Most of the real value in modern software does not live on the screen. It lives behind the screen. It lives in the jobs that run later, the workers that process heavy tasks, the services that talk to each other, and the quiet system logic that keeps everything moving when users are asleep. That is where many startups build their true edge. It is also where many founders miss the chance to protect what they built. If your product depends on backend systems, you may be sitting on patent-worthy work without knowing it.
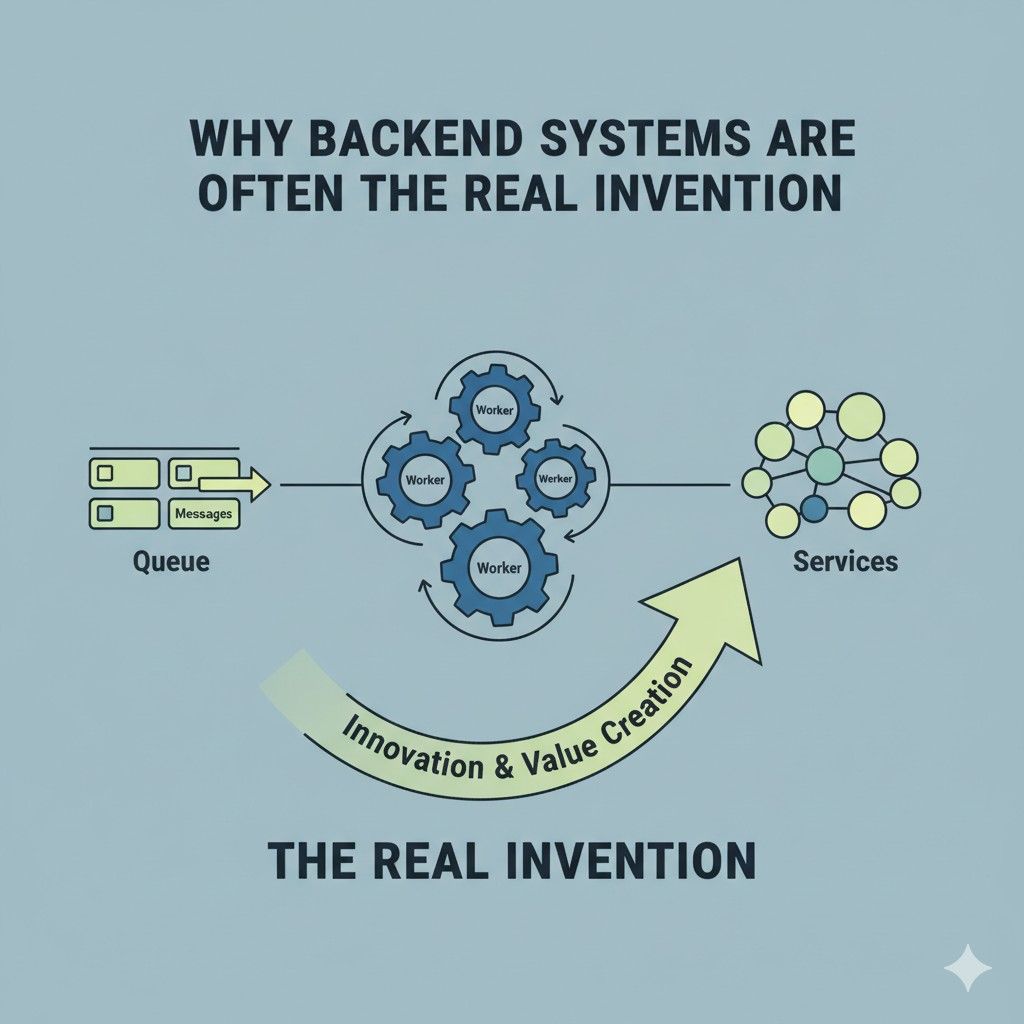
Why Backend Systems Are Often the Real Invention
Most people outside engineering notice what they can see. They notice the dashboard, the app screen, the report, the button, or the alert. But in many startups, that visible layer is not where the deepest value lives.
The real edge often sits in the backend. It sits in the flow of work behind the scenes, in the rules that decide what happens next, and in the system design that makes the product fast, stable, and hard to copy.
That is why this section matters so much for businesses. If a company only talks about the feature a customer sees, it may miss the part of the product that actually makes the company special.
For patent strategy, product strategy, and even investor storytelling, backend systems deserve much more attention than they usually get.
The screen is often the easy part
A clean screen can still matter a lot. It shapes the user experience and can drive adoption. But in many software products, the screen is only the final step in a much longer chain of work.
By the time a user sees a result, many backend processes may have already made hard decisions, handled failures, balanced resources, checked rules, and stitched together outputs from many sources.
That hidden work is often where the company spent the most time solving real technical problems.
It is where the team learned what does not scale, what breaks under load, and what must happen in a very exact order for the product to work. When that hidden logic is original, useful, and tightly designed, it may be the real invention.
The user sees output, but the invention may be in the path
A user may think they clicked one button and got one result.
In reality, the system may have routed the request through several queues, split the task into smaller jobs, assigned those jobs to workers based on current load, retried failed tasks under custom rules, and merged the results before anything was shown on the screen.
That path matters. It can create speed, cost savings, better uptime, stronger security, or more accurate outcomes.
A business that understands this can tell a much stronger story about what it built. It can also claim the value where it truly lives instead of only talking about surface-level features.
Many products look similar from the outside
This is one of the biggest reasons backend systems matter for protection. Two products can look almost the same to a customer while working in very different ways behind the scenes.
One may rely on a simple and fragile flow. The other may use a much smarter architecture that handles scale, delays, priorities, and failures with far more skill.
That difference may not show up in a screenshot. But it can shape the whole business.
For founders, this creates both a risk and an opening. The risk is assuming there is nothing special to protect because the visible product seems familiar.
The opening is recognizing that the unique part may be the backend structure that makes the same user promise possible in a better, faster, cheaper, or safer way.
A copied interface is not always a copied system
Competitors can often copy visible product ideas quickly. They can mimic page layouts, flows, and basic feature sets. What is harder to copy is the backend design that makes those features work well at scale.
If your company has found a better way to coordinate services, schedule jobs, or recover from errors without hurting the user experience, that may be a much stronger foundation for defensibility.
This is why businesses should train themselves to ask a better question. Not just, what does the user click? The better question is, what has to happen behind the scenes for this to work in a way others would struggle to match?
Backend design often creates the business advantage
The best backend systems do not just support the product. They shape the business model. They affect cost per transaction, gross margin, service quality, speed to result, team efficiency, and the ability to expand into new markets.
A startup that handles millions of background events with less compute cost has a real advantage. A platform that routes tasks with less delay can win on customer trust. A company that isolates failures better can keep operating when others go down.
That is not just engineering quality. That is business value.
When a business sees backend design through that lens, patent strategy becomes easier. You are no longer trying to protect a vague technical setup. You are protecting a machine that creates a real commercial edge.
The hard problem is usually in the orchestration
Most backend inventions are not about one isolated component. They are about coordination. The queue alone may not be new. The worker alone may not be new.
The service itself may use common tools. What can be new is the way those parts interact under specific rules to achieve a useful result.
That interaction is where many founders undersell their work. They describe the ingredients, but not the system behavior. They name the parts, but not the decision logic.
They show the boxes, but not the movement between them.
For a business, this is a serious missed opportunity. Markets reward outcomes.
Patent value also tends to follow outcomes. If your backend architecture produces better outcomes because of how the pieces work together, that joined behavior deserves careful attention.
A queue is not the invention by itself
A queue is common. Many systems use queues. That fact causes some founders to stop too early. They think, everyone uses queues, so there is nothing here. But that is usually the wrong frame.
The real question is not whether a queue exists. The real question is how your system uses it.
Does your system change priority based on live state? Does it route jobs differently based on data type, user class, urgency, cost, risk, region, or failure history? Does it delay, split, merge, or reassign work in a specific way that solves a technical problem?
That is where the real story begins. The common building block does not destroy novelty. What matters is the specific arrangement and operation that creates the result.
A worker is not just a background process
The same logic applies to workers. Many companies talk about workers as if they are simple background handlers.
But in advanced systems, workers can carry much more value than that simple label suggests.
A worker may be designed to pull jobs under special timing rules, reserve capacity for premium tasks, lock shared resources in a safe way, or switch execution paths based on confidence thresholds or policy checks.
When a business documents these details, it turns a generic phrase into a strategic asset. It becomes clear that the backend is not a loose set of cloud tools. It is a designed operating model.
The best backend inventions solve ugly problems
The market often celebrates clean demos and polished launches. But backend innovation usually comes from pain. It comes from dropped jobs, race conditions, retry storms, stale reads, duplicate events, dead-letter backlogs, service timeouts, and broken dependencies.
Teams that solve these problems in a real and useful way often create the most defensible technical work.
That is good news for startups because many of their strongest inventions come from survival. They build practical solutions because they have to. They do not always realize those solutions may be worth protecting.
A smart business should pay close attention any time the team says something like, “We had to build our own way to handle that,” or, “Normal setups kept failing, so we changed the flow.” Statements like that often point straight to patent-worthy material.
Reliability can be an invention, not just a feature
Many founders think patents need to cover flashy functions. In practice, a system that improves reliability in a concrete way can be highly valuable.
If your architecture reduces failed processing, prevents duplicate work, keeps related jobs in a safe order, or recovers faster after partial failure, that can be a meaningful technical contribution.
This matters even more for businesses selling into serious markets. Enterprise buyers care about reliability.
Regulated industries care about control. Customers handling money, health data, logistics, or real-time operations care deeply about whether the system can be trusted when things go wrong.
If your backend design creates that trust in a specific and repeatable way, it may be central to both your sales story and your protection strategy.
Better failure handling can be a key claim angle
A lot of strong backend inventions appear when systems fail. What matters is what the system does next. Does it retry everything the same way? Does it detect partial completion and resume only missing parts?
Does it redirect work to another service class? Does it preserve ordering while still keeping throughput high? Does it mark jobs with extra context so later workers can make smarter choices?
These details are often far more valuable than broad claims about “processing tasks asynchronously.” Businesses that capture the exact failure logic can create stronger patents and stronger internal knowledge at the same time.
Speed is often created in the backend, not the interface
Users love speed, but speed rarely comes from design polish alone. It comes from smart system behavior. It comes from pre-processing, caching, splitting workloads, parallel execution, selective retries, dynamic routing, and service coordination.
A business that improves response times through backend architecture may have a major technical asset even if the front-end feature looks ordinary.
This is where strategy matters. If a company says only, “Our app is faster,” that is weak.
But if it can explain that speed comes from a system that identifies task type, dispatches work to specialized worker groups, updates shared state in a controlled way, and returns partial results while long-running tasks continue, that is much more concrete and much more valuable.
Cost control can also make the backend inventive
Not every important invention is about adding more capability. Some of the best ones are about doing the same job with less waste. In a startup, that can change survival odds.
A backend system that cuts compute use, storage overhead, or cross-service traffic can directly improve margins and runway.
That type of work is often overlooked because it feels internal. But internal does not mean unimportant.
A business that can deliver the same customer promise at a lower operating cost may have a powerful moat. If that result comes from a specific architecture or control flow, it may be worth claiming.
Cheap at scale is not just luck
When a system stays affordable under growth, it is usually because someone made smart design choices. Maybe the team separated urgent tasks from delay-tolerant tasks.
Maybe it used event-driven updates instead of wasteful polling. Maybe it created a worker assignment model that cut idle time. Maybe it reduced repeated service calls by adding an intermediate state layer.
Those choices can become part of a strong backend invention story. Businesses should not hide them in the engineering wiki. They should study them as possible sources of long-term advantage.
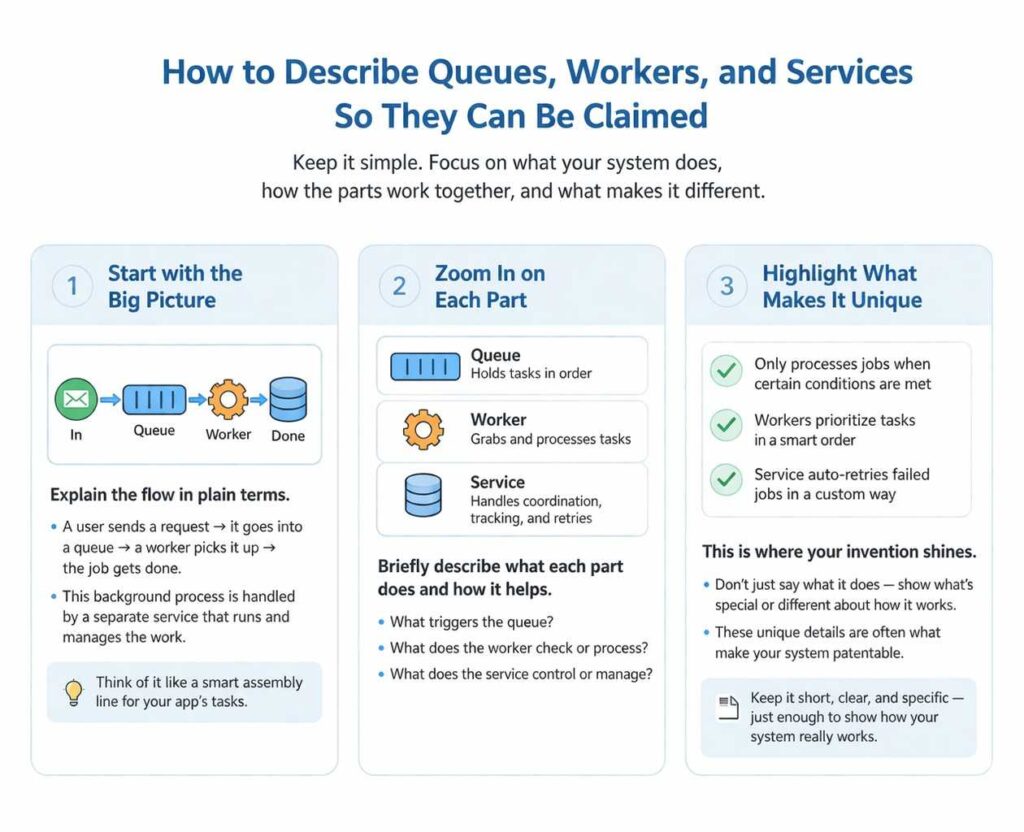
How to Describe Queues, Workers, and Services So They Can Be Claimed
A strong backend system does not become claimable just because it is complex. It becomes claimable when it is explained in a clear way that shows what the system does, how it does it, and why that approach matters. That is where many teams lose value.
They built something real, but when they describe it, they make it sound generic. They use broad labels, skip the hard parts, and leave out the system behavior that actually makes the work unique.
This section is about fixing that problem. If your business wants to protect backend architecture, the goal is not to write in stiff technical language. The goal is to explain the system in a way that captures the real invention.
That means turning hidden engineering decisions into a plain but precise story about flow, control, and technical effect.
Start with the problem the backend had to solve
Before you describe any queue, worker, or service, you need to explain the real problem that forced the architecture to exist. This matters because backend systems rarely become valuable in the abstract.
They become valuable because they solve a real bottleneck, reliability issue, cost issue, timing issue, or scaling issue that simpler systems could not handle.
A weak description starts with tools. A strong description starts with pressure. It explains what kept breaking, what kept slowing down, what needed to happen in a certain order, or what had to be handled without blocking the user.
Once that problem is clearly stated, the system design starts to make sense as a solution instead of sounding like a pile of infrastructure parts.
Describe the pain in business terms and system terms
The best way to do this is to connect the technical challenge to a business need. Maybe customer requests arrived in bursts and delayed processing hurt trust. Maybe one failed job caused waste across many later steps.
Maybe the system had to give fast answers while still doing deep work in the background. Maybe not all tasks deserved the same priority, and uniform handling created cost or delay.
When you describe that pain clearly, you create a stronger frame for everything that follows.
You are showing that the backend structure was not random. It was built to solve a concrete problem that mattered to the product and the business.
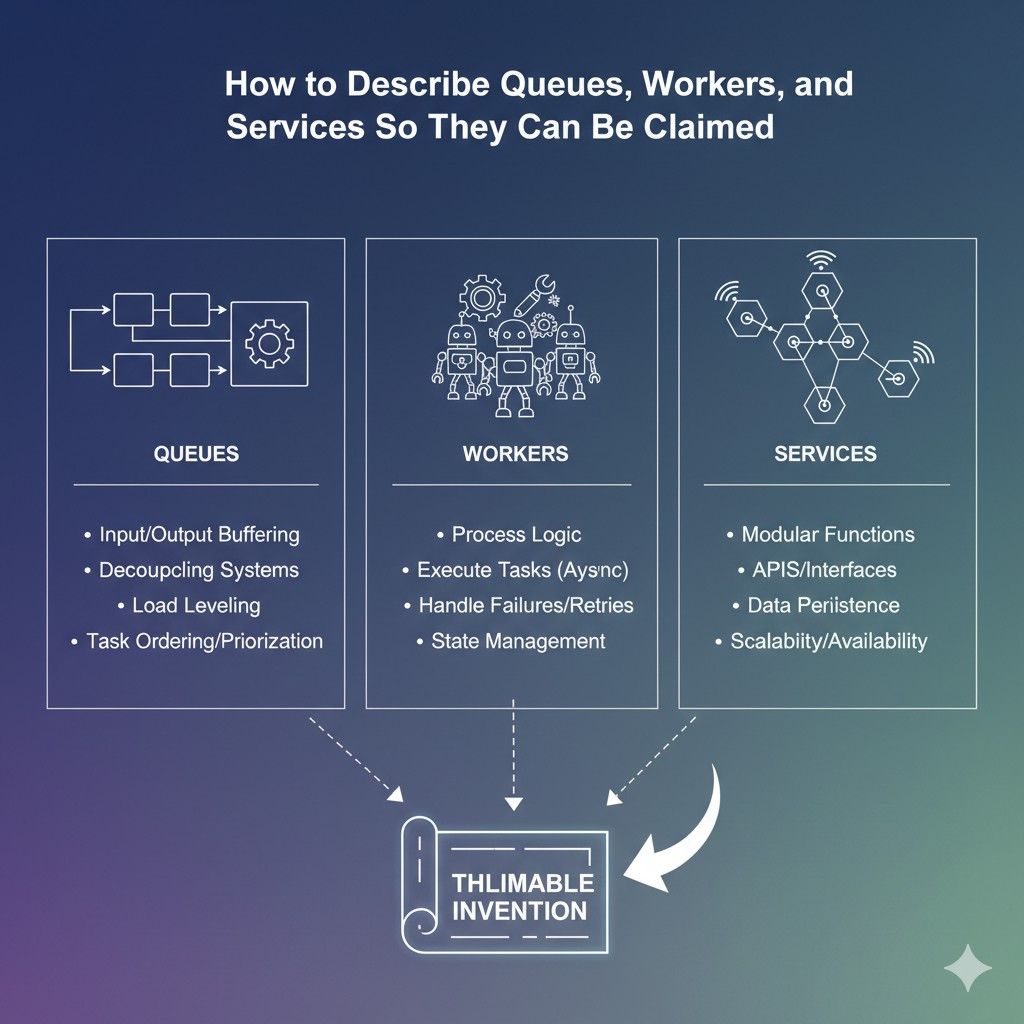
Do not describe components as isolated boxes
A queue, a worker, and a service can each sound ordinary when described alone.
That is why many backend inventions get watered down. Teams speak about the components one by one, but they do not explain the system as a coordinated machine. The result is flat and forgettable.
The better move is to describe how the pieces interact over time. What triggers the queue. How work enters it. What metadata travels with the job. How workers decide what to pick up.
What conditions cause a worker to pause, retry, split, escalate, or reroute the task. How services update shared state. How the system knows a job is complete. That chain of behavior is where a lot of backend value lives.
The invention is often in the movement, not the parts
Many businesses make the mistake of naming the ingredients and assuming that is enough. It is not enough. A queue is just a queue until you explain what makes its use in your system different.
A worker is just a background process until you explain how it behaves under your rules. A service is just a service until you explain what role it plays in the larger path.
That is why the movement between parts is often the best place to focus. You want to describe the handoff logic, the decision points, and the state transitions.
That is what makes the backend architecture sound like a designed system instead of a basic deployment diagram.
Use plain language before technical labels
Founders and engineers often assume that more technical wording makes the description stronger. In many cases, it does the opposite. It can hide the useful detail behind language that sounds impressive but says very little.
A backend claim strategy works better when the explanation begins in plain language.
That means describing what the system does in simple, direct terms.
For example, instead of saying the architecture supports distributed asynchronous execution, say that the system places work into a processing line so the user does not have to wait while background tasks are completed.
Instead of saying the worker uses adaptive orchestration, say that the worker changes its behavior based on job type, system load, and earlier task results.
This does not mean removing technical detail. It means making the detail understandable and concrete.
Simplicity helps expose what is actually new
Plain language forces clarity. If you cannot explain what makes the backend different in simple words, there is a good chance the description is still too vague.
The goal is not to sound less smart. The goal is to show the system logic in a way that makes the novelty visible.
This is especially helpful for businesses because patents are not just legal tools. They are strategic assets.
They need to be understood by decision-makers, investors, and internal teams as well. A clear explanation helps everyone see what the company actually built.
Focus on decisions, not just steps
A common weak description reads like a timeline. First the request arrives. Then it is queued. Then a worker processes it. Then a service stores the result. That kind of write-up may be accurate, but it does not capture the real backend intelligence.
What usually matters more is how the system decides what to do at each stage. Does it assign different processing classes? Does it choose workers based on current conditions? Does it route jobs to different services based on content, urgency, or failure history?
Does it delay low-priority work while preserving response speed for critical jobs? These decisions are often what make a backend design claim-worthy.
Static flows are usually weaker than conditional flows
A backend system becomes much more interesting when it reacts to conditions instead of following one fixed path every time. That reaction may be where the true invention sits.
If the system changes behavior based on queue depth, dependency status, task complexity, or policy state, that should be captured.
For businesses, this point is practical. The more your description reflects actual decision logic, the more clearly it shows why your system performs better than a generic setup. It helps transform the architecture from plumbing into a strategic mechanism.
Describe what information travels with the work
One of the most overlooked parts of backend description is the data that moves with each job.
Many teams describe the existence of a queue but say very little about what the queued item contains. That is a missed chance because the metadata often controls the whole system.
A job may carry priority markers, user class, dependency links, retry counts, policy flags, region data, execution history, confidence values, or timing rules.
That extra context can determine which worker handles the task, what steps are allowed, when retries happen, and whether downstream services are triggered. In many architectures, this traveling information is the backbone of the control logic.
Jobs are not just tasks, they are instructions
A useful way to think about it is that the queued item is not merely a task waiting its turn.
It is often a compact instruction set that tells the system how to treat the work. That makes the job payload a very important part of the backend story.
Businesses should document this carefully. Ask what information gets attached when the task enters the queue and how that information affects later processing. Those details can make a plain background process look like a carefully designed control framework.
Show how workers behave under real conditions
Many descriptions of workers stop too early. They say the worker processes tasks from the queue and moves on. That leaves out the most useful part. Workers often carry the system’s real operating rules.
They may throttle activity, lock resources, preserve ordering, skip duplicate work, detect stale tasks, or shift processing paths when one dependency fails.
If your backend system does anything special at the worker level, that behavior should be described with care.
The worker is often where business goals become technical action. It is where speed, reliability, and cost control get translated into execution rules.
A worker becomes more valuable when it is selective
A worker that simply takes the next task is easy to replace. A worker that makes structured decisions can be much harder to copy.
For example, a worker may inspect job state before processing, reject tasks that would cause duplicate execution, pause work until another service reaches a required condition, or send the task to a fallback path if a related result is missing.
Those kinds of actions are often more important than the fact that a worker exists at all. Businesses should look at workers not as generic compute units but as active participants in the invention.
Explain service roles with precision
The word service is so broad that it can erase value if used carelessly. When teams say one service calls another service, they may be telling the truth but not revealing anything meaningful.
What matters is the function each service performs in the wider system and why that role was separated the way it was.
Maybe one service classifies tasks before queue entry. Maybe another verifies policy conditions before execution.
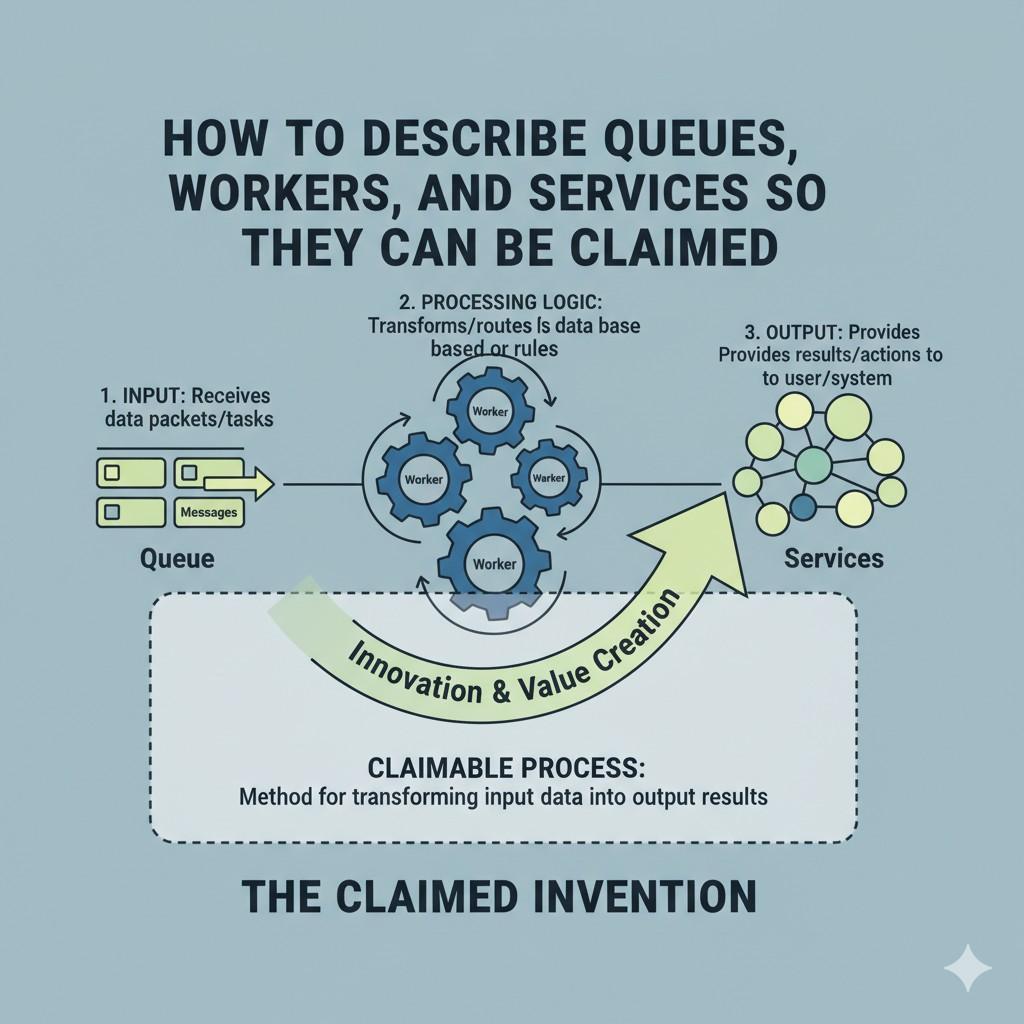
Maybe another maintains a durable state record so retried jobs do not repeat completed actions. Maybe another assembles partial outputs into a final result while preserving order.
Each role should be explained in a way that shows necessity, not just existence.
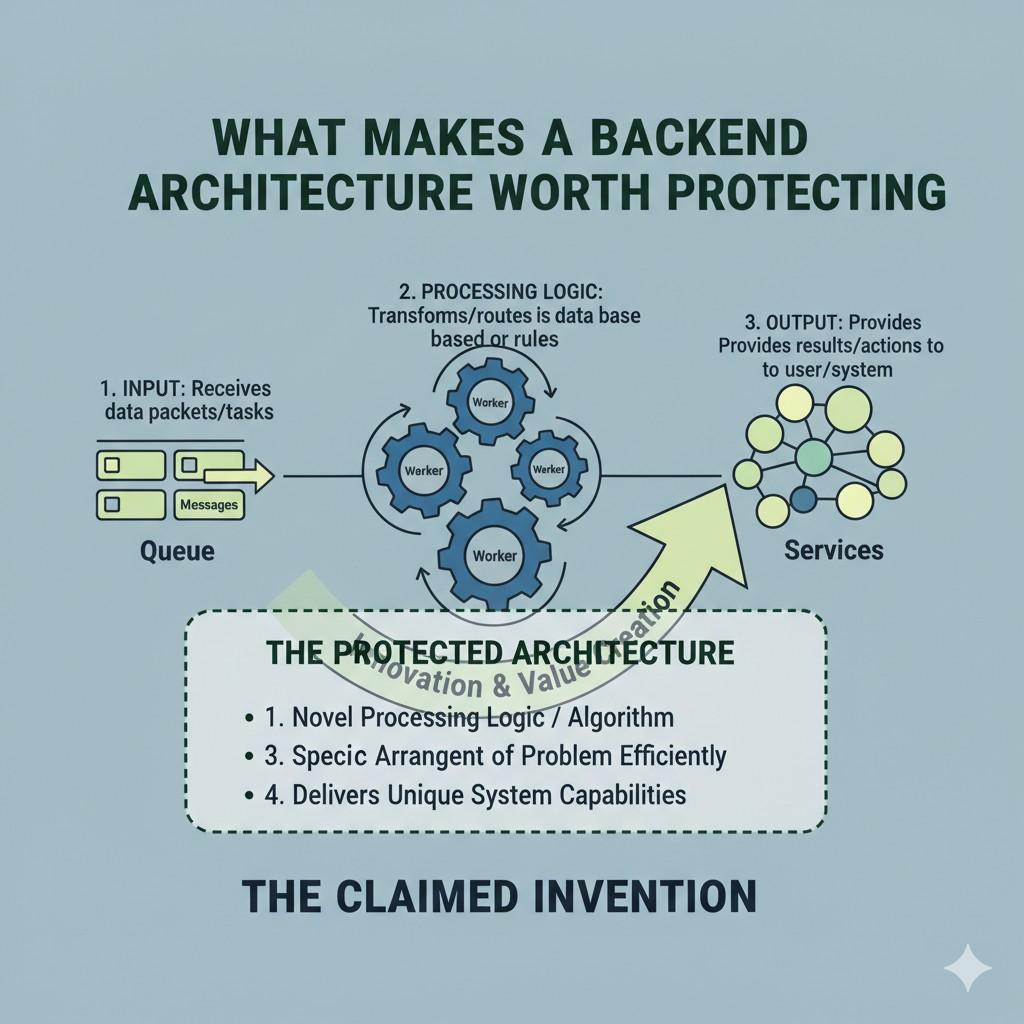
What Makes a Backend Architecture Worth Protecting
Not every backend setup is worth protecting. Some systems are useful but ordinary. Others quietly hold the real edge of the business.
The difference usually comes down to whether the architecture does something in a distinct way that solves a real technical problem and creates a business result that matters.
A backend becomes worth protecting when it is more than a standard assembly of known tools. It needs to reflect design choices that are hard-earned, specific, and meaningful.
For a business, this question is not academic. It shapes where to spend time, what to document, and how to build a real moat around the product.
When founders understand what makes a backend architecture worth protecting, they stop treating core system design like invisible plumbing and start treating it like strategic property.
It solves a real technical problem, not just a business wish
A backend architecture becomes more important when it addresses a real system issue instead of only reflecting a broad business goal. Saying the company wanted better scale or faster growth is not enough on its own.
What matters is the concrete technical challenge the team had to overcome to make that happen.
The best protection opportunities often come from systems built under pressure. Maybe jobs were arriving in bursts and a simple flow could not keep up. Maybe ordering mattered and tasks could not be processed out of sequence. Maybe shared state kept breaking during retries.
Maybe service failures caused chain reactions. When the architecture was designed to solve one of those hard problems in a real way, it starts to look like something worth protecting.
Pain usually points to value
A useful signal is this: if the team had to think deeply, test multiple approaches, and build around repeated failure, there may be something valuable there.
Systems that were easy to put together are less likely to be where the company’s edge lives. Systems that took serious engineering judgment often deserve a second look.
For businesses, that means reviewing moments of friction, not just moments of success. The hard parts often reveal the architecture choices that competitors will struggle to match.
It creates a result that standard setups do not create
A backend does not become protectable just because it uses queues, workers, and services.
Lots of systems use those parts. What matters is whether the company’s arrangement of those parts produces a result that standard approaches do not produce, or do not produce as well.
That result might be lower processing delay under uneven load. It might be cleaner failure recovery without duplicated work. It might be safe parallel execution while preserving order.
It might be lower compute spend at scale. It might be better handling of priority classes without starving lower-level work forever. The key is that the result comes from the architecture itself, not from luck or brute-force infrastructure spending.
A better outcome is the clearest sign
A business should ask a simple question here. What does this backend allow us to do better than a normal implementation? If there is no strong answer, the system may not be where the deepest value sits.
If the answer is clear and tied to a real outcome, that is often the starting point of a strong protection story.
This is also useful internally because it forces the team to connect engineering choices to business value. That makes the architecture easier to explain, easier to defend, and easier to prioritize.
It reflects deliberate design, not accidental growth
Some backend systems become complex only because the company kept adding pieces over time. That kind of complexity does not always create protectable value.
A messy stack can be hard to copy simply because it is messy, but that is not the same as being strategically worth protecting.
The backend architectures that matter most are usually shaped by deliberate choices. The team knew what problem it was solving. It selected certain control points, handoff rules, task states, retry behavior, and service boundaries for a reason. That reason shows design intent.
Design intent is often what separates a strong system from a pile of technical debt.
Clean reasons matter more than crowded diagrams
A crowded architecture diagram can look impressive while saying very little. A much better sign is when engineers can explain, in plain words, why the system behaves the way it does.
If they can say why tasks are split, why certain work is delayed, why one service owns state, or why retries happen only after certain checks, then the architecture likely contains intentional logic worth studying.
For businesses, this matters because intention is easier to document and easier to turn into protection than accidental complexity.
It handles edge cases in a smart and repeatable way
A lot of backend value shows up at the edges, not in the normal path. Standard systems often look fine when everything works. The real difference appears when things get messy.
A backend architecture is much more likely to be worth protecting if it deals with ugly cases in a controlled and useful way.
That could mean handling duplicate events without double execution. It could mean restarting incomplete flows without redoing finished work. It could mean switching processing routes based on dependency health.
It could mean preserving order across retries. It could mean giving urgent jobs faster treatment without breaking fairness or draining the whole system.
Special handling often hides the strongest insight
Many teams talk about edge-case logic as if it is just cleanup. In reality, that is often. Those rules are usually born from direct contact with production problems.
They reflect the team’s deeper understanding of what breaks and how to keep the product stable under pressure.
Businesses should pay close attention to these patterns. If the system handles failure, delay, conflict, or inconsistency in a way that feels hard-won, it may be one of the most valuable parts of the backend.
It would be hard for a smart competitor to rebuild well
One of the most practical tests is competitive difficulty. If a capable team could rebuild the same backend behavior quickly with standard patterns, the architecture may be useful but not highly strategic.
If the system would be difficult to reproduce without learning the same hard lessons, then it may be worth protecting.
That difficulty often does not come from obscure tooling. It comes from the operational logic. It comes from knowing how to classify work, when to hold state, how to avoid repeat processing, how to recover from partial failure, and how to balance throughput with control. Those things often look simple after they are solved, but they are not simple to discover.
Hard to rebuild often means hard to replace
This matters for both patents and business positioning. A backend that is hard to rebuild can support stronger defensibility.
It can also support stronger customer trust because the performance people experience is tied to deeper system know-how, not surface design.
A useful internal question is this: if a competitor copied our visible product tomorrow, what backend behavior would they still struggle to match for the next year? The answer often points straight at what is worth protecting.
It supports the company’s business model, not just one feature
A backend architecture becomes more strategic when it powers more than one isolated feature.
If the same backend pattern supports multiple workflows, product lines, or customer promises, then its business importance rises. That often makes it more worth protecting.
For example, one task-routing model might support onboarding, reporting, alerts, scoring, and audit flows. One retry-state design might protect many different job types from duplicate execution.
One service arrangement might allow the company to offer fast results across several use cases. In those cases, the backend is not a side mechanism. It is part of the operating foundation of the company.
Shared patterns create stronger leverage
When one backend approach supports many parts of the business, protecting it can create wider coverage.
It also means the value of documenting it goes up. The company is not just preserving one narrow technical solution. It is preserving a repeatable system idea that helps the whole product move.
Businesses should watch for backend patterns that keep showing up across teams and features. Reuse is often a sign that the system is more important than it first appears.
It improves speed, trust, cost, or control in a concrete way
A backend architecture is much easier to defend as valuable when it connects to one of four things businesses care about deeply: speed, trust, cost, or control. These are the practical outcomes that shape product strength and market position.
If the architecture helps users get results faster, that matters. If it helps the system behave reliably when failures happen, that matters. If it lowers cost to serve, that matters.
If it gives the company more control over processing rules, policy enforcement, or system state, that matters too. These are not abstract benefits. They are business levers.
Backend value should be explained in outcome language
A smart company does not stop at describing the architecture. It explains what the architecture changes. That makes the system easier to understand both internally and externally.
It also helps decide whether the backend is central enough to deserve protection work.
When a founder can clearly say, “This routing design lets us keep urgent tasks fast without letting the system flood,” or, “This state-handling model lets us retry safely without duplicating completed work,” the value becomes easier to see and much harder to dismiss.
It depends on system behavior, not just a tool choice
Choosing a certain queueing tool or cloud provider rarely makes an architecture worth protecting by itself.
Tool choices can matter in practice, but they are usually not where the company’s unique value lives. The deeper value tends to sit in the system behavior built on top of the tools.
That includes how tasks are formed, what metadata is attached, how workers decide what to do, how state is tracked, how services coordinate, and how the system responds under changing conditions.
Those behaviors can remain valuable even if the underlying tools change later.
Behavior travels better than stack details
This is an important point for businesses because tools change fast. If the company defines its backend value only by a current stack, that value may feel dated or narrow over time.
If it defines the value by the logic and behavior of the system, it has a much stronger foundation.
A practical way to test this is simple. Ask whether the core advantage would still exist if the team rebuilt the same architecture on another platform. If the answer is yes, the real value likely sits in the design logic, which is exactly where attention should go.
It includes a clear flow of state and control
Strong backend architectures usually have a clear answer to two questions. Where does the system store state, and how does control move from one stage to the next? If the architecture answers those questions in a thoughtful way, it may be doing something worth protecting.
State and control are where many backend systems either become powerful or become fragile.
If the team found a better way to track progress, preserve context, avoid repeated actions, or shift control based on changing conditions, that can be highly valuable. These are the hidden mechanics that make the system dependable.
Strong state design often separates serious systems from weak ones
A backend that remembers the right things at the right time is usually more resilient and more efficient.
That can create a serious business edge. It can also create a strong protection story because state handling is often tied directly to system behavior and technical results.
Businesses should not gloss over this part.
They should study how state enters the system, where it is updated, who reads it, and how it influences later execution. That review often reveals some of the most important architecture choices.
Wrapping It Up
Backend systems are often where the real value lives. Not in the button. Not in the page. Not in the part a customer sees first. The real edge is often in how work moves through the system. It is in how jobs are queued, how workers make decisions, how services coordinate, and how the whole backend keeps running when things get busy, messy, or unpredictable.
Leave a Reply