
Data pipelines run a huge part of modern software. They pull in events from apps, logs from systems, files from users, signals from devices, and records from outside tools. Then they clean that data, shape it, move it, score it, and send it where it needs to go. That might be a dashboard, a fraud engine, a search tool, an AI model, or a customer-facing product.
Why Data Pipelines Matter More Than Founders Think
Most teams do not start out thinking their data pipeline is a core business asset. They see it as plumbing. It moves data from one place to another, keeps reports alive, and helps the product work.
That view is common, but it is often too small. In many startups, the pipeline is not just support work. It is where speed, quality, cost control, trust, and product advantage are won or lost.
The reason this matters is simple. A great product can still break if the data behind it arrives late, shows up in the wrong shape, gets mixed with bad records, or reaches the wrong output at the wrong time.
That means the pipeline is not just an internal system. It affects customer experience, team execution, and company value.
When a business understands this early, it starts making better choices about what to build, what to document, and what to protect.
The pipeline is often the hidden product
Many businesses think their real product is the app, the dashboard, the model, or the report the customer sees.
In practice, the customer only sees the final layer. The real magic often sits under the surface in the way data is collected, cleaned, linked, ranked, and delivered.
A startup may believe it sells insights, alerts, recommendations, or automation. Yet those things only work because the pipeline does hard technical work in the background.
It decides what data gets pulled in first, what gets ignored, what gets fixed, and what becomes part of the final output.
If that hidden flow is special, then the company may already have a real technical edge that deserves more attention than it gets.
Customers feel pipeline quality even when they never see it
A user may never ask how your ingestion layer works or how your system resolves conflicting records. They still feel the result. They notice when pages load with fresh results instead of stale ones.
They notice when alerts show up at the right moment. They notice when a system seems smart because it gives clean answers instead of noisy ones.
This is why businesses should stop treating the pipeline as back-office work. It shapes the quality of the customer promise.
When the customer experience depends on data timing, accuracy, and flow, the pipeline becomes part of the product story whether the team talks about it or not.
What looks like infrastructure may really be defensible value
A lot of founders underprice their own engineering work because it lives in infrastructure. They assume the market only values front-end features. That is a mistake.
Buyers, investors, and competitors all care about what makes a system hard to copy. Very often, that is the hidden logic in the data path.
If your business created a better way to handle broken inputs, merge records across messy systems, score incoming events before storage, or produce more useful outputs with less compute, that is not just maintenance work. That can be a core part of what makes the company valuable.
The earlier leadership sees that, the easier it becomes to capture that value in product strategy and in patent strategy.
Data pipelines shape business speed
Every startup says it wants to move fast. But moving fast is not just about shipping interface updates. It is about how fast the company can trust data, act on data, and build on top of data. A weak pipeline slows all three.
When data arrives in different forms every day, product teams waste time fixing the same problems again and again. When processing rules are messy, teams debate which numbers are right.

When outputs are delayed, sales, support, and operations all react too late. A strong pipeline gives a company speed that shows up across the business, not just in engineering.
Clean flow reduces decision lag
A business makes hundreds of small decisions each week. Which users are ready for outreach.
Which accounts show churn risk. Which feature is creating friction. Which customer segment is growing faster. These calls depend on trusted data.
If the path from source to output is weak, the company starts working from partial truth. That creates decision lag. Teams stop trusting dashboards. Managers ask for manual checks.
Analysts rebuild logic in separate files. Progress slows down, not because people are lazy, but because the system does not give them confidence. Strong pipelines reduce that drag and let teams act sooner with less friction.
Fast pipelines create room for better experiments
Most businesses want to test pricing, features, prompts, onboarding, and growth channels. But good tests need clear and timely data.
If your system takes too long to pull in user behavior, resolve identities, and produce usable outputs, your tests become blurry. You may not know what worked until the moment has passed.
A better pipeline makes experimentation sharper. Teams can run tests with faster feedback loops.
That means the company learns faster and improves faster. The business impact is not abstract. It shows up in shorter product cycles, less wasted spend, and better use of team time.
Action founders can take right now
One useful move is to ask a simple question across your product, data, and ops teams: where do we lose time between raw input and trusted action? The answer often reveals the most valuable parts of the pipeline.
It may be event deduplication, schema mapping, context enrichment, or output routing. Once you spot that gap, you can decide whether it is just a pain point to fix or a real invention to document and protect.
Another strong move is to track where human work is being used to rescue machine flow. If people keep stepping in to clean records, match entities, verify outputs, or correct downstream errors, that is a clue.
Either the current system is weak, or your team has already built a special method to handle those issues. Both are important for business strategy.
Pipeline quality affects margins more than most teams expect
Revenue gets attention. Margin often gets less love in early growth. But data flow has a direct effect on cost.
Bad ingestion can create duplicate storage. Poor processing logic can waste compute. Weak output control can trigger expensive retries, manual review, and customer support issues.
This matters because many startups win early users before they fully understand their cost shape. Then the company grows, data volume rises, and hidden pipeline waste becomes a real financial problem.
What felt manageable at low scale starts draining the business at higher scale. Strong pipeline design can protect not just product quality, but also the unit economics of the company.
Every broken handoff has a price
When data changes hands between systems, things can go wrong. Fields go missing. Timestamps shift. Duplicate events sneak in. Records arrive out of order.
Labels get stripped away. Each one of those failures creates cost somewhere, even if it does not show up on a single invoice.
Sometimes the cost is direct, like extra storage or compute. Sometimes it shows up as support tickets, bad customer trust, slower reporting, or rework by internal teams.
Smart businesses start measuring these handoff costs. Once they do, they often discover that pipeline investment is not just technical cleanup. It is margin protection.
Better flow can lower manual operations
A company may think it has an operations problem when it really has a pipeline problem. Teams hire people to review exceptions, clean records, fix sync errors, and patch reporting gaps.
That manual layer often grows quietly. It seems harmless at first because each task is small. Over time, it becomes a tax on the whole business.
If your team builds a novel way to resolve those issues automatically, that work matters.
It saves money, reduces error rates, and supports growth without matching headcount growth. That kind of result is highly strategic because it improves both scalability and resilience.
Trust is built in the pipeline long before output
Trust is one of the hardest business assets to earn and one of the easiest to lose. Many leaders think trust is only about branding or customer support. In data-heavy products, trust starts much earlier.
It starts with what enters the system, how it is checked, and what rules shape it before output.
A dashboard with wrong numbers weakens trust. A recommendation engine that uses stale context weakens trust.
An alert system that fires on dirty data weakens trust. The customer may never know where the issue started, but the business still pays the price. That is why pipeline quality has a direct link to market credibility.
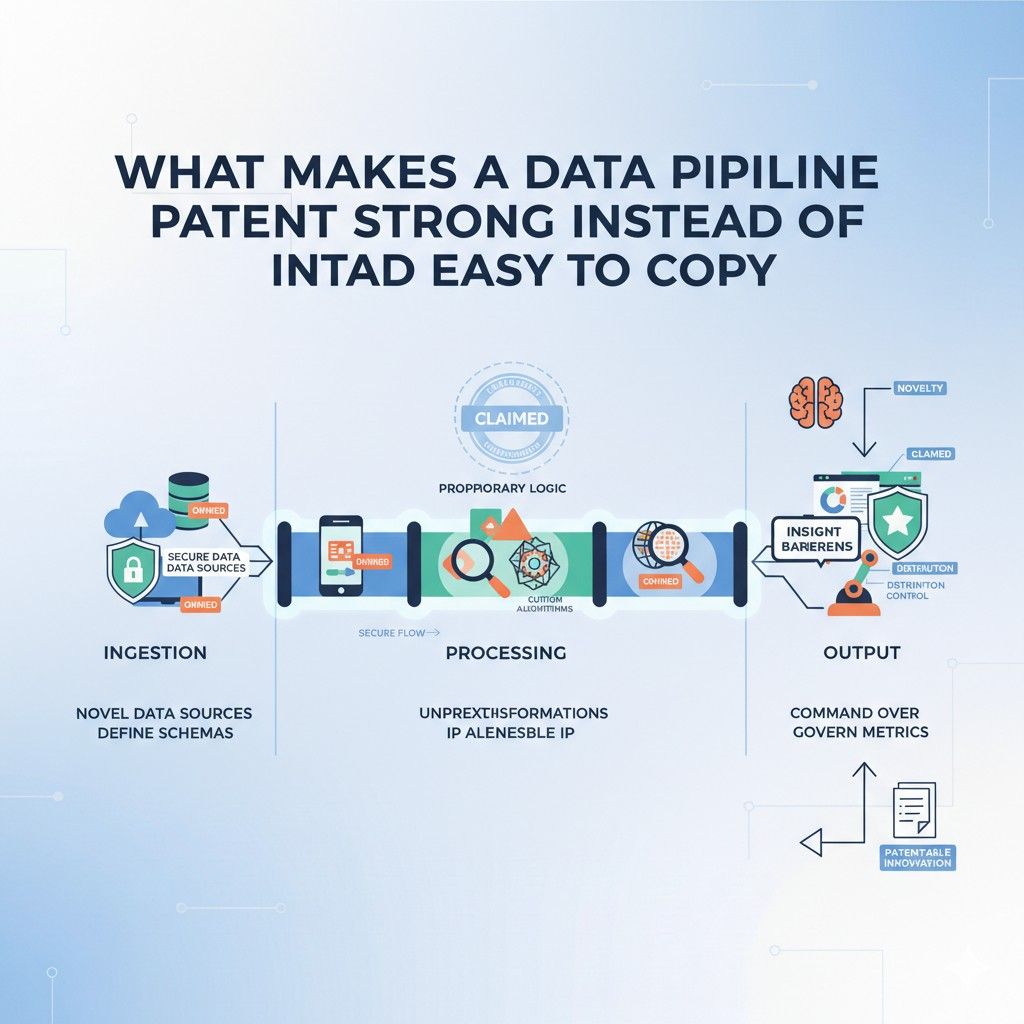
How to Claim Ingestion, Processing, and Output the Right Way
Many founders know their system does something special, but they struggle to explain it in a way that creates real protection. That is the main challenge with data pipeline patents.
The work is often deep and highly useful, yet the value gets lost when the invention is described too loosely.
A strong claim does not say only that data comes in, gets processed, and goes out. It shows what actually happens inside that flow and why the result is better than ordinary approaches.
This is where strategy matters. The goal is not to describe your whole platform in broad marketing words. The goal is to capture the technical choices that make your pipeline work in a new and useful way.
When done right, the claim covers the core engine of your advantage. When done poorly, it becomes easy to design around, easy to reject, or too vague to matter.
Start with the technical edge, not the business pitch
A lot of teams begin with the story they tell customers. That story may be strong for sales, but it is usually weak for patent claims.
Words like faster, smarter, safer, and more scalable sound good, yet they do not explain what the system is actually doing. A patent claim needs the real mechanism.
The better starting point is the specific technical problem your pipeline solves. Maybe incoming records arrive out of order and your system reconstructs event sequence before downstream use.
Maybe the pipeline detects schema drift on the fly and remaps fields without breaking output quality. Maybe it routes data differently based on confidence, source quality, or downstream use. Those are the kinds of things that give a claim real shape.
The claim should track the actual flow of the system
A useful way to think about this is to follow the life of the data through the system. How does it enter.
What happens first. What happens next. What gets changed, filtered, enriched, ranked, merged, or rejected. What determines the final output. This flow is where claim material lives.
When the claim follows the true technical path, it becomes more grounded and more defensible.
It also becomes easier to connect engineering work to legal protection. The claim stops sounding like a generic software idea and starts sounding like a real machine made of logic, rules, and state changes.
Why broad claims often fail
Founders often assume broader means better. It feels safer to claim a large category instead of a narrow implementation. In practice, overly broad pipeline claims are often weak.
If the claim simply says data is ingested, processed, and output, it sounds like almost every data system ever built.
That creates two problems. First, it becomes easier for an examiner to say the idea is already known.
Second, even if it gets allowed, the claim may not cover the part that actually makes your system valuable. Broad language can create the illusion of protection while leaving your true edge exposed.
Broad is not the same as strong
A strong claim is not just wide. It is targeted. It reaches the invention at the point where novelty actually lives.
That may be a special ordering rule, a validation path, a routing decision, a transformation method, or a feedback loop between pipeline stages. When you claim that core method clearly, the protection often becomes more meaningful than a broad but shallow statement ever could.
Claiming ingestion the right way
Ingestion is often treated like the simple front door of the pipeline. That is a mistake.
In many systems, the ingestion layer contains major technical value. It decides what comes in, in what form, with what checks, under what timing rules, and with what handling for bad or incomplete inputs.
If your startup built a special way to do that, it may be one of the most important parts of the patent story.
The key is to avoid describing ingestion as mere receipt of data. That sounds passive and generic.
Stronger claiming explains how the system handles incoming data in a controlled and useful way that changes downstream performance.
Focus on what makes your intake process different
A good question to ask is this: what happens at intake that would not happen in a standard pipeline.
The answer may reveal the heart of the invention. Perhaps the system classifies source reliability before deciding whether to store raw input or hold it for verification.
Perhaps it creates structured records from mixed-format inputs without needing fixed source templates. Perhaps it tags incoming items with context that later controls processing order.
Those are not just setup details. They can be part of the inventive step. The stronger your answer, the easier it becomes to turn ingestion into a claim element with real value.
Timing rules can matter as much as content rules
Many teams think only about the fields inside the incoming record. But timing can be just as important.
Some pipelines gain their edge because of when data is accepted, delayed, replayed, merged, or dropped. A method that handles late-arriving events, burst traffic, or source conflicts in a new way can be highly claim-worthy.
This is especially true in systems where freshness affects product quality. If your pipeline improves outcomes by controlling the timing of data intake, do not bury that detail. It may be central to the invention.
Validation can be an inventive step
Basic validation is common. But not all validation is basic. If the system does more than check whether a field exists, you may have something more interesting.
Maybe it compares incoming records against dynamic source-specific rules. Maybe it scores the trustworthiness of payloads before they enter the main processing path. Maybe it decides whether to reject, quarantine, or partially admit a record based on multiple conditions.
That kind of logic can be valuable because it shapes the entire pipeline from the start. The invention may not be the data itself. It may be the way the pipeline makes smart decisions about what deserves entry and in what state.
A strong ingestion claim sounds operational
Good ingestion claims often sound like real system behavior. They describe receiving a set of inputs, evaluating one or more conditions, assigning metadata, applying a decision rule, and storing or routing the result in a defined way.
That operational detail matters. It shows the invention is doing technical work, not just stating a goal.
Claiming processing the right way
Processing is where many founders assume the invention lives. Often they are right, but the risk here is different. Because processing can cover many steps, teams sometimes describe it as a black box.
They say the system analyzes data, transforms data, or applies intelligence to data. Those phrases are too soft. The stronger move is to show the sequence of changes that processing performs and the conditions that control those changes.
Processing claims get stronger when they explain how the system moves from one state to another. That means naming the technical action and the trigger for that action in simple, precise terms.
Show the order of operations
Order matters in pipeline systems. A transformation done before deduplication can produce a different result than the same transformation done after record matching.
An enrichment step done before confidence scoring may affect routing in a way that changes output quality. If your advantage depends on order, then order should appear in the claim strategy.
This is one of the most overlooked parts of claiming software systems. Teams mention the components but not the sequence. Yet in many pipeline inventions, the sequence is exactly what makes the method work.
Rules, thresholds, and conditions give the claim teeth
A claim becomes much more useful when it includes the rules that drive the system. That does not mean stuffing it with every internal parameter. It means identifying the decisions that matter.
What threshold causes a record to take one path instead of another. What condition triggers a merge instead of a split. What confidence level changes how output is prepared.
These details make the claim less generic and more tied to the invention. They also help show that the method is not just an abstract idea. It is a practical system with defined behavior.
State changes are often more important than labels
A common mistake is focusing on labels rather than effects. A team may say it has a normalization engine, a scoring layer, or a context module. Those names are useful internally, but claim strength comes from what those modules do.
A better description focuses on state changes. The system converts unstructured inputs into structured event objects.
It updates a record graph based on source overlap and temporal proximity. It creates a confidence-weighted intermediate representation used to control downstream output generation. That kind of language is stronger because it reflects actual function.
Processing claims should capture coordination, not isolated steps
Many valuable data pipeline inventions do not live in one processing action. They live in how actions work together. A routing choice may depend on a validation outcome.
A transformation may depend on metadata created during ingestion. An output decision may depend on an earlier confidence score. This coordination is often where the real technical insight lives.
That is why good claim drafting looks at interaction, not just ingredients. Anyone can name parts of a pipeline. The real question is how those parts influence each other in a useful and non-obvious way.
Ask what would break if a competitor copied only half of it
This is a practical test founders can use. If a rival copied one transformation step but not the decision rules around it, would they get the same result. If not, then the invention likely includes coordination across steps.
That means the claim should not stop at the single processing action. It should capture the linked behavior that creates the benefit.
Claiming output the right way
Output is often treated as the end of the story. In many systems, it is actually part of the invention itself.
That is because the value of the pipeline is not only in how data is handled internally. It is also in how final results are generated, selected, formatted, prioritized, or delivered for use.
If your system creates better outputs through a special decision process, that deserves careful claiming. A weak claim says the processed data is provided to a user or downstream system. A stronger claim explains how the output is produced and why it is different from a basic handoff.
Output is where technical value becomes visible
The output stage is where system design turns into business impact. This is where a user sees a cleaner answer, a model gets a better feature set, an alert engine receives a better signal, or a dashboard updates with more reliable results.
If the pipeline creates that benefit through a defined technical process, output should not be an afterthought.
Many strong software claims become more concrete when they describe the final formation of output. This can include how results are selected, how uncertainty is handled, how multiple candidate outputs are ranked, or how the output format changes based on downstream need.
What Makes a Data Pipeline Patent Strong Instead of Easy to Copy
A weak patent gives a founder false comfort.
It looks serious. It sounds broad. It may even mention the main parts of the system. But when a competitor studies it, they can often step around it without much trouble.
They change a few words in their product, shift one stage in the flow, or swap one component for another, and suddenly the patent is no longer a real barrier. That is the problem.
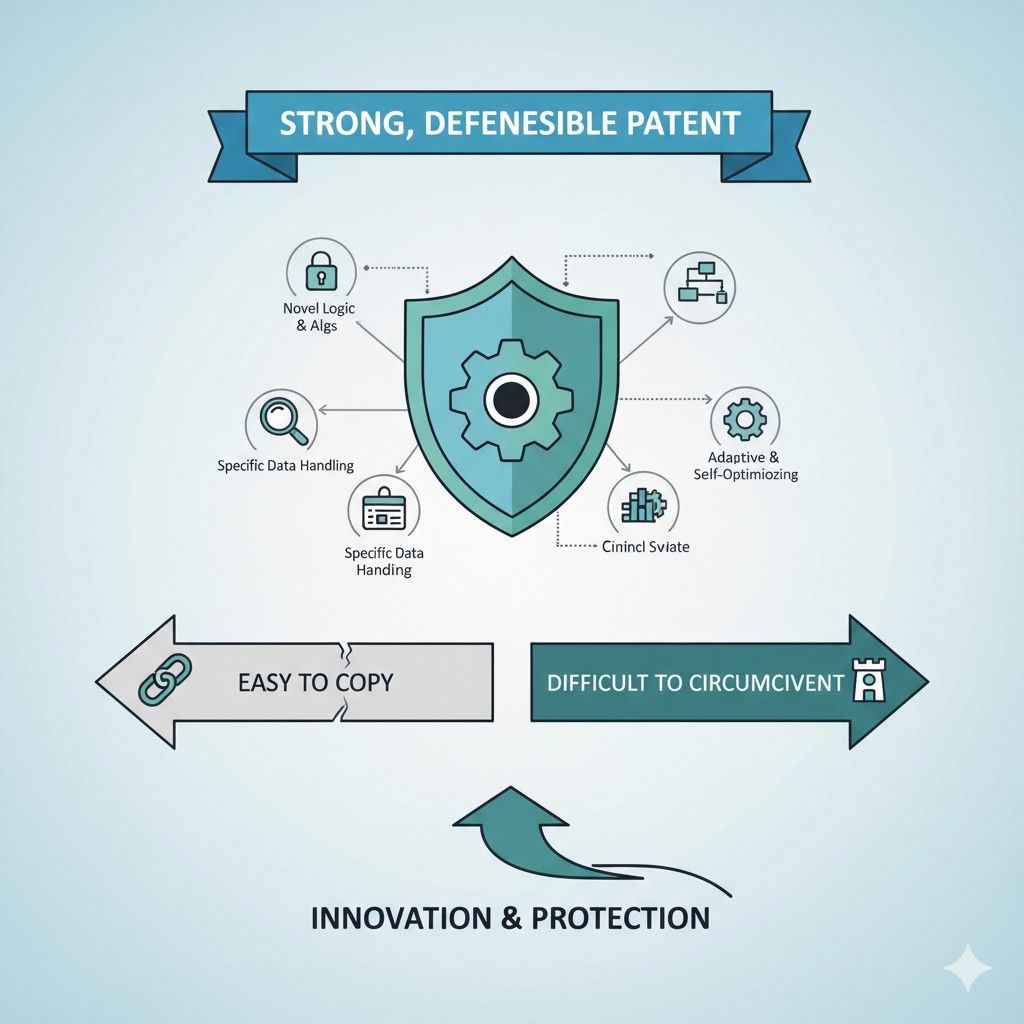
A strong data pipeline patent does the opposite. It protects the real technical heart of the system. It covers the part that creates the result, not just the surface description of what the company says it does.
That difference matters a lot for startups because most of the value in a pipeline product sits under the hood. If the patent only covers the shell, your moat may look stronger than it really is.
Strong patents protect the method, not the marketing line
Many teams describe their invention the way they describe their company. They say they move data faster, clean it better, or generate smarter outputs. That language works for sales pages and investor decks. It does not create a hard-to-copy patent.
A strong patent must go deeper. It has to explain how the system reaches that result through actual technical behavior.
It should show what happens to data at key points in the pipeline, what rules shape that path, and why that path creates a better outcome. That is what makes the patent hard to work around.
The real moat is usually in the hidden logic
Most competitors can copy visible product ideas. They can build a dashboard, create alerts, or move records from one service to another.
What is harder to copy is the hidden set of decisions inside the pipeline that makes the product feel faster, cleaner, more reliable, or more useful.
That hidden logic may include the way incoming data is classified before storage, the way partial records are merged over time, the way confidence scores change processing paths, or the way outputs are prepared for different downstream systems.
If the patent captures that hidden logic well, it starts protecting something much more durable than a surface feature.
Broad words alone do not stop a smart competitor
Many founders think the answer is to make the patent very broad. They want language that seems to cover anything involving ingestion, processing, and output.
The problem is that broad language without technical depth often becomes fragile. It may be easy to reject, easy to weaken, or easy to avoid.
A smart competitor reads broad claims and looks for the empty space. If the patent says data is received, transformed, and transmitted, the competitor asks a simple question: what exact part do we have to avoid?
If the claim does not clearly answer that, then it may not be very threatening.
Strong coverage comes from precision in the right place
The goal is not to make the patent narrow in a bad way. The goal is to be precise where the invention truly lives.
A well-written patent can still have meaningful scope, but it gets that scope from the right details. It captures the core mechanism clearly enough that changing small labels or swapping simple components does not let a copycat escape.
A strong pipeline patent starts with a real technical problem
The strongest patents usually begin with a real pain point the team had to solve. Not a vague business goal. Not a generic wish to be more efficient. A real system problem that caused friction, delay, cost, error, or weak output quality.
This matters because strong protection usually grows from real engineering work.
When a team had to solve a real technical problem, the resulting method often has enough shape and substance to support a stronger patent. That makes it harder for others to dismiss the invention as basic software activity.
Problem-driven patents are harder to design around
When an invention is tied to a specific technical problem, the solution tends to include real system choices. Those choices create useful boundaries in the patent.
A competitor cannot escape just by saying they use a different dashboard or a different label for a module. If they still need to solve the same underlying problem in a similar way, they may still run into the patent.
That is why teams should always ask what exact issue the pipeline solved. Maybe the problem was late-arriving events that broke output order. Maybe it was conflicting data from multiple sources.
Maybe it was the cost of repeated processing on noisy inputs. Whatever the issue was, the patent should anchor itself in that technical challenge.
Good patents explain why ordinary pipelines fall short
A patent gets stronger when it makes clear that the standard way of doing things was not good enough.
This does not require dramatic language. It just requires clear thinking. What did the old flow fail to do. Why was that failure important. What changed in the new design that produced a better result.
That explanation does more than improve the story. It helps shape claim language that reflects a real advance instead of a generic computer workflow. The more clearly the patent shows the old weakness and the new solution, the more grounded it becomes.
The best inventions often come from messy edge cases
A lot of true pipeline innovation comes from situations that basic systems handle badly. Inputs arrive out of order. Records are incomplete. Source quality changes over time.
One downstream consumer needs speed while another needs certainty. These edge cases often push teams to invent methods that are more sophisticated than ordinary pipelines.
If your startup solved those kinds of messy cases in a novel way, that is often the strongest place to build a patent.
Competitors may try to mimic the final result, but without the same underlying method, they may struggle when the real-world mess shows up.
Save the hard cases, not just the happy path
One of the smartest things a company can do is preserve examples of where the old system broke and where the new one succeeded. Those cases often reveal the actual inventive step.
They also help a patent capture what makes the system robust instead of making it sound like a generic flowchart.
Strong patents describe the full chain of cause and effect
Data pipelines are not just collections of features. They are moving systems. One stage changes what the next stage can do. One decision at intake can affect the quality of final output. One confidence score in the middle can alter routing, formatting, or timing later on.
A strong patent captures that chain. It shows how the pipeline behaves as a connected system. That is one of the main things that makes it harder to copy.
Isolated steps are easier to imitate
If a patent only protects one small step in the flow, a competitor may route around it.
They can move that step earlier, later, or into another component. They can claim they do not use the same named module. They can break the system into parts and argue that no single part matches the claim.
That is why strong pipeline patents often describe more than a single action. They show how one action affects another and how the sequence creates the result.
A competitor then has a harder time copying the value while pretending the structure is different.
Linked behavior is where many real inventions live
In a lot of startups, the magic is not one transformation or one validation check. The magic is the way several steps work together. Ingestion may assign metadata that later controls enrichment.
Processing may create a score that later changes output timing. Output may differ depending on source trust assigned at intake.
This kind of linked behavior creates stronger patent material because it reflects system architecture. It is harder to fake. It is also harder for a competitor to remove without losing the same outcome.
Sequence can matter as much as substance
A strong patent often protects not just what the pipeline does, but when it does it. That order can be critical.
A system that deduplicates before enrichment may behave very differently from one that enriches before deduplication.
A system that delays certain outputs until cross-source verification may create a better result than one that publishes immediately.
When the sequence is part of the advantage, the patent should say so. This is one of the simplest ways to make a claim more meaningful and harder to design around.
Ask what would happen if the steps moved
A practical test is to ask whether the result would stay the same if the order changed. If the answer is no, then the order is probably part of the invention. That should not stay hidden in engineering notes. It should become part of the protection strategy.
Wrapping It Up
Data pipelines do far more than move data from one step to the next. They shape how a product works, how fast a team moves, how much trust a customer feels, and how hard it is for others to copy what your company built. That is why claiming ingestion, processing, and output the right way matters. It is not about using big words or making the broadest claim possible. It is about clearly protecting the real technical method that gives your business an edge.
Leave a Reply