Invented by Anush Sankaran, Neelamadhav Gantayat, Srikanth G. Tamilselvam, International Business Machines Corp
Deep learning is a subset of machine learning that uses neural networks to analyze and learn from large amounts of data. This technology is particularly useful for modeling user behavior and preferences, as it can identify patterns and make predictions based on past interactions.
Multimodal data refers to data that comes from multiple sources, such as text, images, and audio. By combining these different types of data, companies can gain a more comprehensive understanding of their users and provide more accurate recommendations.
The market for these technologies is driven by the increasing demand for personalized experiences. Customers expect companies to understand their preferences and provide recommendations that are tailored to their individual needs. This is particularly important in industries such as e-commerce, where recommendations can have a significant impact on sales.
One example of a company that is using deep learning and multimodal data to model user profiles is Netflix. The streaming service uses a combination of user data, such as viewing history and ratings, as well as contextual data, such as time of day and device type, to provide personalized recommendations to its users.
Another example is Amazon, which uses machine learning to analyze customer data and provide personalized product recommendations. The company also uses deep learning to improve its voice assistant, Alexa, by analyzing user interactions and improving its ability to understand natural language.
The market for deep learning and multimodal data is expected to continue to grow in the coming years. According to a report by MarketsandMarkets, the market for deep learning is expected to reach $18.16 billion by 2023, while the market for multimodal data is expected to reach $20.63 billion by 2025.
As more companies adopt these technologies, it is likely that we will see more advanced and accurate recommendations. However, there are also concerns about privacy and data security, as companies collect and analyze more personal information about their users.
Overall, the market for deep learning and multimodal data to model user profiles for intelligent recommendations is an exciting and rapidly growing field. As companies continue to invest in these technologies, we can expect to see more personalized and relevant recommendations for consumers.
The International Business Machines Corp invention works as follows
Systems and Methods are provided for implementing intelligent recommendations to users through modeling user profiles using multimodal data. A recommendation computing platform, for example, collects multimodal data from the computing device of registered users. The multimodal data includes time-series, unstructured texts, and multimedia. A first deep-learning classification engine is used to extract features from multimodal user data. On the basis of the extracted features, a second deep learning engine generates a profile for the registered user. A deep recommendation engine is used to determine a recommended user for the registered person based on their profile, and the recommendation identifies a minimum of one additional registered person. The recommendation is displayed to the registered users on their computing devices.
Background for Deep learning and multimodal data to model user profiles for intelligent recommendations
In various applications, information from user profiles is used to identify interests and make recommendations. Online matchmaking applications for dating and matrimonial purposes, for example, perform compatibility analysis for individuals or groups based on predefined attributes. These attributes are usually collected by using a questionnaire template, where users self-identify their responses to different questions. The conventional recommendation systems which use compatibility determination techniques using self-identified answers to questionnaire templates can often lead to incomplete or insufficient information about user preferences and interests, leading to ambiguity. Conventional questionnaire templates, for example, encourage users to lie about their attributes in order to influence the desired outcome. Moreover, recommendation systems depend on subject matter experts for identifying important attributes or explicit user feedback. These techniques are not effective in building user profiles that truly reflect user interests, for the purposes of accurate compatibility analyses and other intelligent recommendations.
The invention includes systems and methods that provide intelligent recommendations by modeling user profiles using multimodal data. One embodiment, for example, includes a method that comprises: collecting multimodal data from one/more computing devices of a registered user of a recommendation computing system, wherein said multimodal data comprises time-series, unstructured texts, and multimedia; using the first deep learning engine to extract features; using the second deep learning engine to create a profile of registered user using the extracted features; and using a deep recommendation engine to determine atleast one recommendation for registered user using the profile, wherein atleast one recommendation comprises identification of another registered on the recommendation computing platforms;
The following detailed description of embodiments should be read together with the accompanying figures.
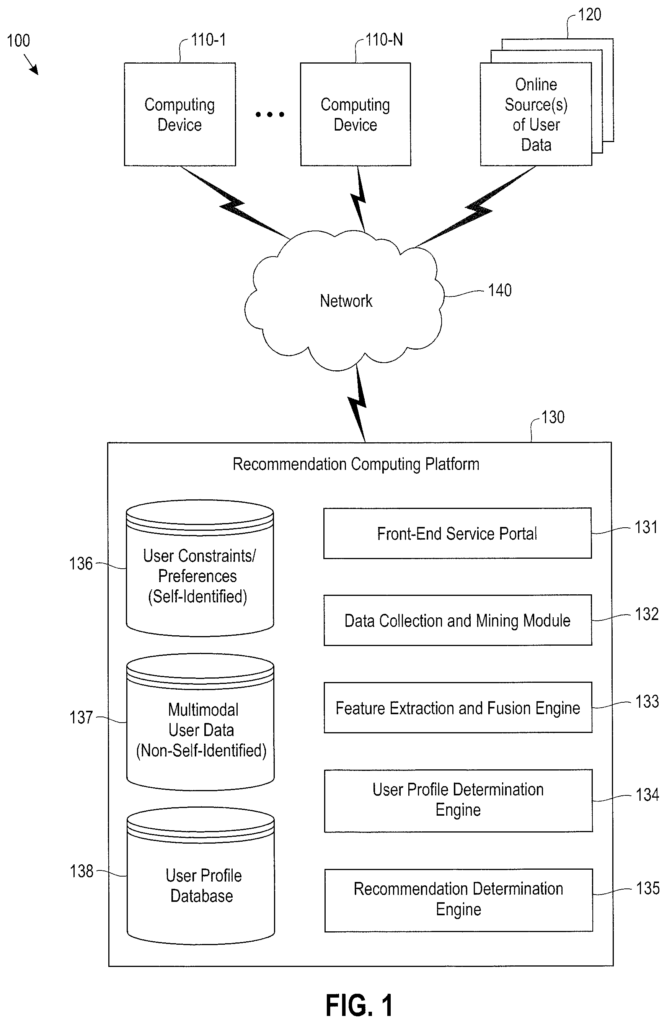
Embodiments” will be discussed in detail now with regards to systems and methods of providing intelligent recommendations to the users by modeling user profile through deep learning multimodal data. As an example, FIG. According to one embodiment, FIG. 1 shows a computing device 100 configured to make intelligent recommendations based on user profiles created through deep learning from multimodal data. Computing system 100 includes a plurality computing devices 110-1. . . The recommendation computing platform 130 is composed of various computing modules including, but not limited to, a front-end service portal 131, a user data collection and mining module 132, a feature extraction and fusion engine 133, a user profile determination engine 134, as well as a recommendation determination engine 135. The recommendation computing platform comprises various computing components, including but not limited, to a front-end portal 131, an online data mining module 132 a feature extraction engine 133 a user profile engine 134 and a recommendation engine 135 The recommendation platform 130 further comprises a plurality of databases/data stores including, but not limited to, a database of self-identified user data 136 (e.g., user-specified preferences/constraints), a database of non-self-identified user data 137 (e.g., multimodal user data), and a database of user profiles 138.
The communications network 140 can be any type of network or combination of networks, such as the Internet, a global computer system (e.g.), a wide-area network (WAN), local area networks (LAN), satellite networks, telephone or cable networks, cellular networks, wireless networks such as WiMAX or WiFi, or different portions or combinations thereof. Computing devices 110 include smart phones, watches, electronic tablets, laptops, and other smart wearable devices. These devices serve as data sources of multimodal user data, which are collected by the recommendation computing platform to create user profiles for registered users. Online sources of data 120 include social network websites, e mail servers, user blogs and other online sources that can be accessed to collect data from registered users.
The recommendation computing platform is generally configured to collect different types of multimodal data from users and use deep learning techniques (i) to extract features to create user profiles and (ii), to process user profiles in order to provide intelligent suggestions to registered users. The recommendation computing platform is shown in FIG. While FIG. 1 is shown for illustration purposes, it should be understood that computing modules 131, 132, 133, 134, and 135 may be distributed across a plurality computing nodes (e.g. a cluster or virtual machine, etc.). The functions described in this document are implemented by a group of computing nodes that work together. The databases 136,137,138 can be implemented with any type of database (e.g. SQL, non-SQL etc.). The data storage system can be any combination of data-storage systems including storage area networks (SANs), direct attached storages (DASs), serial attached storages (SAS/SATAs), or other types.
In this respect, the recommendation computing platforms 130 can be implemented as a cloud computing system or in a datacenter that performs computing and storage functions for one or more intelligent recommendations applications (consumer applications or business applications), to provide services to a variety of end users, service providers and/or organisations. The recommendation computing platform 130, for example, can be configured to offer a variety of services, including but not limited, to targeted advertising to end users and insurance recommendations, as well as banking recommendations, such eligibility for a credit card or loan. “), immunity detections, (disease analyses), compatibility analysis, and recommendations for online matrimonial dating, roommate matching etc.
The computing modules 131, 132, 133, 134, and 135 perform a variety of functions in order to provide intelligent recommendation services for registered users. The front-end service platform 131, for example, is configured to implement interfaces to enable computing devices 110 connect to and communicate with recommendation computing platform 120, as well as user interfaces to enable users to access and register with services provided by the recommendation computing platforms 130. In order to facilitate user registration, the front-end portal 131 can be configured to present a questionnaire, or ask a set of questions, that will allow the user to express their interests, preferences and conditions. These responses may include contact information, geographic location (e.g. residence location), education, occupation, hobbies, personality characteristics, qualities, etc. as well as explicit criteria that will be used in a recommendation analysis. In social matching applications, the explicit user constraint could be that a user wants to be matched up with someone who is not older than a particular age or does not smoke. The self-identified responses which are provided by a user during an initial user registration process, or which are modified/updated at some time after the initial registration, are stored in the user constraints/preferences database 136 and associated with a user identifier (ID) of the registered user.
The data mining and collection module 132 includes methods configured to collect/mine multimodal user data from various sources and identify information about the user that could be useful and relevant in determining an individual profile. The example embodiment of FIG. is described in greater detail below. The multimodal user data 2 includes various types of data from users, such as unstructured text, multimedia, and time series data. Multimodal user data is collected from computing devices 110, and online sources of data of registered users 120. “The multimodal data that is deemed useful and relevant in determining profiles of users are stored in a database of multimodal data 137, and are associated with registered users using their registered IDs.
The recommendation computing platform 130 may download client-side software onto the computing devices 110 during the registration process to facilitate and support the data mining and collection functions of the data mining module 132. Client-side software can include cookies, tracking scripts and client side agents. These are all configured to track user actions and perform data analysis functions in support of the data collection operations described herein. The client-side software may be configured to process data generated or stored by the user computing devices, such as, for example, a user?s email and phone contacts, call logs and related data, geolocation data, and user interactions in social networks. The following sections will discuss in greater detail the various types of multimodal data that can collected and used by the recommendation computing platform. 2.
![]()
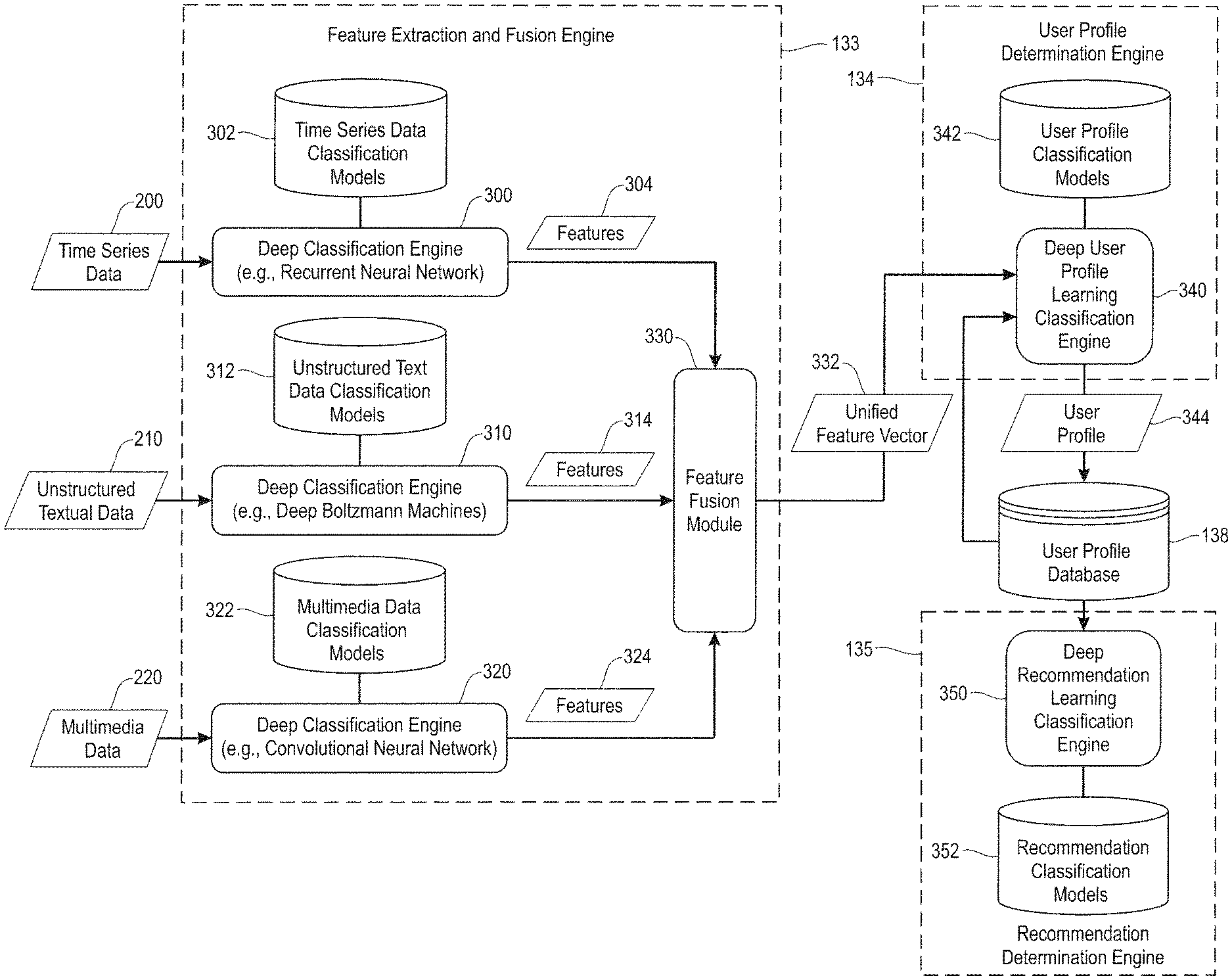
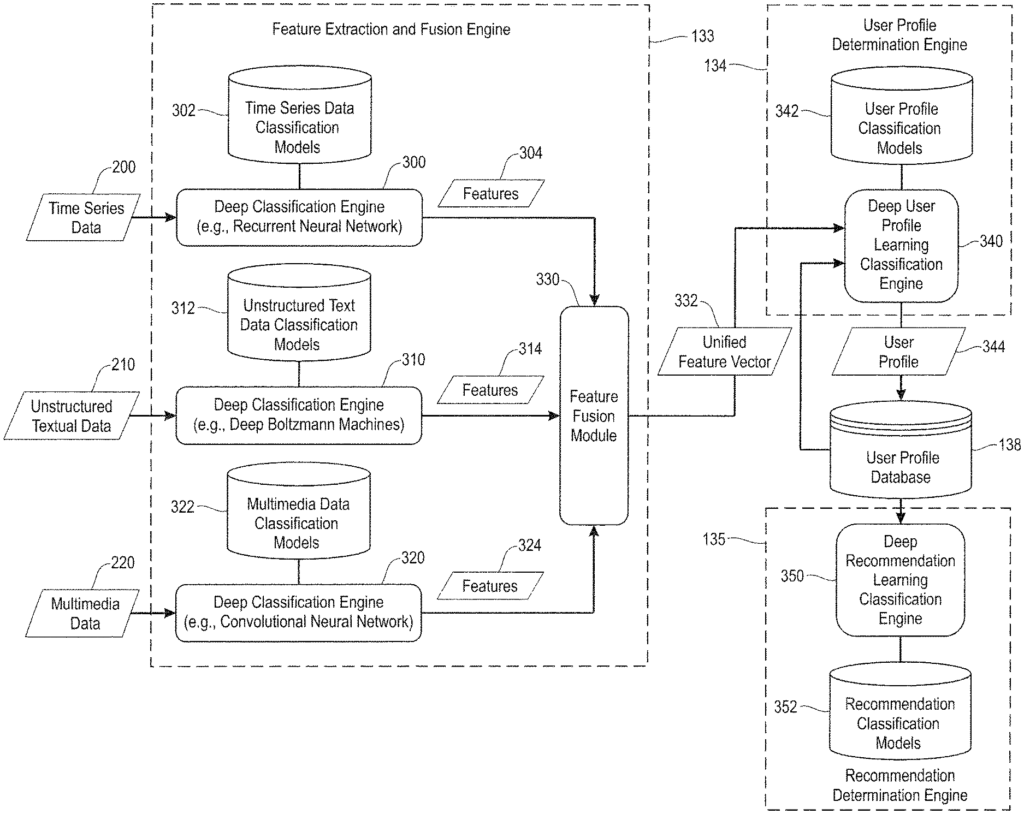
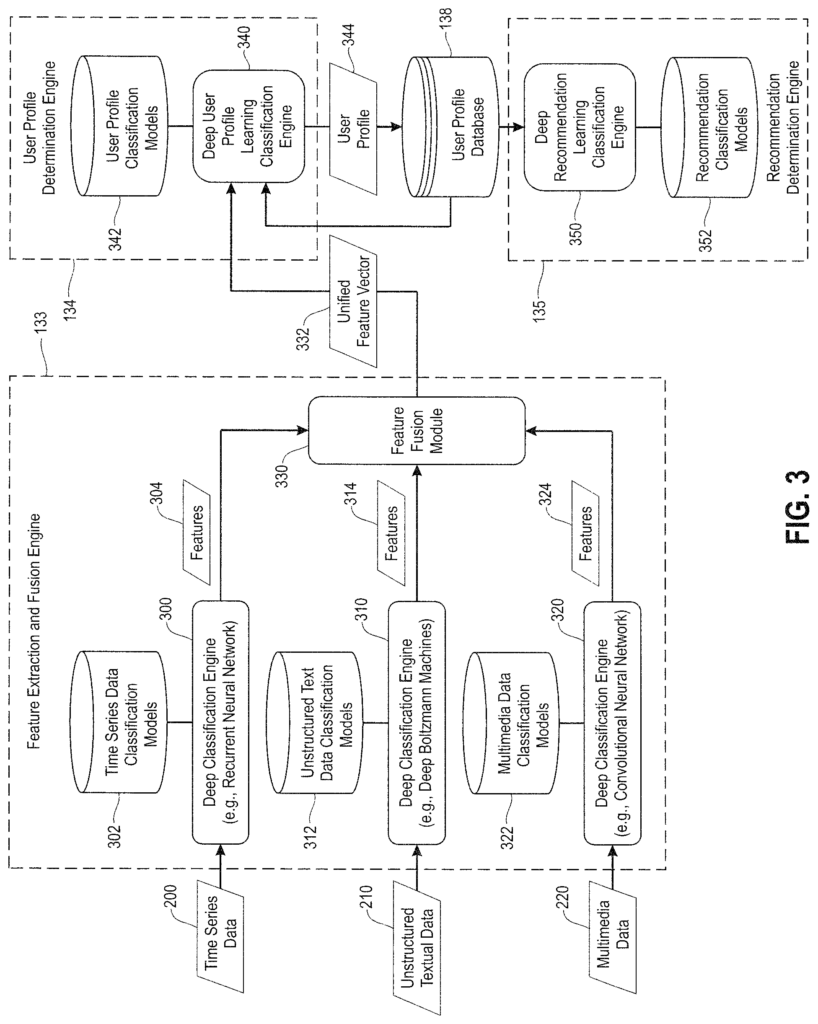
The feature extraction and fusion engines 133 are configured to perform deep classification analysis on the multimodal data collected from a registered user and stored in a database of multimodal users data 137 to extract features indicative of preferences, activities, and interests of a user, even if they are not self-identified. In one embodiment, for example, different deep learning techniques are used to process different types multimodal user data. To generate feature sets for every type of multimodal data. The feature extraction and fusion engines 133 also include methods configured to perform feature-level fusion in order to aggregate/combine the corresponding features generated by each of the deep learning classification techniques. This results in a multidimensional vector of features that provides a representation of the user?s preferences, interests, activities, etc. based on extracted feature.
As explained below, “the feature extraction methods” are implemented using different types deep classification techniques that are applied to different types multimodal data in order to extract multiple features of deep personality traits, which are indicative of an individuals preferences, activities and interests. These include, but are not limited to assertiveness and ambition, as well as emotional responses, opinions and interests, religious beliefs, and other patterns and behaviors of users. Other features relevant for assessing a person’s preferences, hobbies, and interests include information about (i) health awareness (e.g. food types, eating patterns, frequency of doctor/dentist appointments, etc.). Then there are verbal behaviors, such as interactions with others, language and vocabulary, or financial behaviors, like thriftiness, spending patterns, debts, entrepreneurial activities, etc. This can be determined by a deep classification of user data, including but not limited, to call logs and online chats. Text messages, emails, blogs, posts on the internet, locations visited, calendar activities etc.
The user profile determination engine comprises methods configured to generate profiles of registered users using features extracted from multimodal data. In one embodiment, as discussed below in more detail, the user profiles determination engine 134 uses deep learning techniques to classify the preferences, activities and interests of a registered user. The model is then stored in the database of user profiles 138, along with the ID of the registered users. The profile of any registered user may be updated over time based on the changes in the user’s behavior (physical and mental). This is learned by capturing and processing new multimodal data.
The recommendation determination engine 135 includes methods configured to process user profiles stored in the database 138 and generate intelligent recommendations for registered users based upon their respective user profiles. In one embodiment, as discussed below in more detail, the recommendation engine 135 uses deep learning techniques to generate intelligent recommendations for an application. In one embodiment, where the recommendation computing platforms is designed to match individuals for dating purposes, the recommendation engine 135 can perform compatibility analyses among multiple users using deep learning techniques to generate matching probabilities based upon user profiles. In one embodiment, a compatibility analysis is performed using self-identified information (user constraints/preferences) of the registered users which are obtained through self-identified responses and maintained in the database 136.
FIG. FIG. 2 shows various types of data multimodal that can be used to create models of user profiles according to an embodiment. More specifically, FIG. The database of multimodal data 137 in FIG. 2 shows various types of data that may be collected by computing devices or online data sources of registered users. 1. Multimodal user data includes time-series 200, unstructured texts 210 and multimedia 220. The time-series 200 includes geo-location data, biological data, calendar data, and data related to phone calls and user contacts 208. The unstructured textual information 210 includes short message service (SMS), storage data, and social networking data. Multimedia data 220 consists of voice data 222 and image data 224.
The following discussion is based on the assumption that FIG. 2 shows the multimodal data of a single registered user. The data in FIG. 2 is for a single user. However, it should be noted that similar or identical types of data are stored by the database of multimodal users data 137 for all registered members. Multimodal time-series 200, unstructured texts 210, or multimedia data 220 collected for one registered user are different types of data that can be used to extract relevant information, such as features, in order to characterize the individual and model them based on this information.
For instance, the time series geo-location data 202/202 comprises geographical location information (e.g. latitude and longitude coordinates) about the physical locations of a user’s computing devices over a time period. This information can be obtained by a location service application running on a computing device (e.g. smart phone) for the user. The GPS system is used to track and determine the locations (e.g. latitude and longitude) of this computing device. Geo-location data 202 can be stored in a series of n datapoints, each data point containing location information (latitude and longitude) with associated location time. This information can be used for determining the different locations that the user visited over time and the frequency of visits to each location. Geo-location data can be used to identify travel interests and events that the user attended.
The time-series biological information 204 comprises physiological information that can be captured by wearable devices such as smartwatches, activity tracker devices or wearable medical monitor devices. Other similar wearable wireless devices with integrated sensors are also capable of measuring an individual’s physiological data and physical activity. This information can include, but not be limited to, pulse rates, heartbeats, breathing rates and stress levels, as well as different types of brain activities. Activity tracker devices include dedicated devices or smart watches with sensors that measure heart rate, distance travelled, speed, altitude and calorie consumption. The time-series data 204 may be used in this way to determine the user’s fitness level, exercise style, and sleep patterns.
The time series calendar data 206 of a user can be obtained by a service for time management and scheduling that is installed on the computing device. Calendar data 206 may be analyzed in order to identify various activities that a person is involved with regularly or on an occasional basis. These activities are indicative of the user’s preferences, activities, and interests. Calendar data 206 can include information identifying travel interests and events attended by a user. The use of calendar applications by an individual can also be a sign that they are well organized.
The time-series contact and phone data 208 includes data about the history of calls made by the user and the contacts that he or she has with the people who are the subjects of those calls. Time-series contact and phone data 208 are retrieved from the call logs or contacts stored on a smart phone. These types of information can help determine different user behaviors. If a person regularly speaks to his/her family, or parents, it can indicate that the person has a strong family orientation. Regularly speaking with friends can indicate that a person is socially active and friendly. The time-series data on contacts and phone calls 208 can also be used to determine whether an individual is introverted or extrovert, based on their frequency and number of calls, time spent on phone calls, etc.
The unstructured textual datasets 210 include a variety of textual information that can be used to model and characterize the user’s preferences, activities, and interests. The user. The SMS data 212, for example, are textual data extracted from messages sent and received by a text messaging app running on the computing device used by the user. Storage data 214 are textual data extracted from documents, emails, and other files that are stored on the computer device. The SMS data 212, storage data 214, and health alerts can be used to extract information about a person’s health, financial status, and other factors.
![]()
Click here to view the patent on Google Patents.
Leave a Reply