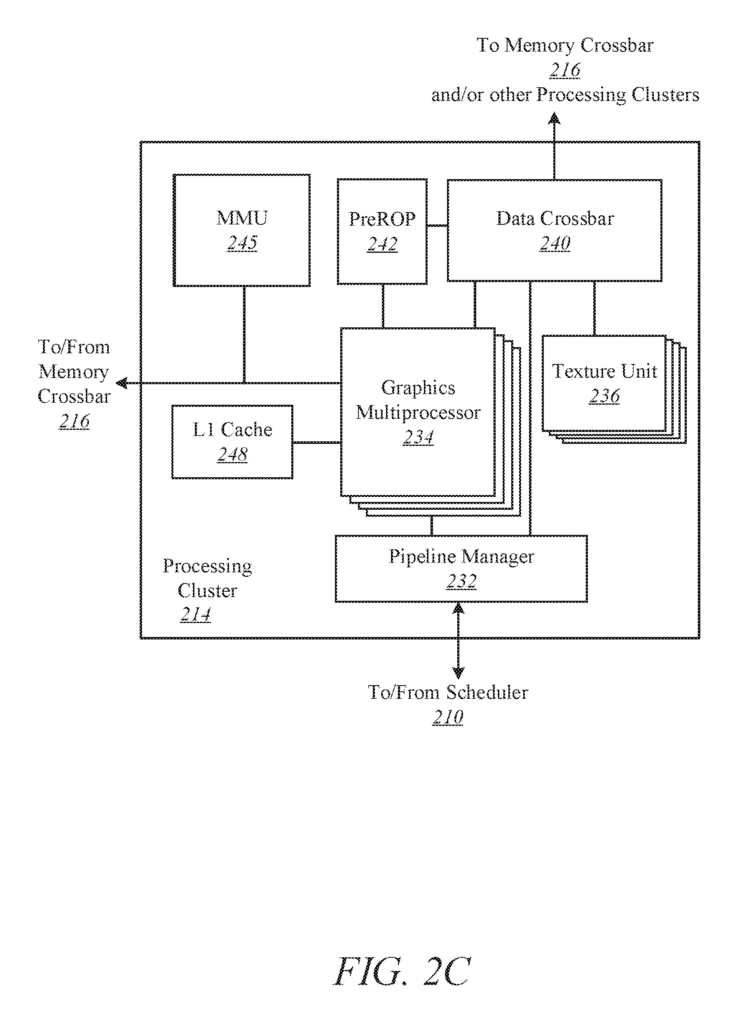
The processing cluster array 212 can contain up to?N” Processing clusters (e.g. cluster 214A and cluster 214B through cluster 214N). The clusters 214A-214N can run a large number concurrent threads. The scheduler 220 can assign work to clusters 214A-214N from the processing cluster array 212, using different scheduling and/or work allocation algorithms. These may vary depending upon the type of program or computation being executed. The scheduler 210 can handle the scheduling dynamically or in part with compiler logic when compiling program logic for execution by processing cluster array 212.
In one embodiment, different processing clusters 214A-214N can be assigned for different types or types of programs.
The processing cluster array 212 can be configured to perform different types of parallel processing operations. One embodiment of the processing cluster array is designed to perform general-purpose parallel computation operations. The processing cluster array 212 may include logic that can be used to perform processing tasks such as filtering video and/or audio, modeling operations including physics operations and data transformations.
Click here to view the patent on Google Patents.
Leave a Reply